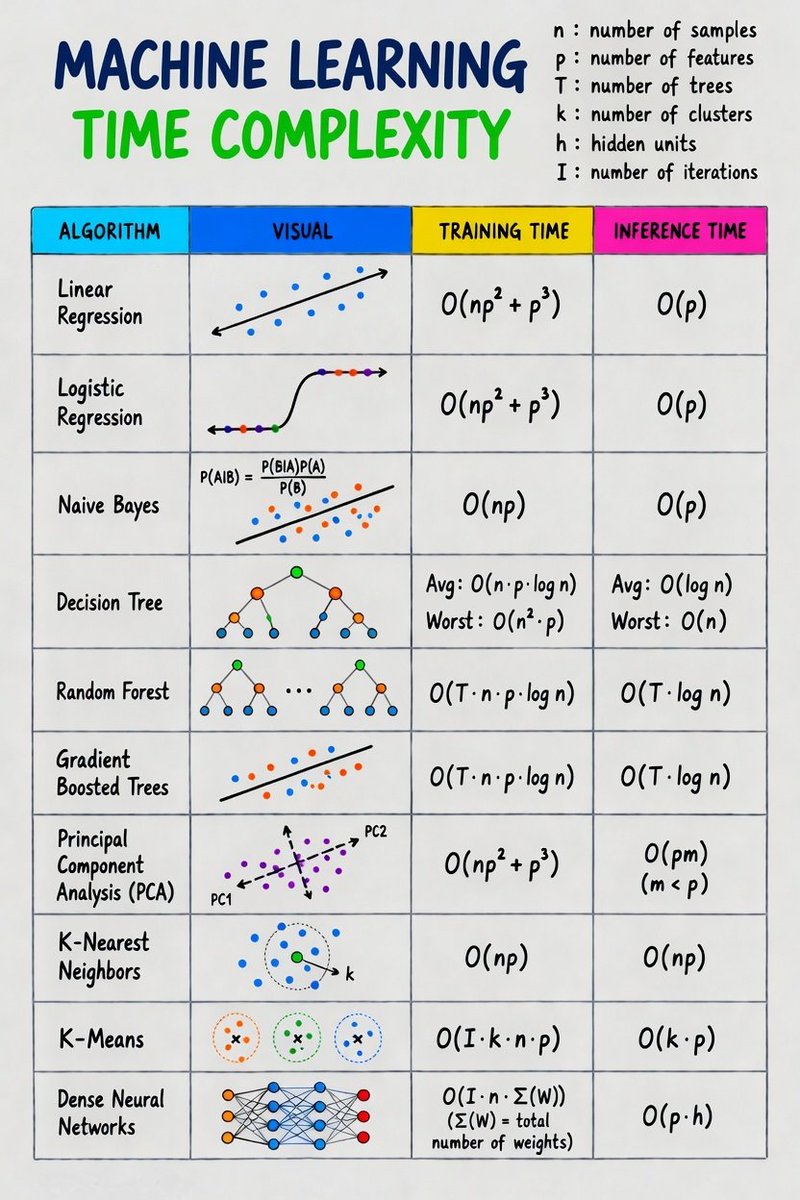
TinyFish just open-sourced BigSet — a multi-agent system that builds structured datasets from a single plain-English sentence.
You type: "YC companies that are currently hiring engineers, with their funding stage, location, and number of open roles."
That's the input. That's it.
Here's what actually happens under the hood:
1. Schema Inference (Claude Sonnet via OpenRouter)
- Infers column names, data types, and primary keys before any web access
2. Orchestrator Agent (Qwen via OpenRouter)
- Runs broad discovery via TinyFish Search to identify which entities exist and where to find them
3. Sub-Agent Fan-Out
- One isolated sub-agent per entity, running in parallel
- Each agent is capped at 6 tool calls — fetch, search, insert, done
- Dataset ID is baked into a JS closure invisible to the LLM — prompt injection can't redirect writes
4. Export
- Primary key deduplication across all agents
- Source attribution per row
- Download as CSV or XLSX
The refresh part is what makes it useful long-term. Set it to 30 min, 6 hours, daily, or weekly — the agents re-run automatically. Your dataset stays current without re-running anything manually.
I have personally tested BigSet and covered the full setup walkthrough — clone to first dataset — including all env vars, make commands, and the security architecture.
Here is the full analysis: https://t.co/lJMVFngeuL
GitHub: https://t.co/8dL7kQdsyc
@Tiny_Fish #ai #aiagent #dataset
MiniMax just released MiniMax M3 — and the architecture change alone is worth paying attention to.
The most important element in it is MSA (MiniMax Sparse Attention). At 1 million tokens of context, M3's per-token compute is 1/20th of the previous generation. That's more than 9× faster prefill and more than 15× faster decoding at that context length. This is a meaningful infrastructure shift for devs running full-codebase agents or long-document pipelines
Here's what's actually interesting about MiniMax M3:
1. Native multimodality from step 0 → Text, image, and video trained together from the start — not added post-training → Training data scaled to the order of 100 trillion tokens using interleaved formats → Supports image input, video input, and desktop computer operation
2. Coding benchmarks → 59.0% on SWE-Bench Pro (surpasses GPT-5.5 and Gemini 3.1 Pro) → 66.0% on Terminal-Bench 2.1 → 74.2% on MCP Atlas → 70.06% on OSWorld-Verified for computer use
3. Long-horizon autonomous iteration → M3 optimized an FP8 GEMM kernel on NVIDIA Hopper GPUs over 24 hours → 147 benchmark submissions, 1,959 tool calls, zero human intervention → Improved Hopper FP8 peak utilization from 7.6% to 71.3% — a 9.4× speedup
4. Access → API is live today at https://t.co/lrrwMPgq6B → Open weights and technical report committed within 10 days → Token Plan starts at $20/month (~1.7B M3 tokens)
One thing to closely watch: PostTrainBench — the task of autonomously training models from scratch — scored 0.37, below Opus 4.7 (0.42) and GPT-5.5 (0.39). Worth keeping in context when evaluating M3 for ML research automation specifically.
I covered the full technical breakdown: https://t.co/yxLeIRjK6T
Details: https://t.co/ephFkY2Ec5
@MiniMax_AI
Perplexity AI just open-sourced a rewritten Unigram tokenizer that cut CPU utilization 5-6x in production.
Here's what's actually interesting:
1. The problem wasn't the model
For small models like rerankers and embedders, GPU compute finishes in single-digit milliseconds. The CPU tokenization running before it was the bottleneck — and it didn't show up in GPU profiling traces.
2. The reference implementation had three costly patterns
→ 7,295 heap allocations per encode at 514 tokens (299,171 at 16K)
→ HashMap at every trie node: 4 dependent loads per byte step
→ L2 miss rate climbing from 8% to 50% at longer inputs
3. They fixed allocations before touching the trie**
A zero-allocation port of the same HashMap trie dropped p50 from 326 µs to 155 µs. No trie change yet. Allocations alone were the dominant cost.
4. Three optimizations drove the final result**
→ Double-array trie: 2 array reads + 1 add per byte step instead of 4 dependent loads
→ Bitmap + 64-byte cache-line packing: one cache-line load per trie step, L2 accesses dropped from 4,600 to 1,800
→ 2 MB huge pages: 50 MB trie spans 25 pages vs 12,000, fits in TLB entirely
5. Final numbers at 514 tokens (Intel Xeon Platinum 8488C)
→ Hugging Face tokenizers crate: 349 µs, 7,295 allocations
→ SentencePiece (C++): 128 µs
→ IREE (C): 112 µs
→ Perplexity final: ~63 µs, 0 allocations
Instructions per encode: 3.66M down to 1.04M (3.5x reduction).
Read the full analysis: https://t.co/Dr2v6OVHML
@perplexity_ai
Perplexity just open-sourced an internal security tool they've been running in production.
It's called 'Bumblebee'. Here's what's actually interesting:
1. It solves a specific blind spot SBOMs cover build artifacts. EDR covers running processes. Neither tells you what's installed on a developer's laptop right now. Bumblebee does exactly that — and nothing more.
2. The read-only design is the key decision npm packages can carry postinstall scripts that execute automatically on install. Most recent supply-chain worms spread that way. A scanner that invokes npm to check exposure has already triggered the attack. Bumblebee reads metadata directly — lockfiles, manifests, extension manifests — and never runs any code.
3. Four surfaces in one scan → Language package managers: npm, pnpm, Yarn, Bun, PyPI, Go modules, RubyGems, Composer → AI agent configs: MCP JSON host files including claude_desktop_config.json and cline_mcp_settings.json → Editor extensions: VS Code, Cursor, Windsurf, VSCodium → Browser extensions: Chrome, Edge, Brave, Arc, Comet, Firefox
4. The internal workflow is worth noting Perplexity Computer drafts a catalog entry when a threat signal lands → human reviews and merges the PR → Bumblebee runs on endpoints → findings go to the security team. Human in the loop before anything hits machines.
5. Technical details → Written in Go 1.25+, zero non-stdlib dependencies → Single static binary, three scan profiles: baseline, project, deep → Outputs NDJSON records with confidence levels (high / medium / low) → Apache 2.0, current release v0.1.1
Full analysis: https://t.co/6mu5RoSdRl
Repo: https://t.co/sYLCVrrala
Technical details: https://t.co/CfTmCfoD4g.
@perplexity_ai
How CopilotKit Is Redefining the Agentic AI Stack in 2026
For years, AI inside software meant a chat widget bolted onto the corner of an application. You typed, the model responded with text, and you manually translated that output into whatever you actually needed it to do. It was useful the way a calculator is useful: functional, but fundamentally passive. CopilotKit, a Seattle-based startup co-founded by Atai Barkai and Uli Barkai, has spent the last two years arguing that the model is broken — and in 2026, the developer community is agreeing loudly.
- AG-UI completes the agentic protocol stack by handling the agent-to-UI interaction layer that MCP and A2A leave unaddressed, with first-party SDKs across LangGraph, CrewAI, Mastra, Agno, and Pydantic AI, and community SDKs now live for Go, Kotlin, Dart, Java, Rust, Ruby, and C++.
- AIMock ships one zero-dependency mock server for the entire agentic call chain — 11 LLM providers, MCP, A2A, vector DBs, search — with record-and-replay, daily drift detection, and chaos testing built in.
- Pathfinder is a self-hosted MCP knowledge server that indexes docs, code, Notion pages, Slack, and Discord into hybrid vector-keyword search, with pluggable embeddings that need no external API key.
- The three tools together target the three production blockers — knowledge retrieval, testing reliability, and runtime persistence — that demo-quality agents consistently fail to address.
- CopilotKit's vendor-neutral, self-hostable design means teams can adopt any single layer without being locked into a proprietary runtime or forced to rebuild their existing stack.
Full analysis: https://t.co/eOxovDdjtW
GitHub repo: https://t.co/YDv9rhIu4T
@CopilotKit #ai #aiagent #agenticai
Most agent frameworks today are stitching together reasoning models with external orchestration layers. Qwen3.7-Max takes a different position — train the agent capability into the model itself.
Alibaba just introduced Qwen3.7-Max
Here's what's actually interesting:
→ 1M-token context window — up from 256K on Qwen3.6 Max Preview
→ Extended-thinking mode with visible chain-of-thought reasoning trace
→ 1,000+ tool calls executed autonomously in an internal kernel optimization test
→ 35 hours of sustained autonomous execution on a single complex task
→ 56.6 on the Artificial Analysis Intelligence Index — #5 overall, ahead of Gemini 3.5 Flash
→ #13 in Text Arena (1,475 Elo), #7 in Math, #9 in Expert Prompts
Full analysis: https://t.co/qSLp3fta9c
Other technical details ⤵
@Alibaba_Qwen
Most vector search libraries make you train a codebook before indexing anything.
That's not a search tool — it's a data dependency. turbovec just removed it entirely.
It's a Rust-built vector index with Python bindings, built on Google Research's TurboQuant algorithm — a data-oblivious quantizer that requires zero training and zero data passes.
Here's what's actually interesting:
→ 10 million documents: 31 GB as float32, 4 GB with turbovec — 16x compression at 2-bit
→ Beats FAISS IndexPQFastScan by 12–20% on ARM across every configuration
→ On x86, wins every 4-bit config by 1–6% against FAISS
→ Zero codebook training — add vectors, they're indexed immediately
→ Fully local, no data egress — drop-in for LangChain, LlamaIndex, and Haystack
The core idea: after applying a random rotation, every coordinate follows a known Beta distribution — regardless of input data. That makes the quantization boundaries computable from math alone, not from your dataset.
Full analysis with Guide: https://t.co/RcUvsavLvi
Repo: https://t.co/dmcGErIfbT
#ai #python #aiinfrastructure #data #ml
Most LLM inference optimization forces a choice: fast drafting with a weak auxiliary model, or accurate generation with full Standard autoregressive (AR) decoding. NVIDIA Researchers just built a third option into the weights themselves.
They released Nemotron-Labs-Diffusion — a 3B/8B/14B model family trained on a joint Autoregressive AR-diffusion objective that supports three decoding modes from one checkpoint: standard AR, parallel diffusion decoding, and self-speculation, where the same model drafts and verifies without any auxiliary head.
Here's what's actually interesting:
→ Self-speculation achieves 5.99× tokens per forward over Qwen3-8B with comparable accuracy on a 10-task benchmark
→ Average acceptance length: 6.82 (with LoRA) vs. 2.75 for Eagle3 and 4.24 for Qwen3-9B-MTP — same draft length of 31
→ AR and diffusion objectives peak at the same loss coefficient (α=0.3) and improve together — they don't compete for model capacity
→ Speed-of-light analysis shows a theoretical ceiling of 7.60× TPF at block length 32; current confidence-based sampling realizes only ~3×, leaving headroom for better samplers
Full analysis: https://t.co/tJdGfHjCFr
Paper: https://t.co/LdEz01hEQt
Model weights: https://t.co/eP2MJs1GT8
Technical details: https://t.co/TQ84fmKFP5
@PavloMolchanov@NVIDIAAI@nvidia@YongganFu@xieenze_jr@MardaniMorteza@songhan_mit@jankautz
Most translation models are audio pipelines with a TTS layer bolted on at the end. That's not simultaneous interpretation and Alibaba's Qwen team just built a clear technical case for the difference.
They released Qwen3.5-LiveTranslate-Flash: a real-time multimodal translation model that processes audio and video frames simultaneously, clones the original speaker's voice in the output, and covers 60 input languages at 2.8 seconds of latency.
No turn-detection. No generic synthesis voice replacing the speaker.
Here's what's actually interesting:
→ Vision-enhanced comprehension reads lip movements, gestures, and on-screen text alongside audio — robust in noisy or degraded audio environments
→ Semantic unit prediction via "reading units" processing commits to output segments mid-sentence, enabling continuous streaming without waiting for full utterances
→ Real-time voice cloning replicates the original speaker's voice profile from a single spoken sentence
→ Dynamic keyword configuration lets you inject domain-specific glossaries at runtime — brand names, medical terms, legal vocabulary
→ FLEURS and CoVoST2 benchmarks: outperforms major commercial alternatives across multilingual speech translation tasks
Full analysis: https://t.co/gVorchcSuU
Technical details: https://t.co/R3QQurGlB9
@Alibaba_Qwen #tts #audioai #voiceai #ai @Ali_TongyiLab
Most "privacy-preserving" AI memory just masks sensitive values with ***. That breaks the task. The cloud can't draft your doctor's email if the blood pressure reading is gone.
MemTensor just proposed a different approach — and it actually holds up under benchmarking.
They introduced MemPrivacy, a framework that runs a lightweight on-device model to detect private spans, replaces them with semantically typed placeholders like <Health_Info_1> before anything leaves the device, and restores the original values locally after the cloud responds. The cloud reasons on structure. It never sees the actual data.
Here's what's actually interesting:
→ Four-level privacy taxonomy (PL1–PL4) from general preferences to immediately exploitable credentials — user-configurable per session
→ MemPrivacy-4B-RL hits 85.97% F1 on MemPrivacy-Bench vs. 78.41% for Gemini-3.1-Pro and 68.99% for GPT-5.2 on privacy span extraction
→ Utility loss across LangMem, Mem0, and Memobase stays within 1.6% at PL2–PL4 protection — irreversible masking causes drops up to 41.87%
→ Models run at 0.6B, 1.7B, and 4B parameters with sub-2-second per-message latency on-device
The core insight: privacy protection and semantic utility don't have to trade off — if you replace values with typed structure instead of blank masks.
Full analysis: https://t.co/Zn62GYvv7G
Paper: https://t.co/Y2NEV8Mam6
Model Weights: https://t.co/VC3Rn6Iap7
@ModelScope2022 #ai #data #privacy #model #llm