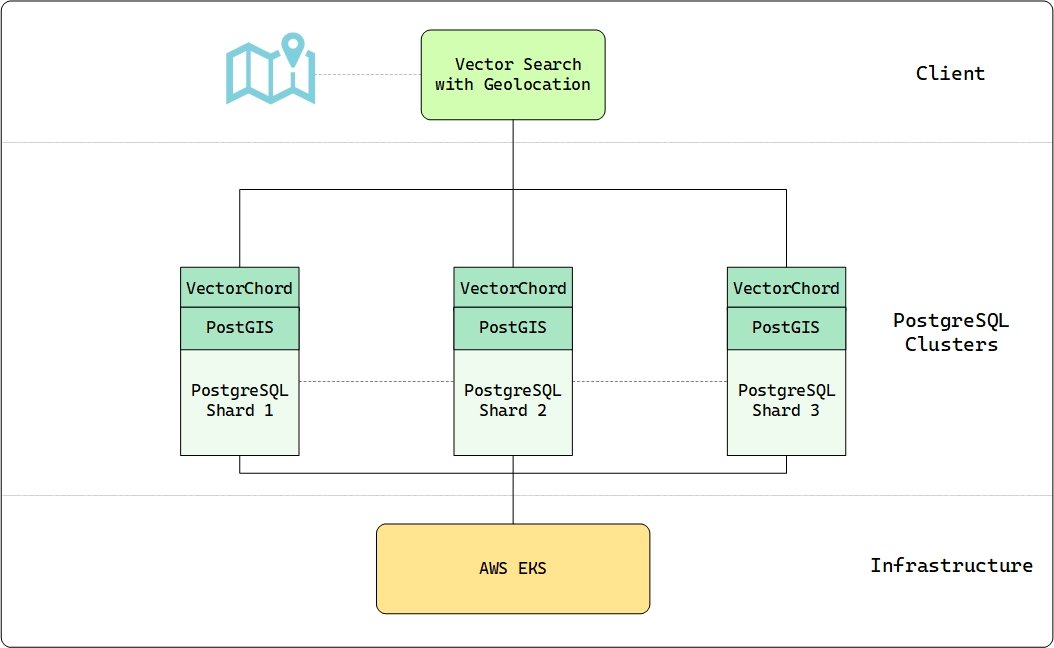
With the 0.4.11 release, Hindsight now supports VectorChord (vchord) from @TensorChord, a high-performance, open-source PostgreSQL extension for similarity search
Building Earth Index as a searchable planet has always been ambitious & we've made sure to use the right tools to make this a reality. We're happy to use @TensorChord's PostgreSQL extension to enable environmental action at this scale.
Read more here➡️https://t.co/E9FuajAAFG
🎉 10M Docker Pulls for https://t.co/awoObqYEQK! 🚀
We’re thrilled to celebrate this incredible milestone for https://t.co/awoObqYEQK!
But the journey doesn’t stop here! Meet https://t.co/J9AAaiqq06, its successor, offering affordable disk-based PG vector search!
#PostgreSQL
HNSW is popular but has major drawbacks, like high memory use and complex updates. Disk-based solutions like IVF, especially with RabitQ, offer better scalability and efficiency. It's time to consider simpler alternatives! #VectorDatabases#HNSW#IVF
https://t.co/gcSOBmDAjP
Explore the counterintuitive insights behind the performant RaBitQ algorithm for binary and scalar quantization in vector databases!
https://t.co/tnHKmlXqEa
#RAG#vectorsearch#vectordatabase#rabitq
> First, we’re introducing explicit functions that treat external object storage locations as first-class data citizens. Second, we’re integrating the ability to run LLMs directly within the Postgres platform.
Interview with my senior coworker, Torsten.
https://t.co/4FCUrmSeGs
We are thrilled to announce the release of our Terraform provider for https://t.co/WhoqjU0dAf Cloud. This new provider is designed to simplify the process of managing resources on our cloud service
https://t.co/m7x7rlMVS5
We're excited to announce the release of pg_bestmatch.rs, a PostgreSQL extension that brings the power of Best Matching 25 Score (BM25) text queries to your database, enhancing your ability to perform efficient and accurate text retrieval. https://t.co/nJUfZxZRIN
@mattshumer_ I ended up writing it out myself using @modal_labs for getting embeddings, and @qdrant_engine for vectors, then realised I need lots of filtering and switched to https://t.co/BHKJw3zTIf
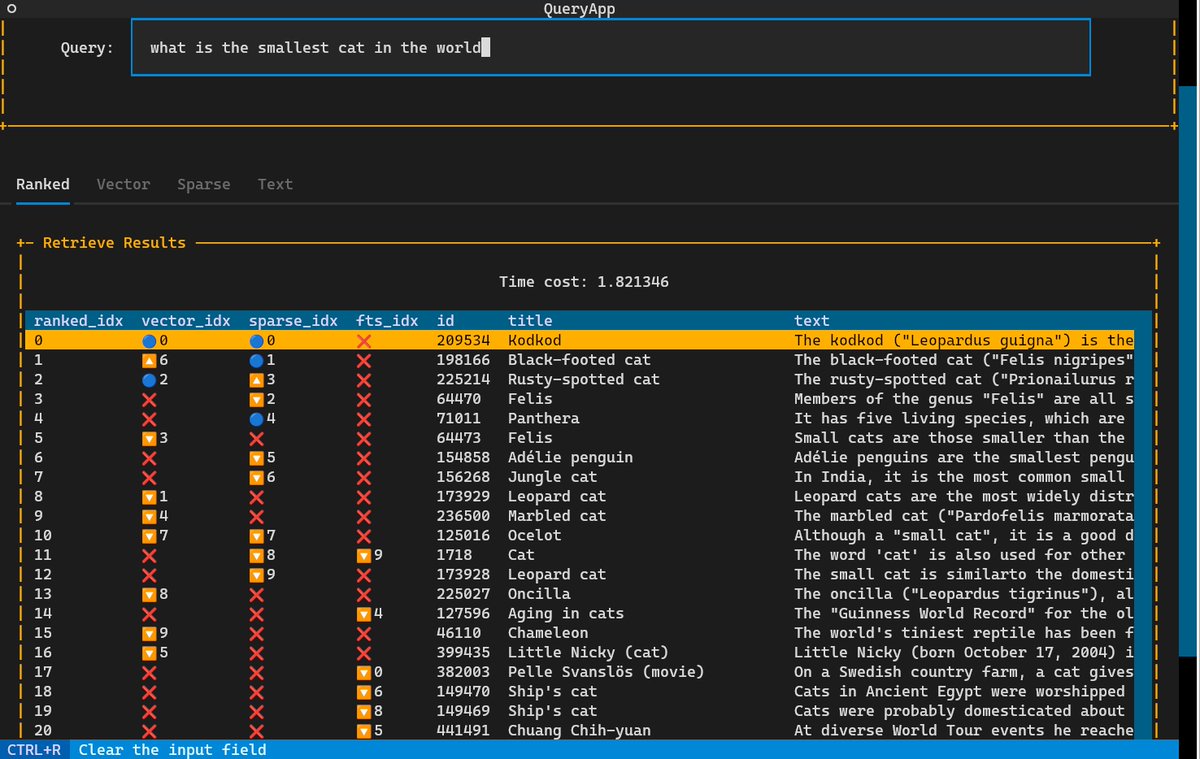
The results are conveniently visualized in the terminal using @textualizeio. The reranking step has dramatically improved quality of the top-k candidates. You can try different queries to see which retrieval method suit your requirements better.
There’s thousands of RAG techniques and tutorials, but which ones perform the best?
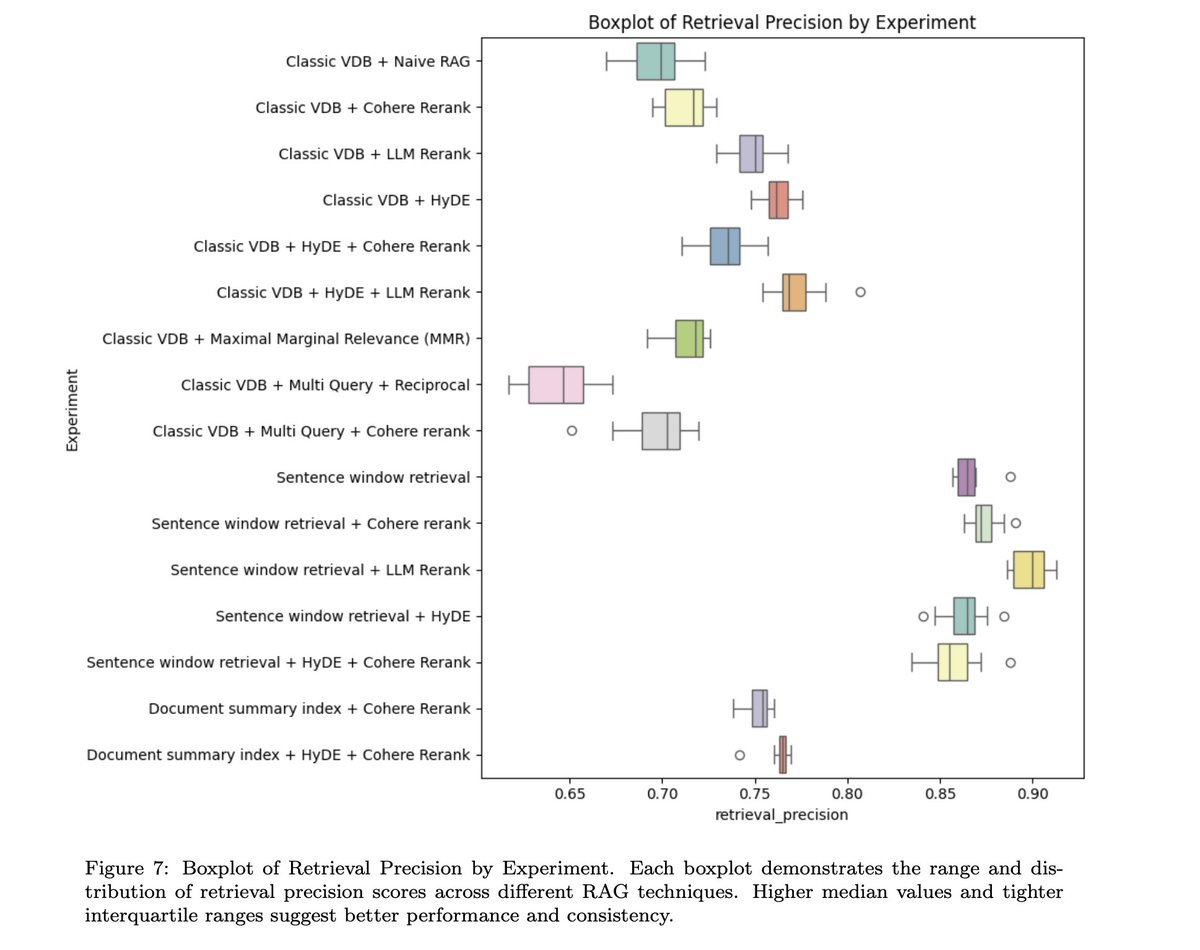
ARAGOG by Matous Eibich is one of the most comprehensive evaluation surveys on advanced RAG techniques, testing everything from “classic vector database” to reranking (@cohere, LLM) to MMR to @llama_index native advanced techniques (sentence window retrieval, document summary index).
The findings 💡:
✅ HyDE and LLM reranking enhance retrieval precision
⚠️ MMR and multi-query techniques didn’t seem to be as effective
✅ Sentence window retrieval, Auto-merging retrieval, and the document summary index (all native @llama_index techniques) offer promising benefits in either retrieval precision and answer similarity! (And also interesting tradeoffs).
It’s definitely worth giving the full paper a skim. Check it out: https://t.co/GXxjLZtYPb
TIL about binary vector search... apparently there's a trick where you can take an embedding vector like [0.0051, 0.017, -0.0186, -0.0185...] and turn that into a binary vector just reflecting if each value is > 0 - so [1, 1, -1, -1, ...] and still get useful cosine similarities!
It is important to note that this is closely tied to the embedding model being used. The benchmark we conducted specifically focused on OpenAI's text-embedding-3-large model.
Maybe some binary embedding models have better performance. e.g. @cohere@JinaAI_
TIL about binary vector search... apparently there's a trick where you can take an embedding vector like [0.0051, 0.017, -0.0186, -0.0185...] and turn that into a binary vector just reflecting if each value is > 0 - so [1, 1, -1, -1, ...] and still get useful cosine similarities!
After conducting a thorough benchmarking process using @qdrant_engine's dataset, we have discovered fascinating insights regarding the superiority of binary vectors and shortened vectors.
https://t.co/ECpGBmt4L4