Excited to share that I’ve joined @withprotegeai as a Senior Machine Learning Researcher on the DataLab team.
After 2 years at @CleanlabAI, working with the team was an incredibly formative experience. I’m deeply grateful for the chance I had to learn from them to work on data-centric AI with such thoughtful researchers and builders, and to contribute during a period that ultimately led to Cleanlab being acquired into @joinHandshake AI. I learned a tremendous amount about the importance of data quality, evaluation, and trustworthiness in modern AI systems to make them more accurate and reliable.
Throughout my time there, my conviction only grew that the next major advances in AI will come not just from better models or more compute, but from better data.
At DataLab, our goal is to treat the data layer of AI with the same scientific rigor that model labs apply to algorithms by building a dedicated research institution for AI data: designing high-fidelity datasets and multimodal benchmarks grounded in real-world scenarios, working closely with frontier labs on their hardest data challenges, and developing standardized ways, including “FICO scores for AI data”, to measure dataset quality, contamination, and benchmark reliability.
Another important piece of this work is understanding how different kinds of data support different parts of the AI training stack. Reinforcement learning (RL) environments are a powerful form of training data that generate structured training tuples like (state, action, reward, next state) and are extremely useful for post-training optimization when the world can be simulated. But many of the highest-value domains for AI, including healthcare, enterprise workflows, and complex multimodal reasoning, cannot be faithfully simulated. Advancing models in these areas requires real-world datasets, carefully designed benchmarks, and domain-specific data for pre-training and mid-training adaptation.
The idea behind DataLab is simple but important: every major leap in AI capability has historically followed a breakthrough in data (from ImageNet to large-scale web corpora). As models and compute continue to advance rapidly, closing the data gap, the gap between the data that AI systems need and the data that actually exists in usable form, may be one of the most important challenges for the field.
Here is more info on some of the work the team has done so far: https://t.co/fzgkgOPL7b
We're excited to see @DataLabResearch@TurkMatthew’s new paper, “Counterfactual Evaluation Reveals Hidden Capability Profiles in Clinical LLMs and Agents,” accepted to the inaugural RLEval Workshop at ACM CAIS 2026 and selected for an invited talk.
🔍️ The guiding research question: "When clinically important patient facts change, does the model appropriately change its recommendations?"
👉️ If you change a key clinical detail that changes the case context, the model should change its recommendation.
But if a clinically meaningful fact changes and the model doesn't update its recommendation, that counterfactual test exposes the gap. The model wasn't truly reasoning through the specific case in front of it — it was relying on surface patterns or the general shape of the case rather than the patient's actual circumstances.
🚨 What Matt found: "Producing the right answer and responding appropriately to new information are distinct capabilities - and future evaluation frameworks need both."
‼️ Why this matters: This connects directly to one of the hardest problems in benchmark design. It's not enough to measure whether a model arrives at the right answer. We also need to know whether it would arrive at a different answer when the underlying facts change.
This is the kind of benchmark-design question that @engyziedan's @DataLabResearch focus on. Better benchmarks require more than held-out datasets.
They require realistic, ground-truth evaluation frameworks that can distinguish between a model that genuinely updates its reasoning and one that reaches the correct answer for the wrong reasons.
Congratulations to @TurkMatthew, and we're excited about the cutting-edge benchmark and evaluation work happening across the Protege DataLab.
Excited to share that my paper, "Counterfactual Evaluation Reveals Hidden Capability Profiles in Clinical LLMs and Agents", is now available on @arxiv (link in the comments). The paper was accepted to the inaugural RLEval Workshop at @CAISconf- a workshop focused on methods and reinforcement learning environments for evaluating AI agents - and was selected for an invited talk based on reviewer ratings.
LLM evaluation is difficult. Models that look equally capable on traditional benchmarks can behave very differently when the underlying facts change.
Most current benchmarks focus on whether a model's output looks correct. But in real-world settings, especially in healthcare, what often also matters is whether the model appropriately updates its recommendations when the underlying facts change.
In this work, I introduce the Causal Sensitivity Score (CSS), a pre-registered counterfactual evaluation framework designed to measure exactly that:
"When clinically important patient facts change, does the model appropriately change its recommendations?"
Across six frontier models and several hundred oncology tumor board cases, I found that models with very similar performance on standard coverage-based metrics often behave dramatically differently under counterfactual interventions. In fact, model rankings were nearly reversed depending on whether you measured coverage or responsiveness.
The paper also shows that these findings transfer to tool-using agents, revealing failure modes that remain hidden under conventional evaluation approaches. The broader takeaway is that producing the right answer and responding appropriately to new information are distinct capabilities - and future evaluation frameworks should measure both.
This work is also closely aligned with the mission of our DataLab at @withprotegeai: building rigorous datasets, benchmarks, and evaluation frameworks that better reflect how AI systems perform in the real world. As AI moves into increasingly complex, high-stakes domains, measuring what models know is important - but we also need to measure how they respond when reality changes.
I'm grateful to my colleagues and collaborators, especially @engyziedan and Wes Hopkins, as well as the medical professionals who helped validate the results.
NYC summers hate your weekends.
I analyzed 3 years of Central Park rain data to see if the feeling was real.
It was.
27 of 38 summer weekends had measurable rain.
That’s 71%.
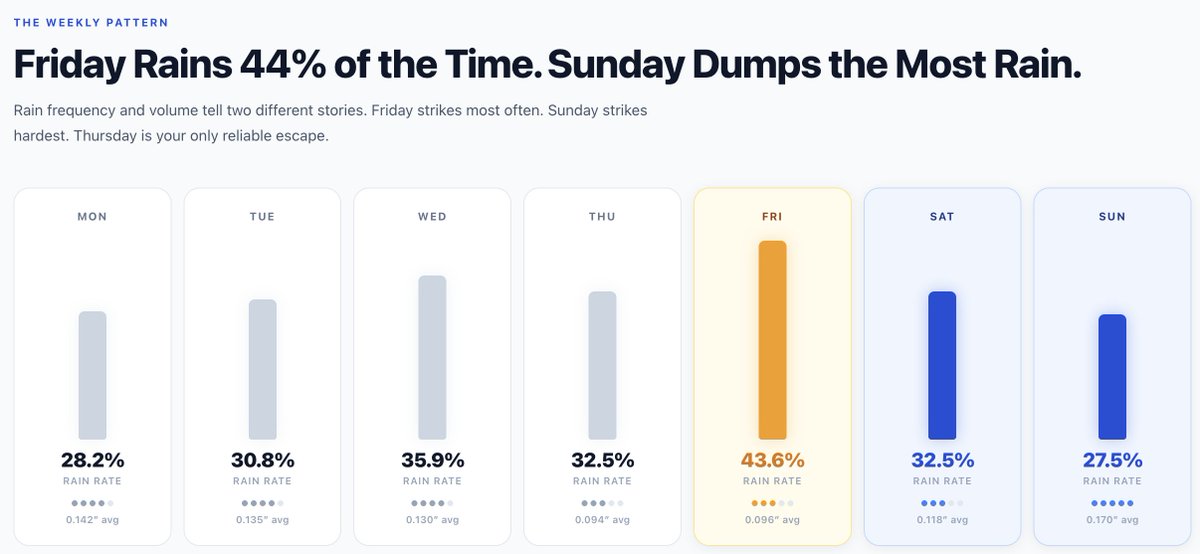
Friday was the rainiest day of the week, with rain on 43.6% of summer Fridays. Basically worse than a coin flip for your evening plans.
Sunday had the highest rainfall volume of any day, averaging 0.17 inches. It may not rain every Sunday, but when it does, it commits.
Thursday was objectively the best day to be outside in NYC: lowest precipitation, clearest skies, least weekend-related misery.
The wildest stat:
70.8% of rainy Sundays were preceded by a gross Friday or Saturday.
The weekend basically telegraphs its own downfall.
I built a full dashboard using NWS Central Park data with every weekend tracked and every raindrop counted:
Top-tier read calling out performative grind culture.
“Great work has always demanded sacrifice and often brutal hours and I'm not disputing this. What I'm disputing is the direction. These people, many of them friends, have more economic freedom than any class in history and they've chosen, freely, to simulate the conditions of a Chinese assembly line and call it virtue.”
Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
@4JimLee@bevedoni@karpathy Karpathy will not lead the business side he will do what he does best and lead R&D (specifically accelerating pre-training research)
Hey man sorry I’m busy this weekend i can’t chill
- Friday night i gotta wait in the pizza line in the west village from 6-9 and then wait on line to get into the Spaniard from 9-12
- Saturday morning gotta wait on the blank st coffee line from 8-12
-Saturday afternoon New York or nowhere line from 12-4
- Saturday night i have the frozen yogurt line from 4-12
If you wanna hang Sunday morning I’m waiting on a bagel line from 9-1 let me know