Olá, ICLR 2026 in Rio de Janeiro! 🇧🇷
Excited to present our paper, “REAP the Experts: Why Pruning Prevails for One-Shot MoE compression” this Friday from 10:30-13:00 at Pavilion 3 (P3-#701).
REAP is a one-shot MoE pruning algorithm that scales to 1T params. Details 🧵👇
📢Excited to announce the Workshop on Weight-Space Symmetries @icmlconf! We welcome 4-page submissions analysing symmetries, their effects on training and model structure, and practical methods to utilize them.
Submission Deadline: April 24 (23:59 AoE)
#ICML2026
@UCalgaryML will be at #ICML2025 in Vancouver🇨🇦 next week: our lab has 6 different works being presented by 5 students across both the main conference & 6 workshops!
We are also recruiting fully-funded ML PhD/MSc students🧑🎓If attending, reach out to me on Whova app to meet 📅
1/10 🧵
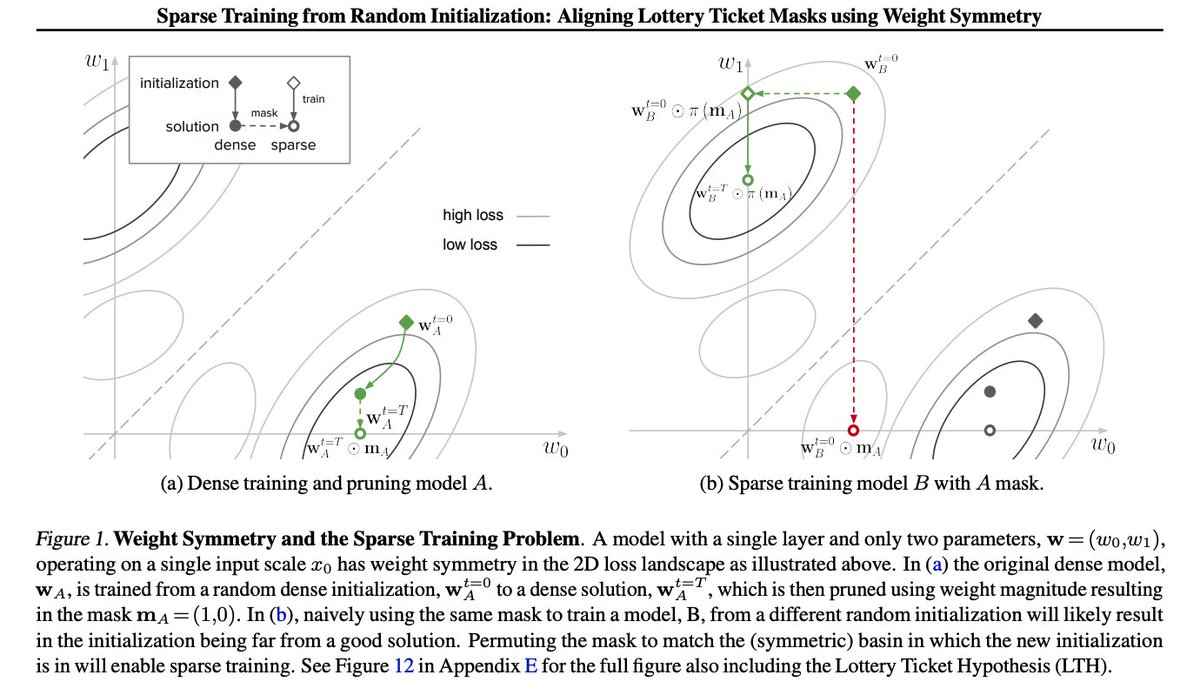
🔍Can weight symmetry provide insights into sparse training and the Lottery Ticket Hypothesis?
🧐We dive deep into this question in our latest paper, "Sparse Training from Random Initialization: Aligning Lottery Ticket Masks using Weight Symmetry", accepted at #ICML2025
I'm proud that the @UCalgaryML lab will have 6 different works being presented by 6 students across #NeurIPS2024, in workshops (@unireps, @WiMLworkshop, MusiML) and the main conference! 🎉
Hope to see you at our posters/talks 🤓, full schedule at https://t.co/qPuEHkQEZo
🧵(1/4)
Really excited to be presenting this work from my lab at the @NeurIPSConf 2024 @unireps workshop! 🎉
If you are at NeurIPS and interested in the Lottery Ticket Hypothesis/sparse training, don’t miss our poster on Sat Dec 14th, 3:45-5:00 PM 🖼️🤓
@UCalgaryML@VectorInst
Happy to share our work on Knowledge Distillation temperature🌡️ and fairness⚖️. Must-read for AI practitioners given the prevalence of distilled models! KD is crucial in deploying AI, e.g. limited hardware, real-time applications
🙏@sarahookr@mikelasby for feedback! @UCalgaryML
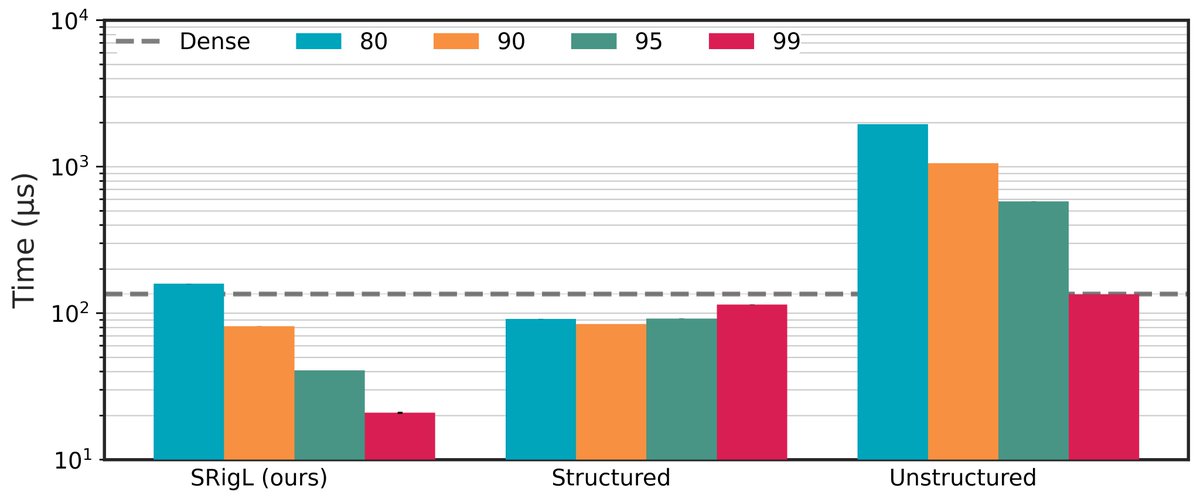
"Dynamic Sparse Training with Structured Sparsity" (https://t.co/MCxVCeMYt0) was accepted at ICLR 2024! DST methods learn state-of-the-art sparse masks, but accelerating DNNs with unstructured masks is difficult. SRigL learns structured masks, improving real-world CPU/GPU timings
I’m excited to share that I’ve received an Amazon Research Award for my proposal "Addressing Catastrophic Forgetting with Dynamic Sparse Training" at @UCalgaryML/@UCalgary!
Learn more about the program on the @AmazonScience website: https://t.co/yUQ4yL1NRQ #AmazonResearchAwards
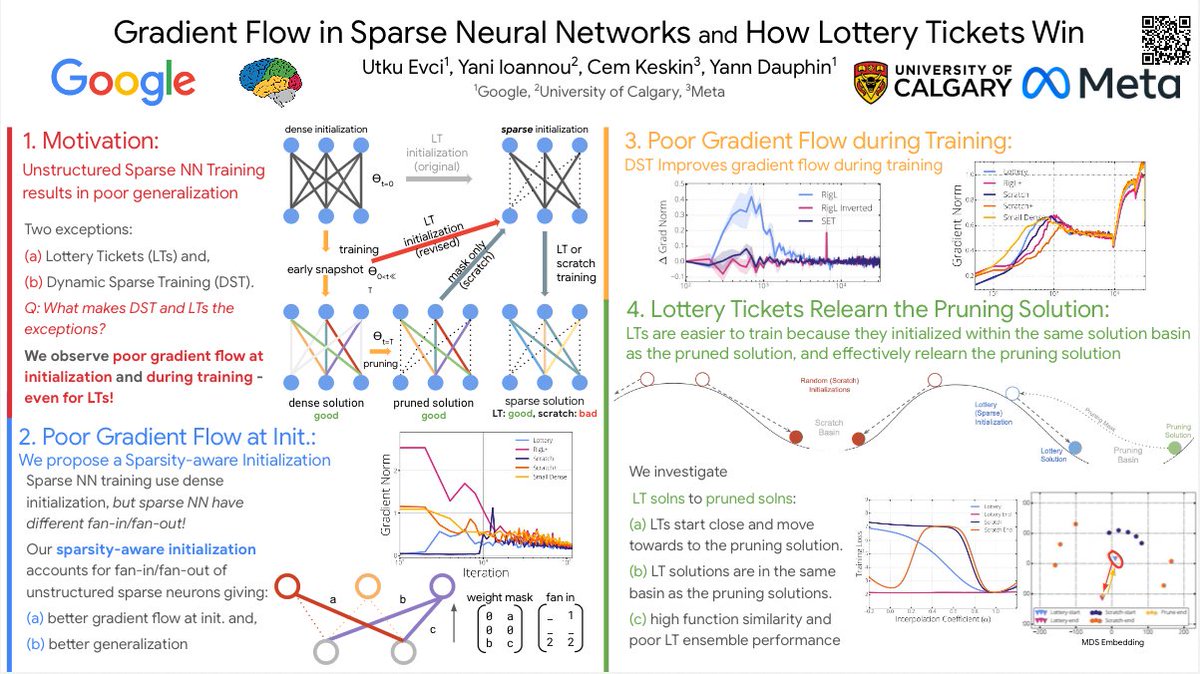
Key takeaways:
- Initialization is important for older NNs: use sparsity aware init.
- For modern NNs, init doesn't matter: improving gradient flow during training helps (i.e. RigL)
- Lottery tickets work since they re-locate the pruning solutions.
Work recently published by our close collaborators Drs. @marianapbento and @richardfrayneca!
Deep Learning in Large and Multi-Site Structural Brain MR Imaging Datasets https://t.co/6buvgfcKf1
Join us for our #AAAI2022 *Oral Presentation* of our paper on Sparse DNN training: "Gradient Flow in Sparse Neural Networks and How Lottery Tickets Win" tomorrow (Feb 24) @ 10:30-11:45am PST!
Poster at 8:45-10:30am/Feb 27 4:45-6:30pm. Work with @utkuevci, @ynd, @cem_keskin_.