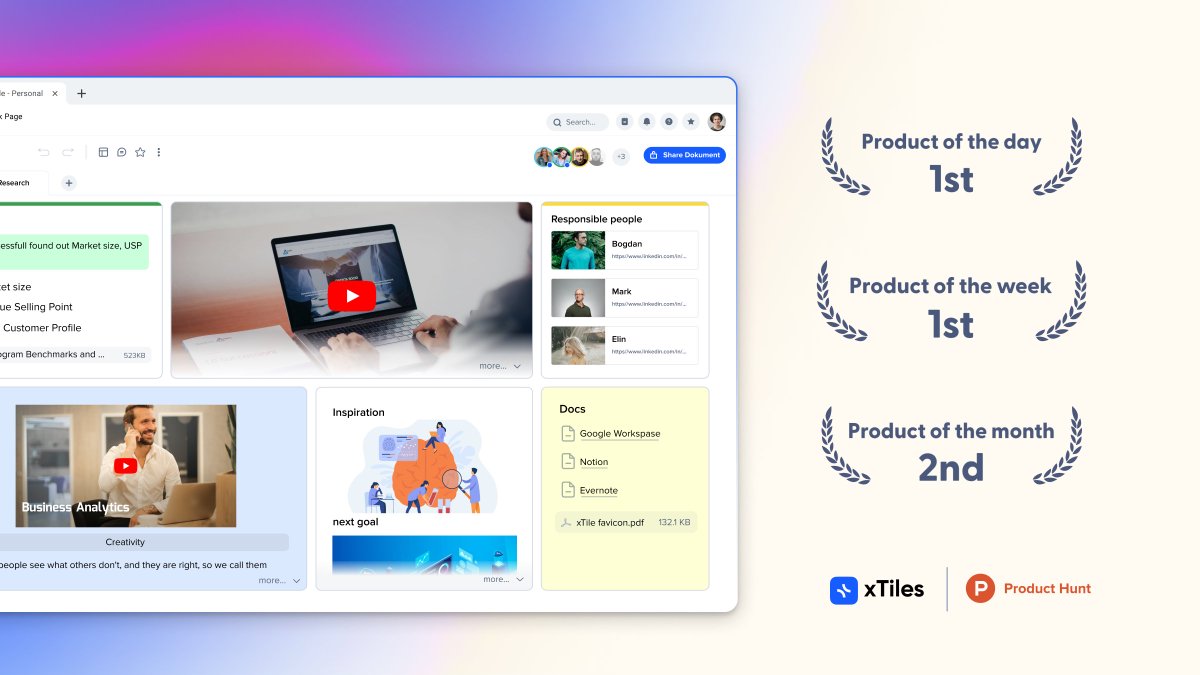
Product Hunt is finally done!
It was an exciting experience!😎😇
#1 Product of the Day 🥇
#1 Product of the Week 🥇
#2 Product of the Month 🥈
So, what did we gain?🤓
✔ Over 2500 upvotes!
✔ We got over 500 comments!
✔ 70+ paid customers!
Thanks to everyone who supported us
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral https://t.co/z21CP5iQfu
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
Andrej Karpathy didn't make a course. He made THE course.
Free. From the man who co-founded OpenAI and built Tesla Autopilot.
Tokenization. Attention. Hallucinations.
Tool use. RLHF. DeepSeek. AlphaGo..
Save the video. Watch it this Today & Start Building Ai Agents, Ai automation systems with the knowledge.
This has the entire training stack of every modern LLM, explained by the engineer who actually built Open AI and more... More valuable than any $10,000 over priced AI course.
Follow @codewithimanshu for breakdowns of every must-watch AI lecture for career upgrade.
↓
Karpathy doesn't teach AI like a YouTube influencer.
He teaches it like the guy who built it.
Founding member at OpenAI in 2015. Senior Director of AI at Tesla.
This is the most comprehensive LLM breakdown ever published on Internet.
The gap between engineers who understand this and engineers who don't isn't technical depth.
It's the ability to conceive of entirely different things.
↓
Here's the actual content.
Pretraining and the internet data layer.
Where LLMs actually come from. How the entire internet gets turned into training data. Why some data sources matter more than others.
Most "AI experts" can't explain this. Karpathy walks through it in 7 minutes.
Tokenization.
The single concept that explains why LLMs are bad at math and spelling.
Why "strawberry" has 3 R's but ChatGPT used to say 2. Why your prompt costs what it costs. Why some languages are more expensive than others.
This is the foundation. Skip it and nothing else makes sense.
Follow @codewithimanshu for daily breakdowns of what AI engineers actually need to know.
↓
Neural network internals.
What's happening inside the model when you hit "send."
Inputs, outputs, the math layer that turns tokens into predictions. Karpathy strips away the abstractions that every other tutorial hides behind.
You stop using AI like a magic black box and start using it like a tool you understand.
GPT-2 training and inference.
The exact same architecture as GPT-5. Just smaller.
Once you understand GPT-2, you understand every modern LLM. Karpathy walks through it line by line.
Llama 3.1 base model inference.
How a real production model actually generates text in real time.
This is the 5% of knowledge that separates engineers building AI products from people prompting them.
Follow @codewithimanshu for production AI architecture breakdowns weekly.
↓
Pretraining vs post-training.
The two phases that determine everything about how a model behaves.
Pretraining gives the model knowledge. Post-training gives it personality.
Most people don't know the difference. That's why their prompts produce inconsistent results.
Post-training conversations.
How AI models learn to actually have conversations. The exact data that goes in. Why some models feel "smarter" than others despite similar parameter counts.
This explains why Claude feels different from GPT. And how to think about choosing models for production.
↓
Hallucinations, tool use, working memory.
The most important section in the entire video.
Where hallucinations actually come from. Why models confidently lie. How tool use was engineered to fix it.
Every developer building with LLMs needs this section. It explains 90% of the bugs you'll hit in production.
Knowledge of self.
Why your AI agent doesn't know what model it is. Why it confidently claims to be GPT-4 when it's Claude. The architectural reason this happens and how to handle it.
Follow @codewithimanshu for engineering patterns that fix production AI bugs.
↓
Models need tokens to think.
The single insight that explains chain-of-thought prompting.
Why "think step by step" works. Why some prompts produce 10x better outputs with the same model. The mechanical reason this happens.
Once you understand this, you stop guessing prompts and start engineering them.
Tokenization revisited.
Why models struggle with spelling. Why character-level tasks fail. Why your specific use case might be impossible without a different approach.
This is the section that determines whether your AI product ships or breaks.
Jagged intelligence.
Why models are superhuman at some tasks and terrible at others. The pattern that explains every "AI is so dumb sometimes" moment you've had.
↓
Supervised fine-tuning to reinforcement learning.
The shift that made GPT-4 possible. The shift that made Claude great at conversation.
How models actually learn from human feedback. Why it works. Where it breaks.
Reinforcement learning.
The technique behind every reasoning model in 2026.
DeepSeek-R1. AlphaGo. The full lineage of how machines learned to think through problems instead of just predicting the next token.
Follow @codewithimanshu for RL and reasoning model breakdowns weekly.
↓
DeepSeek-R1 and AlphaGo.
The two case studies that explain modern AI reasoning.
DeepSeek for language. AlphaGo for game theory. Same underlying principle.
Once you understand both, you understand where AI is going next.
RLHF.
Reinforcement Learning from Human Feedback. The technique that made AI usable for normal humans.
Why your favorite model "just feels right." How that feeling was engineered. Why it costs millions of dollars.
This is the section that explains the actual cost structure of modern AI products.
↓
Where this puts you after 3 hours.
Most engineers using AI know how to prompt it.
After this video, you'll understand:
> How models are pretrained
> How they're fine-tuned
> How they handle context
> Why they hallucinate
> How tool use works
> Why some prompts work and others fail
> What RLHF does
> Where AI is going next
That's not "AI literacy." That's architectural understanding.
The kind of understanding that turns into $200K+ AI engineering roles.
The kind of understanding that lets you build the next ChatGPT instead of just using it.
↓
3 hours. Free. From the person who built it.
You've watched longer Netflix series this week and learned nothing.
This compounds for the rest of your career.
People who watch it understand AI at the architect level.
People who skip it stay confused about why their prompts fail in production.
Save the video. Watch it this weekend. Build something with the knowledge by Monday.
Follow @codewithimanshu for more high-signal AI content from the people actually building the future.
L’équipe d’Anthropic vient de montrer comment utiliser correctement Claude Code.
30 minutes. gratuit. présenté par la personne qui a créé Claude Code.
Regarde le workshop. Ajoute en signet 🔖
Ça vaut plus que tous les cours à 500$ que t’as failli acheter.
Getting inside your target’s head is the most crucial part of copywriting.
Here's how to learn everything there is to know about your target:
And then turn it into high-converting copy.
👇👇👇
As you say goodbye to 2023, use these 5 journaling prompts to practice the art of letting go:
• Why do I care about this item?
• Why do I care about this goal?
• Why do I care about this rule?
• Why do I care about this relationship?
• Why do I care about this memory?
during several months this year I tried reaching out to @NotionHQ team so they could explain why the hell they are proud of their moscovian community. they failed the communication, I stopped using their product and switched to an awesome Ukrainian software @xTilesHQ
Have you ever spent too much time designing a productive workspace instead of focusing on actual work?
Read our interview with @kuchur_maksym about @xTilesHQ, the all-in-one workspace for notes, tasks & projects to manage your knowledge as you see fit 👇
https://t.co/DL5ZtfH0y8
📝 MUST-HAVE APPS FOR STUDENTS
If you're a student, or someone who wants to be productive, using these apps can help you to function throughout the day😉
They will boost your productivity, gives you stimulation for a better mental state, and many more!