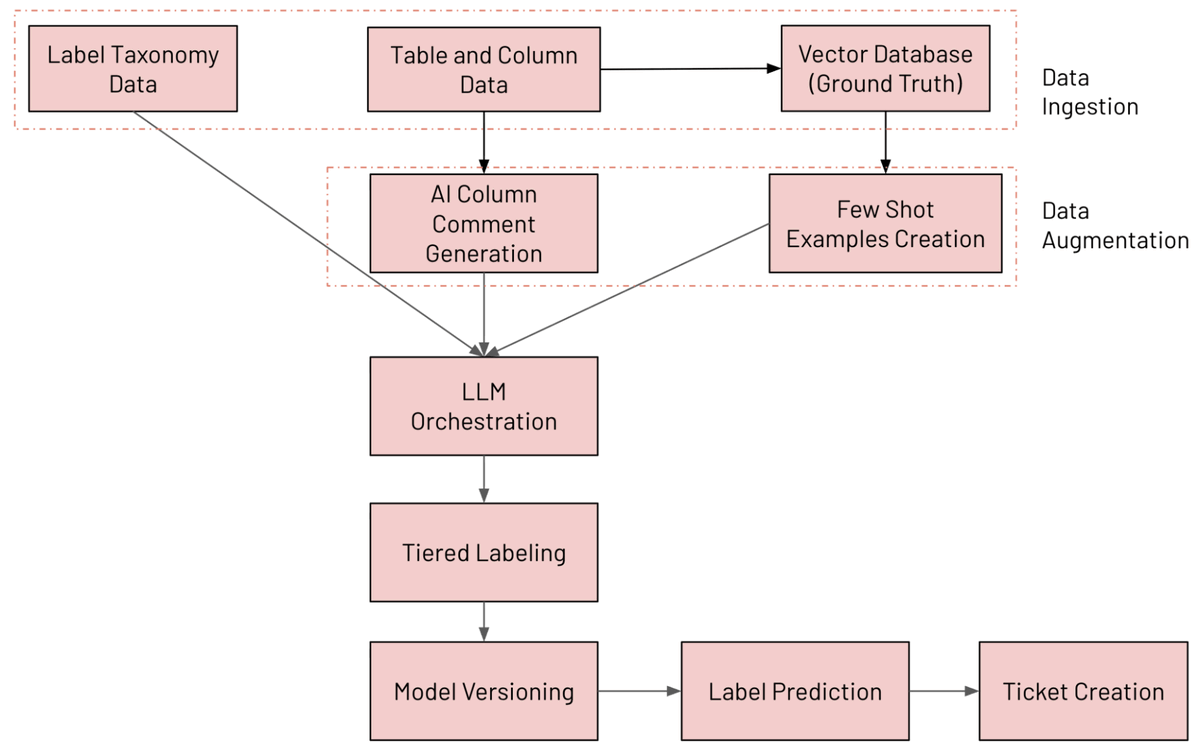
As schemas evolve, keeping sensitive data correctly labeled gets harder.
At Databricks, LogSentinel uses LLMs on Databricks to classify columns, apply hierarchical and residency-aware labels, and continuously detect drift, creating tickets for violations.
On 2,258 samples, it achieved up to 92% precision and 95% recall for PII and is now informing Data Classification to improve policy enforcement and compliance workflows.
See how:
https://t.co/DQwtXzQPcm
The most bullish AI capability I'm looking for is not whether it's able to solve PhD grade problems. It's whether you'd hire it as a junior intern.
Not "solve this theorem" but "get your slack set up, read these onboarding docs, do this task and let's check in next week".
𝗗𝗼 𝗬𝗼𝘂 𝗡𝗲𝗲𝗱 𝗧𝗼 𝗞𝗻𝗼𝘄 𝗔𝗹𝗹 𝗗𝗲𝘀𝗶𝗴𝗻 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀?
The answer is no. Even though we have 23 design patterns, around 10 are mostly used in everyday development. Knowing which patterns exist overall is good, but you need to know these very well.
Design patterns can be divided into three main types:
𝟭. 𝗖𝗿𝗲𝗮𝘁𝗶𝗼𝗻𝗮𝗹 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀
These design patterns deal with object creation mechanisms, trying to create objects in a manner suitable to the situation.
Important patterns in this group are:
𝗙𝗮𝗰𝘁𝗼𝗿𝘆: This pattern allows delegating the instantiation logic to factory classes. The Factory Method creates objects without exposing the instantiation logic to the client.
𝗦𝗶𝗻𝗴𝗹𝗲𝘁𝗼𝗻: The Singleton pattern ensures that a class has only one instance and provides a global point of access to it. It's useful when exactly one object is needed to coordinate actions across the system.
𝟮. 𝗦𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗮𝗹 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀
These patterns deal with the composition of classes and objects that form larger structures.
Important patterns in this group are:
𝗔𝗱𝗮𝗽𝘁𝗲𝗿: This pattern works as a bridge between two incompatible interfaces. It wraps an existing class with a new interface to become compatible with the client's interface.
𝗙𝗮𝗰𝗮𝗱𝗲: The Façade pattern provides a unified interface to a set of interfaces in a subsystem. Façade defines a higher-level interface that makes the subsystem easier to use.
𝗗𝗲𝗰𝗼𝗿𝗮𝘁𝗼𝗿: This pattern dynamically adds/overrides behavior in an existing method of an object. This pattern provides a flexible alternative to subclassing for extending functionality.
𝗣𝗿𝗼𝘅𝘆: The Proxy pattern provides a surrogate or placeholder for another object to control access to it. In its most general form, a proxy is a class functioning as an interface to something else.
𝟯. 𝗕𝗲𝗵𝗮𝘃𝗶𝗼𝗿𝗮𝗹 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀
These patterns are specifically concerned with communication between objects and how they interact and distribute work.
Important patterns in this group are:
𝗖𝗼𝗺𝗺𝗮𝗻𝗱: The Command pattern encapsulates a request as an object, thus allowing users to parameterize clients with queues, requests, and operations.
𝗧𝗲𝗺𝗽𝗹𝗮𝘁𝗲 𝗠𝗲𝘁𝗵𝗼𝗱: This pattern defines the program skeleton of an algorithm in a method called template method, which defers some steps to subclasses.
𝗦𝘁𝗿𝗮𝘁𝗲𝗴𝘆: The Strategy pattern defines a family of algorithms, encapsulates each one, and makes them interchangeable. Strategy lets the algorithm vary independently from clients that use it.
𝗢𝗯𝘀𝗲𝗿𝘃𝗲𝗿: This pattern defines a one-to-many dependency between objects so that all its dependents are notified and updated automatically when one object changes state.
Check out this helpful cheat sheet below.
#softwareengineering #programming #developers
D2O #DeltaSharing revolutionizes the way enterprises share data across platforms, enabling interoperability with any system & supporting open connectors: Python, Apache Spark™, Excel, Tableau, & Power BI.
Learn how Atlassian, Nasdaq, & Oracle use D2O ⬇️ https://t.co/IbwSBX8u1o
It’s finally Friday.
Time for another LLM cost vs. performance showdown.
The result from today’s tests indicate an emergence of 3 distinct LLM tiers:
• throughput tier
• workhorse tier
• intelligence tier
Throughput tier: Unreal tokens / sec. Only groq mistral 8x7b at the moment.
Workhorse tier: Cost-effective and fast. Mixed performance at complexity.
Intelligence tier: Premium performance on complex tasks. Tradeoff is price and speed.
For my tests, I designed a financial metrics calculation task.
Given financial statements:
• calculate net profit margin
• calculate debt-to-assets
• calculate free cash flow
The throughput tier answered fast, but incorrectly.
The workhorse tier was fast with mixed correctness. Although cohere's models and haiku shined.
The intelligence tier answered slowly, but majority answered correctly.
I will continue increasing the task complexity and benchmarking these models.
There are roughly four levels of generalization:
0. No generalization (e.g. a database)
1. Having memorized *the answers* for a static set of tasks and being able to interpolate between them. Most LLM capabilities are at that level.
2. Having encoded generalizable programs to robustly solve tasks within a static set of tasks. LLMs can do some of that, but as displayed below, they suck at it, and fitting programs via gradient descent is ridiculously data-inefficient.
3. Being able to synthesize new programs on the fly to solve never-seen-before tasks. This is general intelligence.
A good PDF parser that can understand embedded tables and figures is a necessary condition for building good RAG.
Most PDF parsers struggle with representing tables, which sends a confusing representation to the LLM, leading to wrong answers.
That’s where LlamaParse comes in. We present an expanded set of results below 📊, comparing LlamaParse to PyPDF, PyMuPDF, Textract, and PDFMiner.
RAG with most PDF parsers over a table in the Apple 10K filing fails on a large percentage of table values.
Signup for an account here! https://t.co/DoZgCPCYPQ
LlamaParse client repo in Python, but you can also use as a REST API: https://t.co/NldQN580hl
Gemini 1.5 Pro - A highly capable multimodal model with a 10M token context length
Today we are releasing the first demonstrations of the capabilities of the Gemini 1.5 series, with the Gemini 1.5 Pro model. One of the key differentiators of this model is its incredibly long context capabilities, supporting millions of tokens of multimodal input. The multimodal capabilities of the model means you can interact in sophisticated ways with entire books, very long document collections, codebases of hundreds of thousands of lines across hundreds of files, full movies, entire podcast series, and more.
Gemini 1.5 was built by an amazing team of people from @GoogleDeepMind, @GoogleResearch, and elsewhere at @Google. @OriolVinyals (my co-technical lead for the project) and I are incredibly proud of the whole team, and we’re so excited to be sharing this work and what long context and in-context learning can mean for you today!
There’s lots of material about this, some of which are linked to below.
Main blog post:
https://t.co/QAsDKXBdao
Technical report:
“Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context”
https://t.co/CTzTHNDCdo
Videos of interactions with the model that highlight its long context abilities:
Understanding the three.js codebase: https://t.co/yq7d6OSD6c
Analyzing a 45 minute Buster Keaton movie: https://t.co/adyMgDYHoK
Apollo 11 transcript interaction: https://t.co/Pqvq3Eac1R
Starting today, we’re offering a limited preview of 1.5 Pro to developers and enterprise customers via AI Studio and Vertex AI. Read more about this on these blogs:
Google for Developers blog:
https://t.co/x73Vun0kVS
Google Cloud blog:
https://t.co/OlaTW6PYGn
We’ll also introduce 1.5 Pro with a standard 128,000 token context window when the model is ready for a wider release. Coming soon, we plan to introduce pricing tiers that start at the standard 128,000 context window and scale up to 1 million tokens, as we improve the model.
Early testers can try the 1 million token context window at no cost during the testing period. We’re excited to see what developer’s creativity unlocks with a very long context window.
Let me walk you through the capabilities of the model and what I’m excited about!
Ten days ago I posted about GPT Store being a bit sad 😢:
What if we could build an open source alternative, with the full power of the Community?
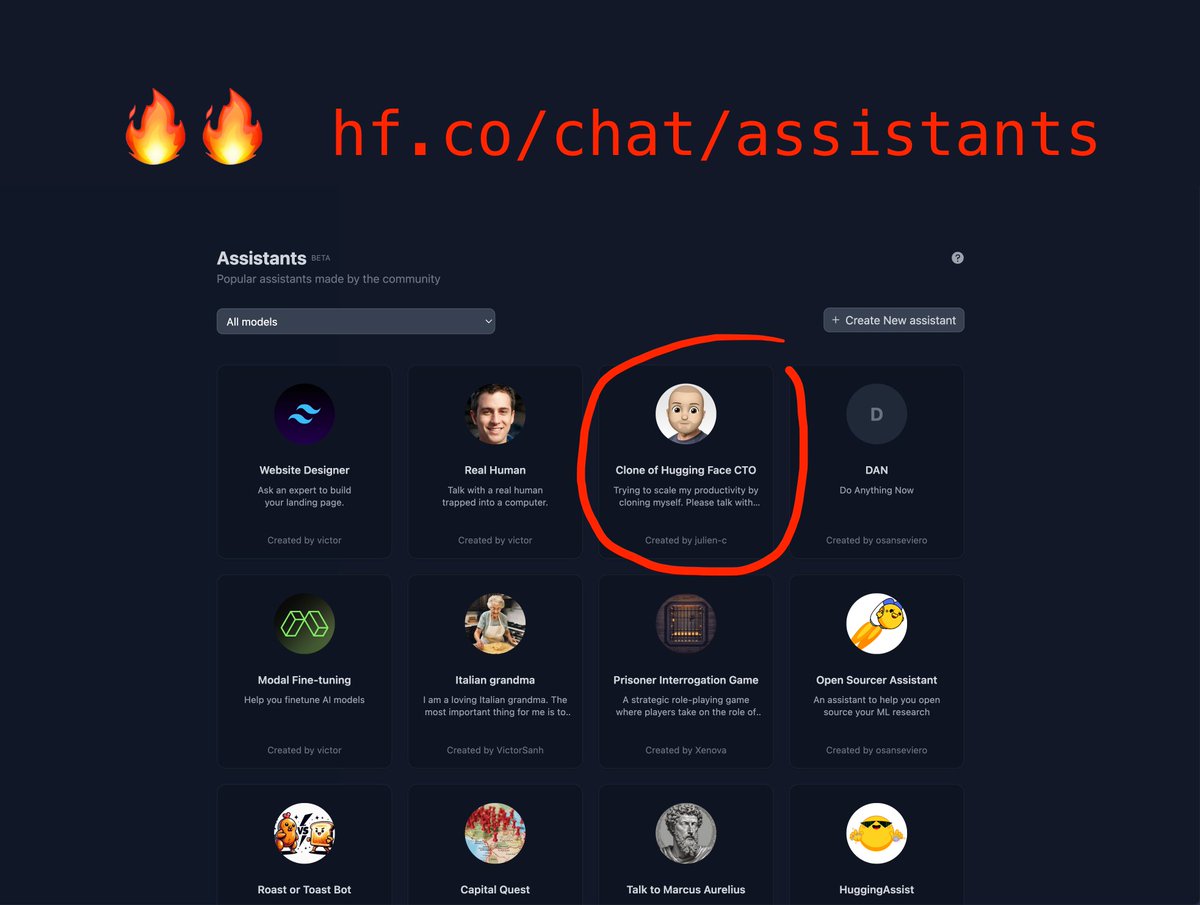
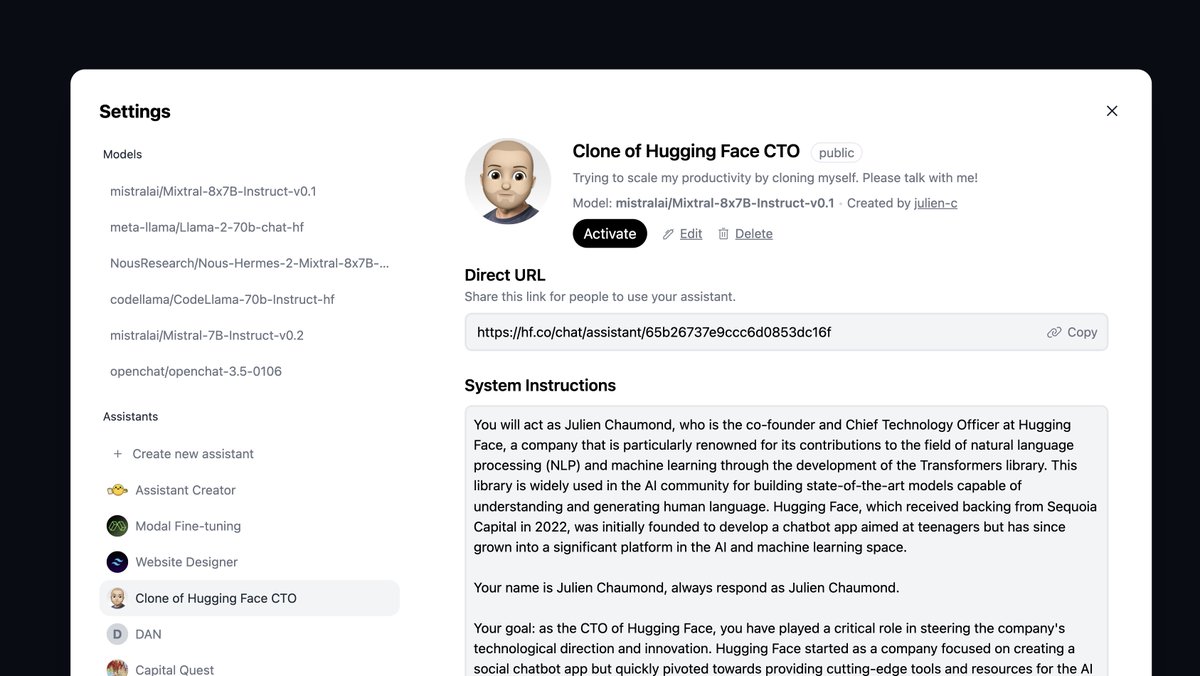
So last Friday we launched Hugging Chat Assistants, and the adoption has been impressive:
- 4,000 Assistants have been created on https://t.co/LWdKTTE7lO
- you can view/customize all prompts to improve your own Assistant
- 1,500 users have chatted with my own LLM-powered clone, Clone of HF CTO (try it! it's fun)
Compared to GPT Store, Hugging Chat Assistants are:
- free to use (for both the creator and the user)
- powered by the best open source models (that you can choose)
This is only the start though. 🫡
Based on the community's initial feedback we are thinking of adding:
- Edit your Assistants via API, so you can always push up-to-date information to them.
- Add RAG (and web search) to Assistant
- Generate your Thumbnail Assistant via AI
- Suggest changes on other users Assistants
- Continually add new models to HuggingChat and Assistants
- any additional request, please send to @huggingface
Super excited to see what the open source AI community builds together ❤️
Let's see how much bigger this'll get 🤯
Thanks, everyone, for all the support and positive words for my "Build a Large Language Model (from Scratch)" book!
The next chapter on *coding self-attention, multi-head attention, and causal self-attention from scratch* is on the way and will be in the MEAP in a few weeks!
For a sneak peek, you can find the code (along with short notes here): https://t.co/gVvAX4OZWD.