Hey everyone �� our high-performance MSA kernel library is now open-source. The M3 weights are expected to drop this Friday. Thanks for waiting!
Github: https://t.co/7hixC7FNg7
Paper:https://t.co/t1nHSJgGwB
Introducing NVIDIA Cosmos 3
We released NVIDIA Cosmos 3 last night.
And today, seeing it take the top spots across 8+ open model leaderboards feels surreal. We spent months working towards this moment.
Here’s the breakdown:
The Leaderboard Wins
World Reasoning
🏆 #1 open model on VANTAGE-Bench for vision AI
🏆 #1 overall on Traffic Anomaly Reasoning (TAR)
World Generation
🏆 #1 open model on Artificial Analysis Image-to-Video leaderboard
🏆 #1 open model on Artificial Analysis Text-to-Image leaderboard
🏆 #1 open model on PAI-Bench for physical AI synthetic data generation
🏆 #1 open model on Physics-IQ, which measures accuracy on physical laws
🏆 #1 open model on R-Bench for world generation quality
World Action
🏆 #1 on RoboArena for specialized policy
🏆 #1 on RoboLab for action generation
But the leaderboards are only part of the story. The real story is why we built Cosmos 3 in the first place.
The Problem
Training robots and autonomous systems in the real world is painfully hard.
Robots need to try the same thing numerous times before they succeed reliably. Self-driving cars need rare edge cases that may never happen naturally. Smart machines need to understand physics, motion, contact, failure, and surprise.
And real-world data is slow, expensive, and sometimes dangerous to collect. At some point, the answer cannot just be “collect more data.”
You can’t collect your way out of an infinite physical world. You have to generate it.
That… was the question behind Cosmos: Can one model understand the physical world deeply enough to reason about it, simulate it, and generate actions inside it?
What We Built
Cosmos 3 is the first omni-model for physical AI. It can understand and generate across: language · images · video · audio · action sequences
It is not just a VLM.
Not just a video generator.
Not just a robot policy model.
It is all of them, in one single model.
That matters because physical AI has been fragmented for a long time. Cosmos 3 is our attempt to collapse that fragmentation.
Depending on how you configure the inputs and outputs, the same model can act as a vision-language model, a video/world generator, a world simulator, or a world-action model.
No separate architecture required.
The Architecture
Under the hood, Cosmos 3 uses a dual-tower Mixture-of-Transformers architecture.
One tower is autoregressive for reasoning. It handles next-token prediction for language and discrete understanding.
The other tower is diffusion-based- for generation. It denoises images, video, audio, and action trajectories.
Two towers. Dual-stream joint attention. One shared world representation.
Each modality gets its own tools: visual encoders, video VAEs, audio VAEs, and action projectors that can map different embodiments into a unified action space.
Action is a first-class modality in Cosmos 3.
That’s what makes it more than a video model. It doesn’t just predict and generate what the world might look like. It can connect reasoning and world modeling to physically grounded action.
Why This Matters
One of the most interesting findings from the ablation work is that training action domains together creates positive transfer.
That means adding more embodiments does not just add more use cases. It can actually make the model better.
This is the heart of why omnimodal training matters.
A shared world representation is not just convenient. It can make each individual task stronger. That’s the part that feels like the beginning of something much bigger.
The part I’m most excited about is that Cosmos 3 is fully open.
Developers get the models, scripts, optimization, inference endpoints, post-training recipes, datasets, and benchmarks.
Everything is available under the Linux Foundation’s OpenMDW 1.1 License.
You can use Cosmos 3 out of the box. You can use the VLM, world model, or world-action pieces separately.
You can post-train it for your own domain, embodiment, or accuracy target.
That’s what makes this feel different.
Cosmos 3 is not just a model release. It is the foundation for building intelligence for autonomous machines.
For me, Cosmos 3 feels like a step toward a world where physical AI development becomes much more scalable and accessible - to a new age of developers and agents.
That’s what we built Cosmos 3 for. I cannot wait to see what you build with it.
Download Models on Hugging Face
https://t.co/LAZoVygeim
Customize Models on GitHub
https://t.co/ZVQBNdqXDD
Read the Tech Blog to Learn More
https://t.co/Hn6Op9YeG1
OpenAI Robotics is hiring, looking for exceptional full-stack hardware, ops, systems, and ML engineers to help us program and manufacture robots that are useful for society.
AI should be able to help people in the physical world. In the short term, we are focused on robots to support skilled workers to build our future infrastructure; in the long term, we imagine everyone having a personal robot doing anything they need.
Our world simulation research program, led by Aditya Ramesh (@model_mechanic), has evolved over the past year into OpenAI Robotics. Progress is rapid, and based on a foundation of co-design between robotics hardware and ML research.
If you love working hands-on across the robotics stack and want to build the future, please consider joining us. Send an email with your background and evidence of exceptional accomplishment to: [email protected]
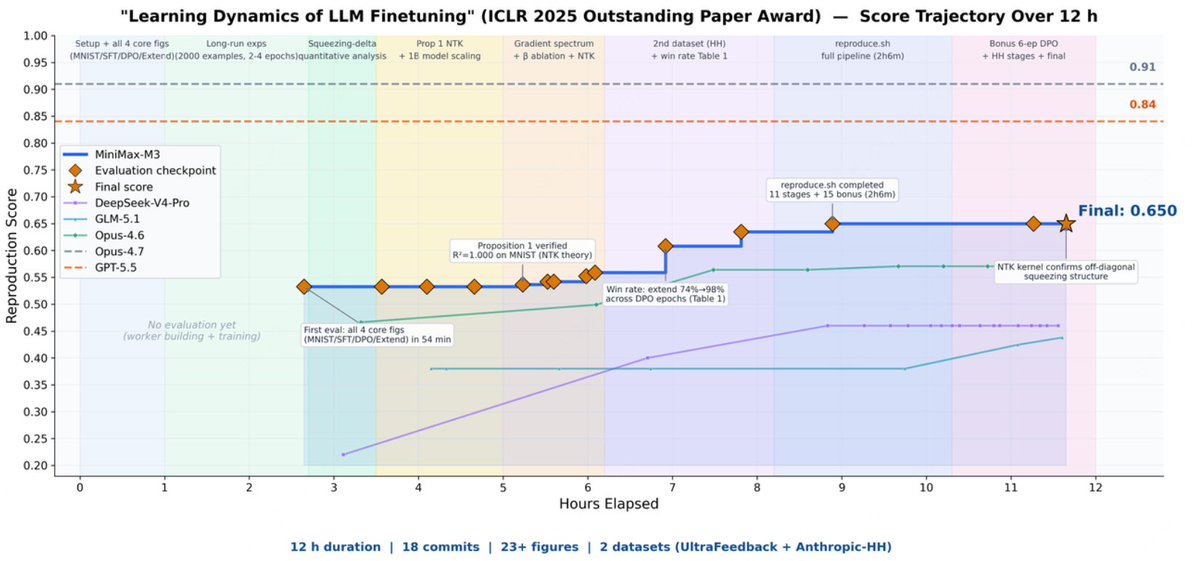
Key takeaway from the M3 blog: M3 independently reproduce an ICLR 2025 Outstanding Paper Award winner, "Learning Dynamics of LLM Finetuning."
M3 ran autonomously for nearly 12 hours, producing 18 commits and 23 experimental figures on its own, and got the core experiments working:
- it matched the predicted probability trends in the SFT stage
- clearly observed the squeezing effect central to the DPO experiments
- validated the Extend mitigation method proposed in the original paper.
Introducing 🔁 Awesome-Loop-Models: a curated repo for keeping up with loop models!
Whether you are just entering the field or have been exploring loop models for a while, this repo is built to serve as an actively updated map for mechanism analysis, architecture and algorithm design, applications, and related directions.
🧵 [1/n]
We start the research project, called adaptive training compute allocation, in ByteDance Seed one and a half year ago, because we believe that it is natural.
It has been a long and fasnating way to introduce Ouro / DLCM / ConceptMoE. It is still a long way.
🚀SonicMoE🚀now runs at peak throughput on NVIDIA Blackwell GPUs 😃
54% & 35% higher fwd/bwd TFLOPS than the DeepGEMM baseline and 21% higher fwd TFLOPS than the triton official example. SonicMoE still maintains its minimum activation memory footprint: the same as a dense model with equal activated parameters and independent of expert granularity. We wrote a blogpost on how we leveraged Blackwell features and the software abstraction on QuACK:
Work with @MayankMish98, @XinleC295, @istoica05, @tri_dao
This past week several people asked me about how Loop Transformers are related to Energy Transformers.
Energy Transformers are:
���� looped transformers
👉 energy-based models (EBMs)
👉 Dense Associative Memories — generalized Hopfield nets with superior scaling laws for information storage
That combo is powerful:
👉 looping = iterative refinement = reasoning in the latent space (not in token space)
👉 energy-based = stability of token dynamics
👉 Associative Memory = strong retrieval capabilities
Put together: models that settle into good solutions, not just predict next tokens.
I’ve been especially excited about this class of models for a while. They feel like a promising direction for more stable, interpretable, and memory-rich AI systems.
This week at #ICLR2026 we are presenting NRGPT https://t.co/UkXt54Dzhj, which is a:
👉 a looped transformer
👉 a stable Dense Associative Memory
👉 works great on ListOps and real text
Original Energy Transformer paper: https://t.co/UOfrwZXtOf from NeurIPS 2023
Learning on the Looped Transformer Thread (1/N)
I've been following the recent wave of work on looped/recurrent-depth transformers. Here are some interesting resources I've come across.
Good point on taste and ambition!! But for most PhD students, GPU access, budgets, and data constraints still bite hard. Agents reduce friction in coding and writing, but they do not remove the need for compute, careful evaluation, or sustained experimentation. So yes, ambition matters. But resources still determine which ambitious ideas get a real chance.
Kudos to the folks from Tencent for working with us and providing evals to improve OpenClaw's harness performance!
We're also working with them to bring fixes/improvements back to the open source repo.
Great option for folks not comfortable with the terminal.

































![huskydogewoof's tweet photo. Introducing 🔁 Awesome-Loop-Models: a curated repo for keeping up with loop models!
Whether you are just entering the field or have been exploring loop models for a while, this repo is built to serve as an actively updated map for mechanism analysis, architecture and algorithm design, applications, and related directions.
🧵 [1/n]](https://pbs.twimg.com/media/HGq6IOEWwAA_qal.jpg)






















