As of last week, I am no longer at NVIDIA 🧵
Leaving the CUTLASS team was extremely hard. I will dearly miss my incredible colleagues and the extremely compelling mission statement of creating the world's best accelerator programming model w/ hardware software codesign 💚
After some mathematical rewrite, turns out all of transformer is a series of gemm + epilogue. Given a few optimized primitives, LLMs (and novice humans) can write speed-of-light kernels for all transformer ops!
LLM training is built on fast MatMuls. But many surrounding ops still run as memory-bound kernels.
CODA reparameterizes them to hide in the matmul’s shadow, fused into its epilogue before results leave the chip.
Bonus: LLMs can write fast CODA kernels too (approaching SoLs).
We built a kernel abstraction to rewrite the entire transformer stack as GEMM + Epilogue kernels!
Neural net architectures such as transformers consist entirely of matrix multiplications and elementwise nonlinearities such as RMSNorm, log sum exp, and gated activations. Fusing these elementwise nonlinearities into GEMMs in both the forward and backward passes allows us to make training and prefill as compute-bound as possible!
Our kernel abstraction CODA is implemented in CuTeDSL, and by abstracting away the fixed prologue and main loop of the GEMM kernel, we expose an epilogue function where LLMs like Claude can easily implement elementwise nonlinearities in fusions approaching speed-of-light!
We’ve developed our own inference engine Runtime-Optimized Serving Engine (ROSE) to serve models ranging from embeddings to trillion-parameter LLMs.
With CuTeDSL integrated into our inference engine, Perplexity can build the specialized GPU kernels faster to bring models up to peak performance on NVIDIA Hopper and Blackwell GPUs.
We're open-sourcing FlashKDA — our high-performance CUTLASS-based implementation of Kimi Delta Attention kernels. Achieves 1.72×–2.22× prefill speedup over the flash-linear-attention baseline on H20, and works as a drop-in backend for flash-linear-attention.
Explore on github: https://t.co/sf4UohXDWY
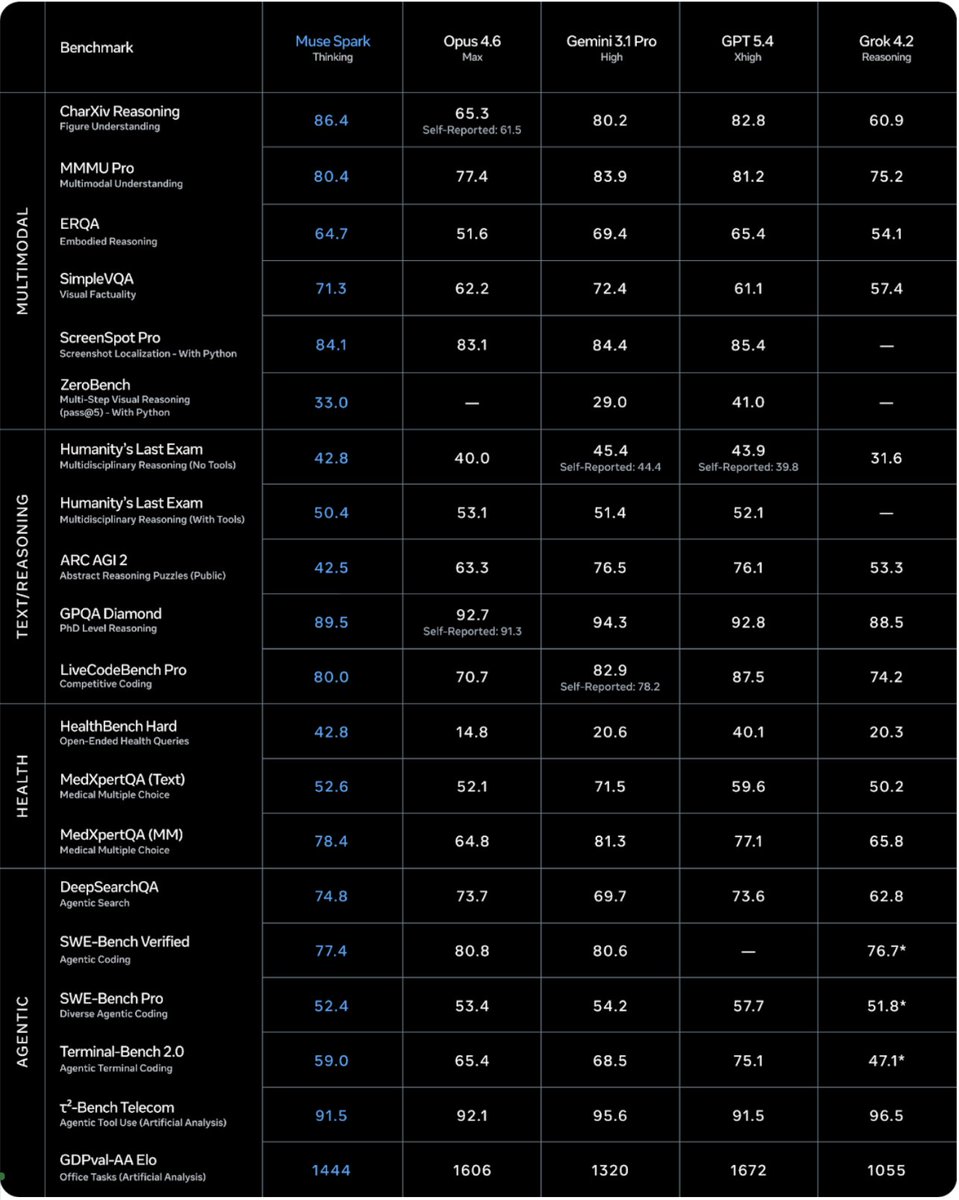
Meta released Avocado, they call it Muse Spark.
It's not open source (a bit sad).
Meta TBD lab rebuilt the entire pretraining stack in 9 months and reached similar capability with >10x less compute than Llama 4 Maverick.
I still think infra is the real moat in AI labs. You can train models much faster with a good infra, and it allows researchers to experiment with many more ideas much more quickly.
Excited to share what we’ve been building at Meta Superintelligence Labs! We just released Muse Spark, our first AI model. It's a natively multimodal reasoning model and the first step on our path to personal superintelligence. We've overhauled our entire stack to support scaling, and this is just the beginning.
https://t.co/KNVjgMcch1
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
Very cool! I worked on this recently, and I actually used an identical approach early on. But I believe there is a significantly better approach - a **single** minimax rational iteration can beat 5 polynomial steps!
Trtllmgen kernels are now open. Fastest prefill and decode kernels for our target workloads. We wrote these to win InferenceX, MLPerf, other benchmarks. Powering some of today’s top served models. Dive in, learn, use them, or level up your own. Enjoy.
https://t.co/2aQBwcdnZL
The frontier has increasingly shifted to hybrid models - from Qwen to Kimi-Linear and now with NVIDIA's Nemotron-3 Super - that rely on a strong linear sequence model. Today we release Mamba-3, the most powerful linear model to date.
https://t.co/OpMmqEWMkP
Excited to share @Standard_Kernel's seed round and some reflections on what we’ve learned about kernel generation and what we believe is next. Grateful to our amazing team, supporters, and the broader community pushing this space forward.