@zkDragon@cypherpunk Hmm, this may be griefable for notes where you don't own the whole history. You got paid and migrate, but the payer doesn't, and you don't own that history (could just be key migration too) 🤔
@zkDragon@cypherpunk Isn't there a path here where you can require a migration from all shielded holders that prove no double spend? All shielded notes would be unusable until migrated. Proof could be zk or revealing vk to a tee to verify provenance/history.
Last week I discovered that ChatGPT and Claude will send you their “encrypted raw reasoning” and of course I immediately wasted a weekend trying to do something bad with it. What I got for my trouble was this blog post: https://t.co/bxWNsFCaRL
The RF world is insane.
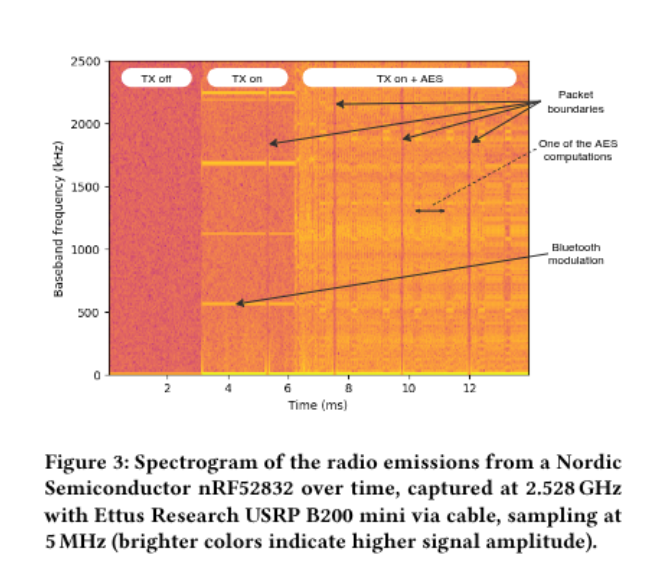
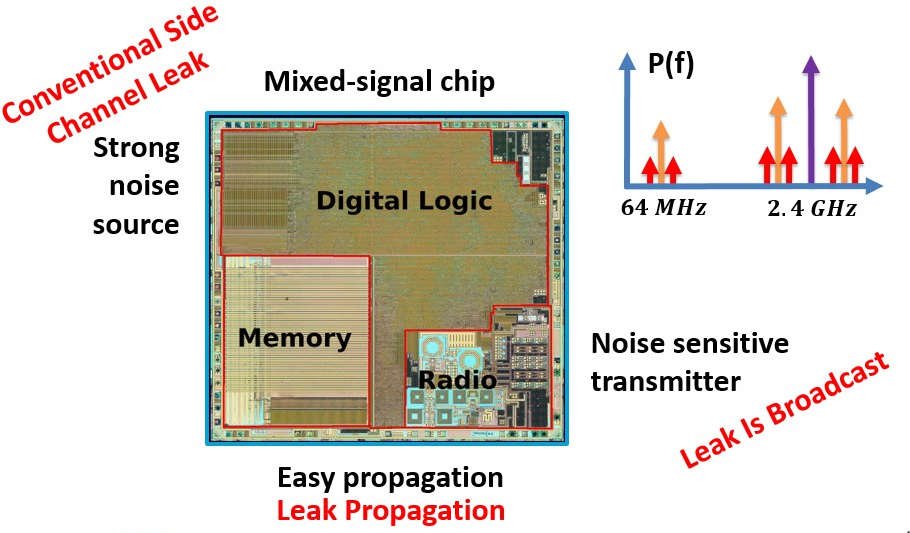
Researchers recovered AES-128 keys from a Bluetooth chip by listening to its own antenna from 10 meters away.
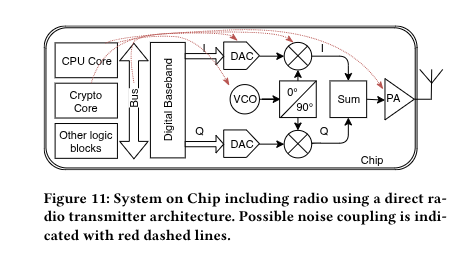
Crypto-engine switching noise couples into the RF chain, rides the 2.4 GHz carrier, and leaks out as radio.
0/ DeFi needs circuit breakers and other safety mechanisms which slow down large transactions and provide time for reaction. Borrow lend protocols should not allow a new user to show up with a $300M position and take out a loan against it immediately. Some ideas:
This is the kind of attack that many people in blockchain security had long expected.
This is why proof based protocols, multiple, operator diversity etc matter.
The challenge with security is that it’s a super long game and it’s hard to convince the market that exploits that haven’t happened yet are real.
@paulg Just did this test at home and everyone could immediately taste. Even did the advanced version which was to decide by only smelling one (blindfolded). 100% success rate.
Nice post by @hale1emmeric explaining the ATOM supply sink and revenue math with ICL's enterprise plan, at conservative adoption levels: https://t.co/q0rWwoGJRS
(Let alone betting on an explosive growth of 100M volume/day from one integration)
Now, everyone is talking about breaking encryption, but what about mining Bitcoin faster? Using Grover's algorithm to find valid block hashes faster than classical ASICs?
I’ve always been a bit of a Grover’s algorithm hater (look back at my old podcasts…)
Why?
1. quadratic speed up is fine, but that speedup is compared to worst case search algorithms. and classical search can be *very* clever.
2. how do you even encode a database of basically bit strings onto a quantum state?
3. and this question on resources, just answered...
A new paper from @dallairedemers and @BTQ_Tech priced the cost of hardware, going through resource estimates for reversible oracle design, surface code error correction, factory sizing, fleet logistics, wall-plug power. The full electric bill.
The punchline:
At Bitcoin's current mainnet difficulty, a quantum mining fleet would require approximately 10²³ physical qubits drawing 10²⁵ watts of power.
For context: that's approaching Kardashev Type II. The energy output of an entire star.
The three reasons Grover's quadratic speedup collapses in practice:
1. Oracle overhead. A reversible double-SHA-256 oracle requires ~300,000 T-gates per Grover iteration. That inflates the naïve query count by a factor of ~2³⁸ in non-Clifford operations.
2. Distillation tax. Every T-gate requires a magic-state distillation factory occupying thousands of physical qubits. Hundreds to thousands running in parallel. The surface code overhead is brutal.
3. Fleet multiplication. Bitcoin's 10-minute block window caps how deep any single Grover search can go. So you compensate with exponentially many independent machines. The fleet requirement explodes with every difficulty adjustment.
But wait — if this holds true for Grover’s, why do we believe Shor's algorithm is still a threat to Bitcoin?
Because the problems have a fundamentally different structure.
Shor attacks elliptic curve discrete logarithm — a structured mathematical problem. The algorithm exploits the periodicity of a group. That structure makes the quantum circuits expensive but the number of iterations polynomial. Y
Grover attacks SHA-256 — an unstructured search. No exploitable algebra.
And also remember, Bitcoin is made so that difficulty adjusts. So yes, if we figure out Grover’s somehow, it doesn’t mean you’ll grab the rest of the 1.3M bitcoin that will be mined over the next 118 years.
Difficulty adjusts every 2016 blocks, capped at 4x difficulty increase per epoch. So yes, a quantum miner would get a window to mine faster than everyone else. But it's a window, not a free pass. The network catches up. And the supply schedule is fixed regardless. There’s a lot of nuance here, but it’s very interesting to dive deeper into the mechanisms.
BREAKING: You checked the weather this morning.
And you just told a surveillance company where you sleep.
Meet #Webloc, used by ICE, cops & foreign govs to track 500m+ phones.
No warrant required.
Our latest @citizenlab investigation + how to protect yourself 🧵/1
Today is a monumentous day for quantum computing and cryptography. Two breakthrough papers just landed (links in next tweet). Both papers improve Shor's algorithm, infamous for cracking RSA and elliptic curve cryptography. The two results compound, optimising separate layers of the quantum stack. The results are shocking. I expect a narrative shift and a further R&D boost toward post-quantum cryptography.
The first paper is by Google Quantum AI. They tackle the (logical) Shor algorithm, tailoring it to crack Bitcoin and Ethereum signatures. The algorithm runs on ~1K logical qubits for the 256-bit elliptic curve secp256k1. Due to the low circuit depth, a fast superconducting computer would recover private keys in minutes. I'm grateful to have joined as a late paper co-author, in large part for the chance to interact with experts and the alpha gleaned from internal discussions.
The second paper is by a stealthy startup called Oratomic, with ex-Google and prominent Caltech faculty. Their starting point is Google's improvements to the logical quantum circuit. They then apply improvements at the physical layer, with tricks specific to neutral atom quantum computers. The result estimates that 26,000 atomic qubits are sufficient to break 256-bit elliptic curve signatures. This would be roughly a 40x improvement in physical qubit count over previous state-of-the-art. On the flip side, a single Shor run would take ~10 days due to the relatively slow speed of neutral atoms.
Below are my key takeaways. As a disclaimer, I am not a quantum expert. Time is needed for the results to be properly vetted. Based on my interactions with the team, I have faith the Google Quantum AI results are conservative. The Oratomic paper is much harder for me to assess, especially because of the use of more exotic qLDPC codes. I will take it with a grain of salt until the dust settles.
→ q-day: My confidence in q-day by 2032 has shot up significantly. IMO there's at least a 10% chance that by 2032 a quantum computer recovers a secp256k1 ECDSA private key from an exposed public key. While a cryptographically-relevant quantum computer (CRQC) before 2030 still feels unlikely, now is undoubtedly the time to start preparing.
→ censorship: The Google paper uses a zero-knowledge (ZK) proof to demonstrate the algorithm's existence without leaking actual optimisations. From now on, assume state-of-the-art algorithms will be censored. There may be self-censorship for moral or commercial reasons, or because of government pressure. A blackout in academic publications would be a tell-tale sign.
→ cracking time: A superconducting quantum computer, the type Google is building, could crack keys in minutes. This is because the optimised quantum circuit is just 100M Toffoli gates, which is surprisingly shallow. (Toffoli gates are hard because they require production of so-called "magic states".) Toffoli gates would consume ~10 microseconds on a superconducting platform, totalling ~1,000 sec of Shor runtime.
→ latency optimisations: Two latency optimisations bring key cracking time to single-digit minutes. The first parallelises computation across quantum devices. The second involves feeding the pubkey to the quantum computer mid-flight, after a generic setup phase.
→ fast- and slow-clock: At first approximation there are two families of quantum computers. The fast-clock flavour, which includes superconducting and photonic architectures, runs at roughly 100 kHz. The slow-clock flavour, which includes trapped ion and neutral atom architectures, runs roughly 1,000x slower (~100 Hz, or ~1 week to crack a single key).
→ qubit count: The size-optimised variant of the algorithm runs on 1,200 logical qubits. On a superconducting computer with surface code error correction that's roughly 500K physical qubits, a 400:1 physical-to-logical ratio. The surface code is conservative, assuming only four-way nearest-neighbour grid connectivity. It was demonstrated last year by Google on a real quantum computer.
→ future gains: Low-hanging fruit is still being picked, with at least one of the Google optimisations resulting from a surprisingly simple observation. Interestingly, AI was not (yet!) tasked to find optimisations. This was also the first time authors such as Craig Gidney attacked elliptic curves (as opposed to RSA). Shor logical qubit count could plausibly go under 1K soonish.
→ error correction: The physical-to-logical ratio for superconducting computers could go under 100:1. For superconducting computers that would be mean ~100K physical qubits for a CRQC, two orders of magnitude away from state of the art. Neutral atoms quantum computers are amenable to error correcting codes other than the surface code. While much slower to run, they can bring down the physical to logical qubit ratio closer to 10:1.
→ Bitcoin PoW: Commercially-viable Bitcoin PoW via Grover's algorithm is not happening any time soon. We're talking decades, possibly centuries away. This observation should help focus the discussion on ECDSA and Schnorr. (Side note: as unofficial Bitcoin security researcher, I still believe Bitcoin PoW is cooked due to the dwindling security budget.)
→ team quality: The folks at Google Quantum AI are the real deal. Craig Gidney (@CraigGidney) is arguably the world's top quantum circuit optimisooor. Just last year he squeezed 10x out of Shor for RSA, bringing the physical qubit count down from 10M to 1M. Special thanks to the Google team for patiently answering all my newb questions with detailed, fact-based answers. I was expecting some hype, but found none.
We found the same Fiat-Shamir bug in six independent zkVMs.
The result: an attacker can bypass the cryptography entirely and prove mathematically impossible statements (like minting $1M out of thin air).
Full breakdown ↓
On the one hand, AI influencers are breathlessly raving about Claude Code, Clawdbot, and Cowork. And on the other hand, most people I know—even software engineers—are despondent, overwhelmed about how everything is changing so quickly. I hear this from people early in their careers especially, a fear that everything they've learned and the skills they've gained are rapidly being devalued.
This is a mental trap. Don't fall for it. You should not just be watching from the sidelines or reading articles about "how software engineering is changing."
Imagine it was 1993 and the personal computer revolution was kicking off. If you could go back in time to then, what should you have done?
The answer: try everything. Buy a PC. Learn how to touch type. Figure out what the Internet is. Imbibe it all. Don't wait until it becomes a job requirement.
That's exactly what you should do with AI. Try everything. Try Claude Code, try Clawdbot, try the Excel integrations, Veo, everything you can get your hands on. Learn what it's doing. Build your intuitions. Be one step ahead of it. Evolve alongside it. Don't lose your curiosity or get swallowed by anxiety or let yourself be convinced that you'll learn it when you have to. Think deeply about how AI will change the things around you—not society, that's too hard to project—but how it will change your job, your personal life, your immediate environment.
No matter how old you are or young you are, no matter what stage of your career you are in, we are all going through the biggest technological change of the last 100 years, and we're going through it together. Nobody has the answers. It's obvious that so much is going to change, but nobody is going to figure it out before you do if you choose to stay at the frontier.
So don't hide from it. Sit at the front of the class. Pay close attention. And be grateful that it's never been easier to stay at the frontier of the most important technology change of our lifetimes.
A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
People vastly, vastly over engineer most things
And for the average person you will get more performance out of a system by trying to figure out what you can remove, not add