AI has now solved a major open problem -- one of the best known Erdos problems called the unit distance problem, one of Erdos's favourite questions and one that many mathematicians had tried.
https://t.co/SD1vVPkrHR
I wrote a blog post about a Codex harness/workflow I built to autonomously prove a new mathematical result after 3 days of continuous work producing ~60k lines of Lean, where the input is a Lean theorem statement and output is a fully formalized proof.
1/4
https://t.co/QQUeAGc3OC
1/ We found that deep sequence models memorize atomic facts "geometrically" -- not as an associative lookup table as often imagined.
This opens up practical questions on reasoning/memory/discovery, and also poses a theoretical "memorization puzzle."
(1/8)🍎A Galileo moment for LLM design🍎
As Pisa Tower experiment sparked modern physics, our controlled synthetic pretraining playground reveals LLM architectures' true limits. A turning point that might divide LLM research into "before" and "after." https://t.co/7CZ6pTMlc9
Here's a nice "proof without words":
The sum of the squares of several positive values can never be bigger than the square of their sum.
This picture helps make sense of how ℓ₁ and ℓ₂ norms regularize and sparsify solutions (resp.). [1/n]
I had a blast talking about "The Power of (Modern) Convex Optimization in Nonconvex Perception, Control, and Learning" at Northeastern University.
I highlighted two recent strands of research from my group:
(1) Convex relaxation + large-scale numerical optimization + structure of robotics problems + new computing hardware such as GPUs + data, will provide a "reimagined" solution to nonconvex optimization problems that were previously considered too difficult to solve (e.g., structure from motion, trajectory optimization)
(2) Adaptive optimization algorithms, in particular those recently introduced in the online convex optimization community, have surprising potential in designing "truly adaptive" optimizers that make learning/finetuning more stable, robust, efficient, and work "out of the box" (e.g., tackling loss of plasticity in lifelong reinforcement learning).
Check out my slides if interested, and
stay tuned for more that's coming!
https://t.co/i8Ae2QXY5N
Today, I’m excited to share with you all the fruit of our effort at @OpenAI to create AI models capable of truly general reasoning: OpenAI's new o1 model series! (aka 🍓) Let me explain 🧵 1/
(1/7) Physics of LM, Part 2.2 with 8 results on "LLM how to learn from mistakes" now on arxiv: https://t.co/3iFS1Z4IfU. We explore the possibility to enable models to correct errors immediately after they are made (no multi-round prompting). Check out the slides in this thread.
(1/2) Many asked for Part 2.2 and I'm sorry for the delay. Our author Zicheng Xu has been unexpectedly laid off. He has my strongest endorsement (see next post). If interested in this project or hiring him, contact him at [email protected] (remove the capital 'B')
Posted Youtube video https://t.co/FoapZG44fA of "A 60-year journey in #convex#optimization," a lecture on the history and the evolution of the subject. From a 2009 MIT event honoring S Mitter. Includes a review of the MCMC abstract duality framework.
Large Language Models and Transformers - Simons Institute
Excellent lectures on ongoing revolution in transformers and large language models. Topics range from recent publications, frontier/foundational works, and all things LLMs.
Features people who are at the forefront of AI research(ex: Christopher Manning, Ilya Sutskever, Sasha Rush, Colin Raffel, Jitendra Malik, to name a few).
Workshop website: https://t.co/sRox8COcHR
Videos on YouTube: https://t.co/GvahesdpNj
Transformers 🤖 are cool but expensive to serve. What are the tips & tricks to model 𝘂𝘀𝗲𝗿 𝗮𝗰𝘁𝗶𝗼𝗻𝘀 with Transformers and serve recommendations in 𝗥𝗲𝗮𝗹𝘁𝗶𝗺𝗲 at @Pinterest📌 scale? See our paper 𝗧𝗿𝗮𝗻𝘀𝗔𝗰𝘁 at #KDD2023@PinterestEng ! https://t.co/WHWuBRi8Xk
I also would like to thank @brandondamos for his amazing tutorial on amortized optimization (AO) https://t.co/2UpA0iSLFp which helps me a lot when applying AO to SW. I strongly recommend this if you want to know a comprehensive usage of AO in machine learning. (12/12)
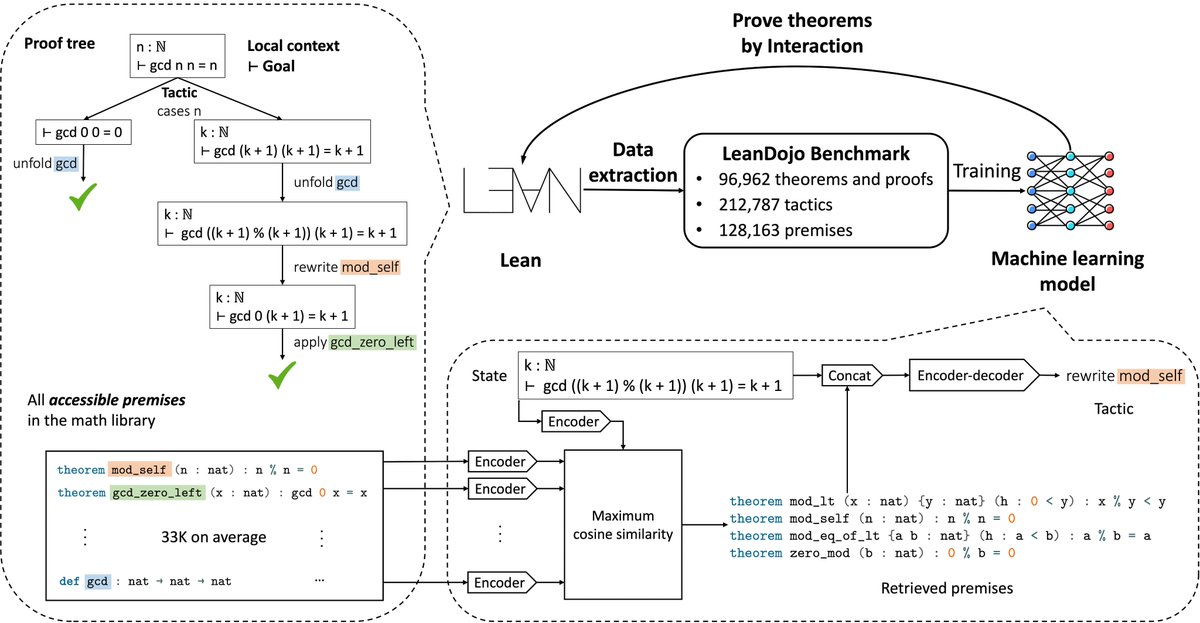
Can LLMs generate mathematical proofs that can be rigorously checked?
We release LeanDojo (https://t.co/zkOyW4FoDx): an open-source playground consisting of toolkits, benchmarks, and models for LLMs to prove formal theorems in the Lean proof assistant.
Key features:
- Tools for data extraction and interacting with Lean.
- Fine-grained annotations of premises (e.g., existing lemmas) in proofs: where they are used and defined.
- LeanDojo Benchmark: 97K human-written theorems/proofs for developing machine learning models on theorem proving.
- ReProver (Retrieval-Augmented Prover): the first LLM-based prover augmented with retrieval for premise selection.
We open-source everything, providing the first set of open-source LLM-based theorem provers without any proprietary data, model, or code.
@karpathy Super excited to push this even further:
- Next week: bitsandbytes 4-bit closed beta that allows you to finetune 30B/65B LLaMA models on a single 24/48 GB GPU (no degradation vs full fine-tuning in 16-bit)
- Two weeks: Full release of code, paper, and a collection of 65B models