Google has open-sourced LangExtract:
A Python library that turns unstructured documents into structured data, with clear source references for every result.
100% open-source.
I'm Boris and I created Claude Code. I wanted to quickly share a few tips for using Claude Code, sourced directly from the Claude Code team. The way the team uses Claude is different than how I use it. Remember: there is no one right way to use Claude Code -- everyones' setup is different. You should experiment to see what works for you!
YARATICISINDAN CLAUDE CODE TAKTİKLERİ 🚀
Claude Code ekibi böyle kullanıyor👇🏻
Kaydet lazım olacak 📌
👉Paralel çalış, worktree kraldır
3–5 ayrı git worktree aç, her birinde bağımsız Claude code çalıştır. Claude code ekibinin en büyük verim artışı bu sayede olmuş.
👉Her karmaşık işte önce PLAN moduna gir
Plan moduna tüm enerjini verirsen claude code isteğini one shot bile yapabilir. İş sapıttığında hemen geri plan moduna gir, zorlama.
👉Kendi kendini eğiten Claude code docs’u güncelle!
Her hatadan sonra hatasını anlat, "bunu kaydet ve bir daha yapma" de. Zamanla hata oranı düşüyor. Bazıları proje başına notes klasörü tutup oraya point ediyor, deneyebilirsin.
👉Tekrarlanan işleri skille çevir
Bir işi günde 1’den fazla yapıyorsan → command veya skill haline getir.
👉Bug fixleri Claude Code'a bırak
Bug analizini review aracına yaptır, sonra yapıştır + “fix” de → bitti. Sonra “CI testlerini düzelt” de mesela.
👉Prompting level atla
- “Değişiklikleri kontrol+test et, testten geçmeden PR açma”
- Her fix sonrası: “Şimdi bildiğin her şeyle çözümü baştan yaz”
- Detaylı spec ver, belirsizliği sıfırla.
👉Öğrenme modu
Explanatory/learning style aç → nedenini açıkla. Karmaşık kodları HTML sunum veya ASCII diagram haline getirmesini iste daha verimli olur. Boşlukları doldurma yeteneğini çağır, sen anlat, Claude code soru sorup boşlukları doldursun.
Thank you @bcherny ♥️
8 yıllık mobil geliştirme serüvenimde şunu çok kez deneyimledim:
Uygulamayı geliştirmek maratonun yarısıysa, mağazada yayına almak diğer yarısı. Ve en sıkıcı olanı.
App Store/Play Store girişi, ekran görüntüleri, lokalizasyon, gizlilik metinleri derken asıl ürün geliştirmeden uzaklaşıyoruz.
Tüm bunların bir çözümü var, gelin benle +++
Akışta Claude Code üyeliğini başlatan çok fazla kişi görüyorum.
Eğer aranızda geçenler varsa, 2025’te LLM’lerle 2.000 saat kod yazmış bu adamın paylaştığı Claude Code kullanım pattern’larına mutlaka göz atmanızı tavsiye ederim.
Etsy’de rakip tag’lerin hacmini ve liste yaşını gösteren Everbee eklentisi bu arada BELEŞ 💯💯💯
Eskidende beleşdi hâla da beleş 🤯
Abi hiç bir şey bilmiyoz diyorsan kur eklentiyi rahatına bak.
Everyone is sleeping on this new paper from AWS.
A model 100x smaller than GPT and Claude crushed them on tool calling.
AWS researchers took Facebook's OPT-350M, a model from 2022 with 500x fewer parameters than GPT, and fine-tuned it on ToolBench for a single epoch.
The results are wild:
↳ Their SLM: 77.55% pass rate
↳ ChatGPT-CoT: 26%
↳ ToolLLaMA: 30%
↳ Claude-CoT: 2.73%
Here's what's happening:
Large models suffer from "parameter dilution." Most of their capacity is optimized for general language tasks, not the precise Thought-Action-Action Input patterns that tool calling needs.
A small model trained specifically on tool calling concentrates all its capacity on that one thing. No distractions.
The training setup was surprisingly simple. Hugging Face TRL, 187K examples, learning rate of 5e-5, and aggressive gradient clipping for stability.
But I want to be clear on something:
This doesn't mean small models win everywhere. The authors acknowledge their model may struggle with complex contextual nuances or ambiguous requests. It's a specialist, not a generalist.
Still, if you're building agentic systems and want to cut inference costs by orders of magnitude, this is worth paying attention to.
I've shared link to the paper in the next tweet.
Meta just solved RAG's biggest bottleneck.
30× faster decoding. Zero accuracy loss.
The problem nobody talks about:
When you feed an LLM 80 retrieved passages, only 5-10 are actually useful.
The rest? Dead weight. But you're computing attention for ALL of them.
The math is brutal:
Traditional RAG with 16K context: → 100+ seconds to first token → 10× throughput drop → Massive memory waste
What REFRAG does:
Compresses context chunks into single embeddings.
Instead of processing 16,384 tokens → Process 1,024 chunk embeddings.
The results:
✓ 30.85× faster time-to-first-token
✓ Zero perplexity loss
✓ 16× context extension (4K → 64K tokens)
✓ 3.75× better than previous SOTA
Why it works:
RAG contexts have sparse attention patterns. Most retrieved passages don't interact. REFRAG exploits this with:
1./ Precomputable embeddings - Cached from retrieval, reused across inferences
2./ RL-based compression - Smart policy decides what to compress
3./ Works anywhere - Unlike previous methods, compresses at any position
Real impact:
• 8 passages at single-passage latency
• Better accuracy with weak retrievers
• Handles unlimited conversation history
• No model architecture changes needed
This changes RAG economics: More context + Lower latency.
(Link to the Meta paper in comments)
♻️ Repost to save someone $$$ and a lot of confusion.
✔️ You can follow @techNmak, for more insights.
New post: nanochat miniseries v1
The correct way to think about LLMs is that you are not optimizing for a single specific model but for a family models controlled by a single dial (the compute you wish to spend) to achieve monotonically better results. This allows you to do careful science of scaling laws and ultimately this is what gives you the confidence that when you pay for "the big run", the extrapolation will work and your money will be well spent. For the first public release of nanochat my focus was on end-to-end pipeline that runs the whole LLM pipeline with all of its stages. Now after YOLOing a few runs earlier, I'm coming back around to flesh out some of the parts that I sped through, starting of course with pretraining, which is both computationally heavy and critical as the foundation of intelligence and knowledge in these models.
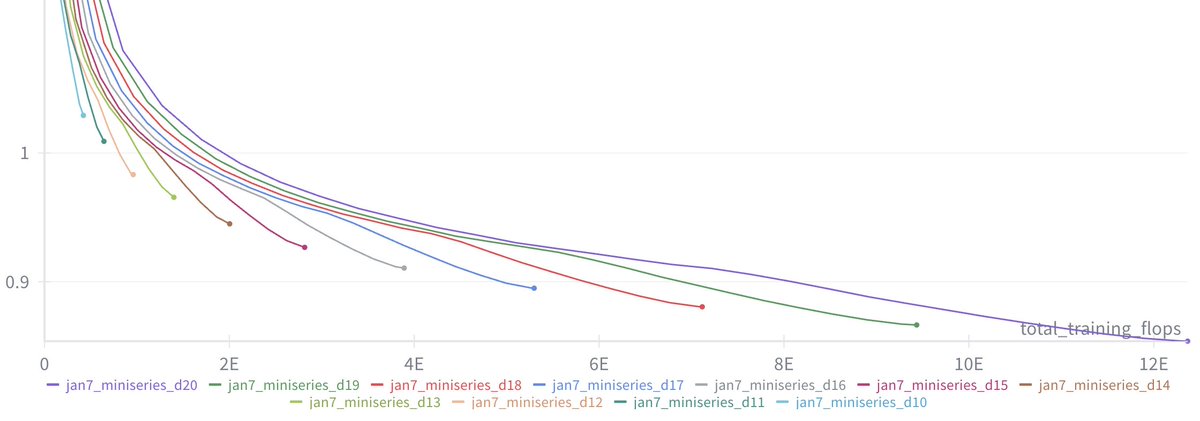
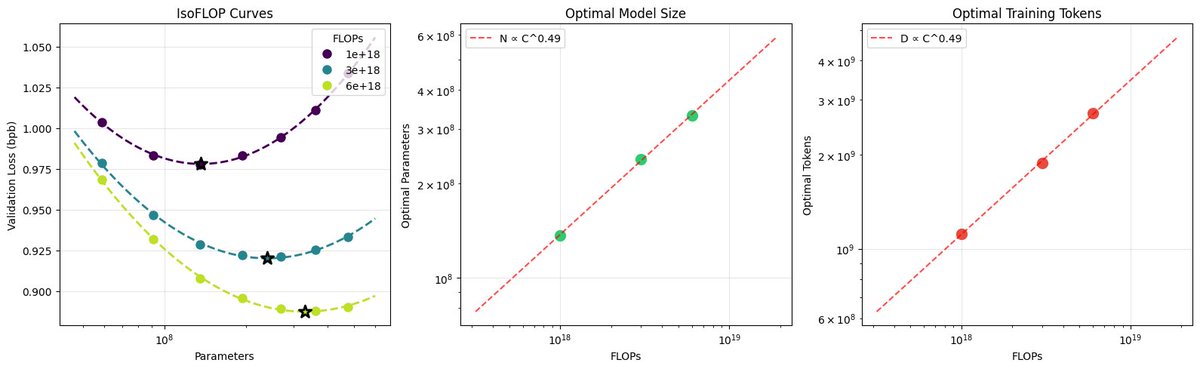
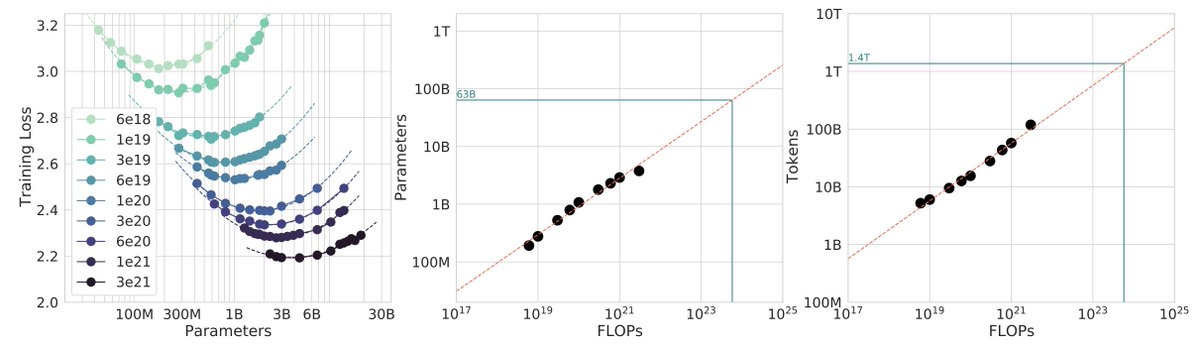
After locally tuning some of the hyperparameters, I swept out a number of models fixing the FLOPs budget. (For every FLOPs target you can train a small model a long time, or a big model for a short time.) It turns out that nanochat obeys very nice scaling laws, basically reproducing the Chinchilla paper plots:
Which is just a baby version of this plot from Chinchilla:
Very importantly and encouragingly, the exponent on N (parameters) and D (tokens) is equal at ~=0.5, so just like Chinchilla we get a single (compute-independent) constant that relates the model size to token training horizons. In Chinchilla, this was measured to be 20. In nanochat it seems to be 8!
Once we can train compute optimal models, I swept out a miniseries from d10 to d20, which are nanochat sizes that can do 2**19 ~= 0.5M batch sizes on 8XH100 node without gradient accumulation. We get pretty, non-itersecting training plots for each model size.
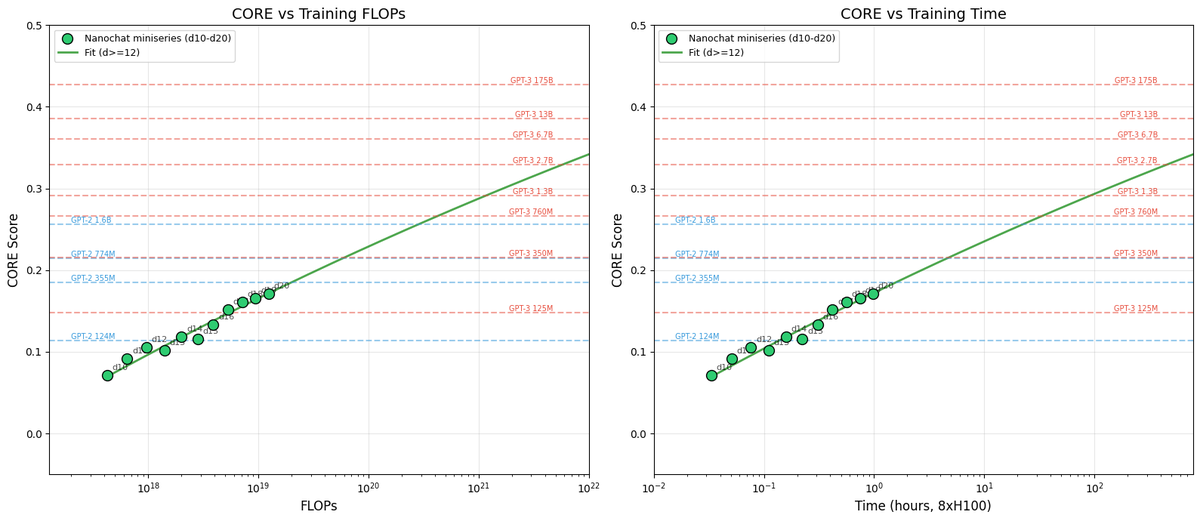
Then the fun part is relating this miniseries v1 to the GPT-2 and GPT-3 miniseries so that we know we're on the right track. Validation loss has many issues and is not comparable, so instead I use the CORE score (from DCLM paper). I calculated it for GPT-2 and estimated it for GPT-3, which allows us to finally put nanochat nicely and on the same scale:
The total cost of this miniseries is only ~$100 (~4 hours on 8XH100). These experiments give us confidence that everything is working fairly nicely and that if we pay more (turn the dial), we get increasingly better models.
TLDR: we can train compute optimal miniseries and relate them to GPT-2/3 via objective CORE scores, but further improvements are desirable and needed. E.g., matching GPT-2 currently needs ~$500, but imo should be possible to do <$100 with more work.
Full post with a lot more detail is here:
https://t.co/na8zVLqWLf
And all of the tuning and code is pushed to master and people can reproduce these with scaling_laws .sh and miniseries .sh bash scripts.
Adamın her postu mini ders gibi. Kısaca, Karpathy, LLM eğitimini "compute" kadranıyla kontrol edilen bir model ailesi olarak kurgulamış ve Chinchilla grafiklerini birebir yeniden üretmişler.
Sadece 100 dolar harcayarak GPT-2/3 ayarında skorlar elde etmişler ve hedef bu maliyeti daha da düşürmekmiş. Açık kaynak LLM eğitimi için de bir yol haritası çıkarmışlar.
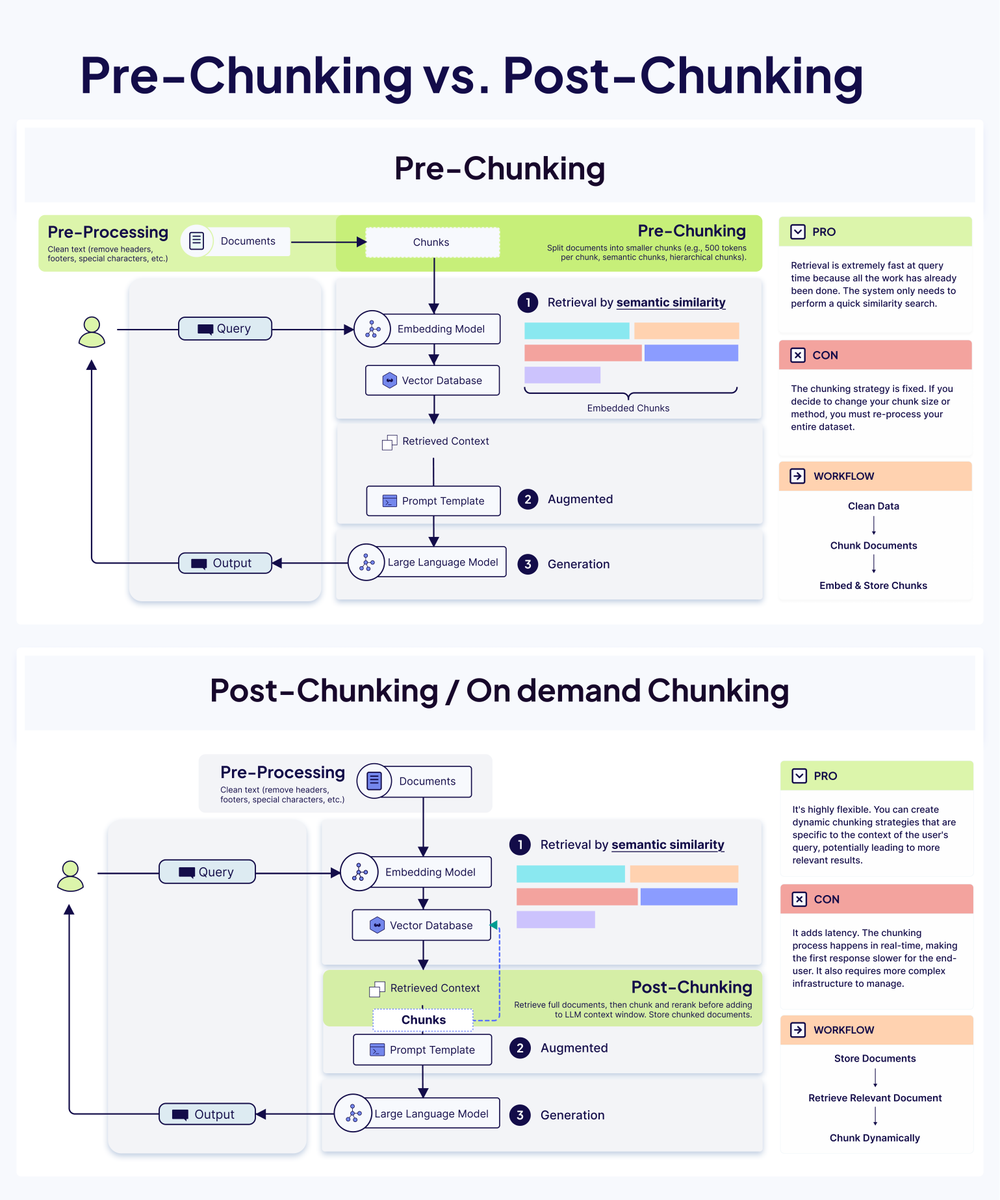
Good context engineering isn’t just 𝘩𝘰𝘸 you chunk.
It’s 𝘸𝘩𝘦𝘯 you chunk.
And that timing choice creates two completely different architectures.
𝗣𝗿𝗲-𝗖𝗵𝘂𝗻𝗸𝗶𝗻𝗴: (the classic way)
Everything happens offline before a user ever sends a query.
𝗪𝗼𝗿𝗸𝗳𝗹𝗼𝘄: clean → chunk → embed → store → fast retrieval
𝗣𝗿𝗼𝘀:
✓ Lightning-fast retrieval
✓ Simple, stable architecture
✓ Predictable performance
𝗖𝗼𝗻𝘀:
⚠️ Locked into your chunking strategy
⚠️ Costly to change chunk sizes
⚠️ Not adaptive to query context
𝗣𝗼𝘀𝘁-𝗖𝗵𝘂𝗻𝗸𝗶𝗻𝗴: (the advanced approach)
Instead of chunking upfront, you chunk after retrieval, based on the actual query.
𝗪𝗼𝗿𝗸𝗳𝗹𝗼𝘄: retrieve doc → chunk dynamically → rerank → send to LLM
𝗣𝗿𝗼𝘀:
✓ Query-aware chunking
✓ More relevant results
✓ Adapts to diverse question types
𝗖𝗼𝗻𝘀:
⚠️ Higher latency
⚠️ More infrastructure
⚠️ More compute per query
𝗪𝗵𝗶𝗰𝗵 𝘀𝗵𝗼𝘂𝗹𝗱 𝘆𝗼𝘂 𝗰𝗵𝗼𝗼𝘀𝗲?
• 𝗣𝗿𝗲-𝗰𝗵𝘂𝗻𝗸𝗶𝗻𝗴 → you need speed + simplicity
• 𝗣𝗼𝘀𝘁-𝗰𝗵𝘂𝗻𝗸𝗶𝗻𝗴 → you need flexibility + relevance
Want to go deeper? The free guide about chunking strategies for context engineering breaks it down 🧡
https://t.co/tIKNrsbWy1