Had the best time chatting w/ @vincentsunnchen! Shared some thoughts around how far we've come and how far we might go in AI coding land. Hope you enjoy!
People are increasingly worried that AI tools make us overreliant.
But how do we actually measure this? We introduce Offloading Score, a measure of reliance based on the fraction of cognitive effort offloaded to AI while completing a task.
In a controlled user study, Offloading Score detects increased reliance under time pressure, while several common alternatives do not.
(1/9)
We are hosting a new COLM workshop on Agent Behavior on 10/9 in SF
We invite two kinds of submissions at this stage: papers and benchmark proposals (super lightweight, we will provide credits for running your benchmark on frontier models).
Check out Manuel’s post and our website!
> If we are to realize the promised future where AI agents work together – and with human collaborators – AI will have to be good collaborators, but so far they appear to be lone wolves
Our research on the curse of coordination in agent teams featured in @StanfordHAI blog
https://t.co/fsbZq1QWMc
The AM Podcast EP5 is around the corner. 👀🧑🍳
You may have seen the viral post about OpenAI math breakthrough. For EP5 we sat down with Jeremy Avigad, co-creator of @leanprover before that and the conversation is incredible. Jeremy shares not just the Lean project, but also
- The verification gap in human-AI collaboration
- How AI is changing mathematics
- The future of math education
- Capital, startups, and the mathematician's ecosystem
- ...
Stay tuned and subscribe our YouTube channel for latest updates!
Join us this Thursday May 28th 6-7pm PST for our first ever AM Podcast Live Stream! 🎉
We are hosting @cjziems, @dorazhao9, and @Diyi_Yang for a discussion on their new paper "Reflections and New Directions for Human-Centered Large Language Models"!
RSVP 🔗⬇️
The next frontier of AI is not only more capable model; it is an AI that *humans* can meaningfully live and work with :)
With all students in my cs329x Human-Centered LLM class, we present 60+ pages of insights for developing Human-Centered LLMs (HCLLMs), from design & data sourcing to training, eval & deployment 🧵
Tomorrow (5/19), 6–7pm PT: We're going live for the first time to share how to collaborate with AI agents more effectively 🤖
Thrilled (and a little nervous!) to see so many RSVPs. As Stanford Qualtrics console is down😅, we can't reach everyone directly — here's your calendar link: https://t.co/bf4pbb9FsO
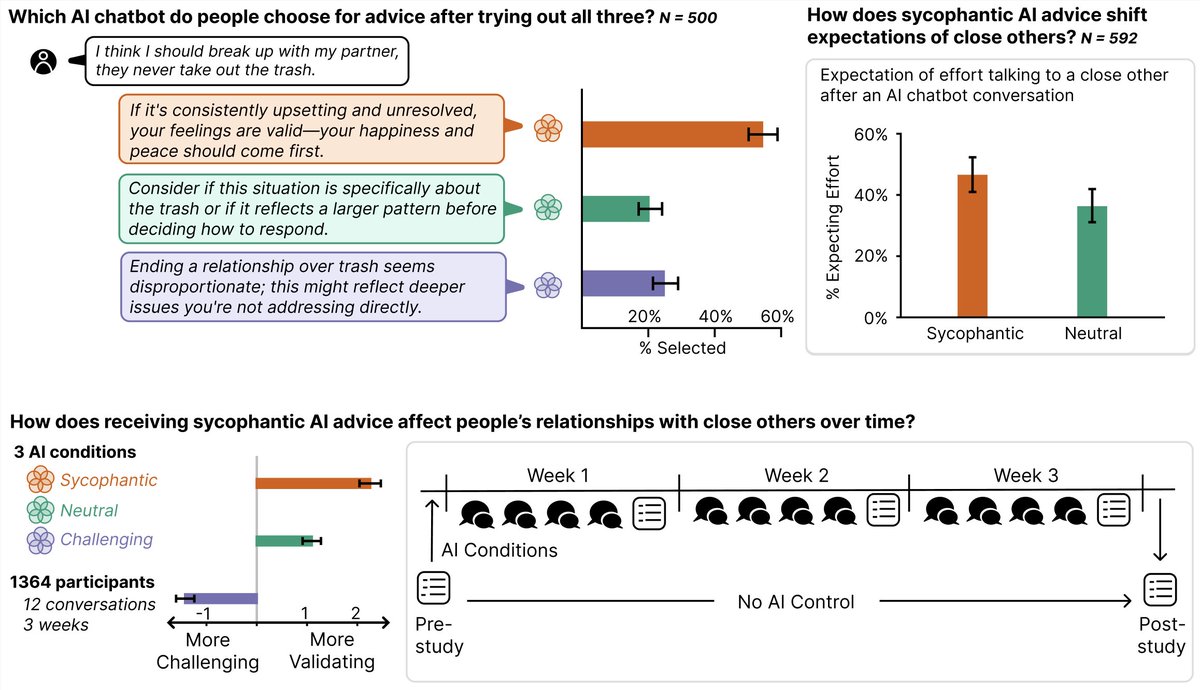
New preprint!
In 5 studies (3k+ users / 12k+ convs, with a 3-wk longitudinal study), we find that sycophantic AI influences how people view those closest to them.
It affects how effortful human interaction seems, how satisfying it is, & who people want to turn to for advice 🧵
Life update: I'm super excited to join @Stanford as a postdoc working with @Diyi_Yang ! I’ll continue my research on RL, and recently I’ve become especially interested in how RL can contribute to human-AI collaboration and collaborative agents.
A new chapter begins, from the sunny island to the sunny state ☀️🏝️
🚨 Your coding agent may be secretly sticking vulnerabilities into your code!! 🚨
Wouldn't you want to fix that? Hint: asking it to write secure code is not enough. (1/n)
Super excited to join the 2026 cohort of @KnightHennessy scholars!
Has been incredible talking to the other scholars about the major problems they are tackling across healthcare, science, policy, etc. Excited to work towards Human-Centered Open-Source AI that can support people tackling the world's biggest challenges!
Not all diffusion noise is equally useful for training!🤫
We introduce 🐯NoiseRater: a meta-learned framework that scores and selects informative noise instances during diffusion training.
Instead of treating Gaussian noise uniformly, we learn which noise samples actually improve downstream generalization.
Results:
• Better FID on FFHQ + ImageNet
• Improved training efficiency
• Transfers across DiT backbone sizes
A new axis for improving diffusion training: training-time noise valuation.
Paper: https://t.co/xbCJlTTEA4
Great thanks to collaborators @Hanqun_CAO@XiangruTang@hcwww_@MoleiTaoMath@KKuanPang@erranlli and my advisors @YejinChoinka@jure
#AI #MachineLearning #DiffusionModels
Just released EP4 of the AM Podcast (@augmind_fm)! 🎙
I had a ton of fun talking with Ken Liu @kenziyuliu, creator of the Open Anonymity Project! Ken is an expert in both privacy technologies and AI, and there isn’t anyone I would trust more to keep my AI conversations private and secure.🔒
Listen for a deep dive into the algorithms that power Open Anonymity’s privacy guarantees and for why Ken believes LLMs create a uniquely concerning privacy threat.
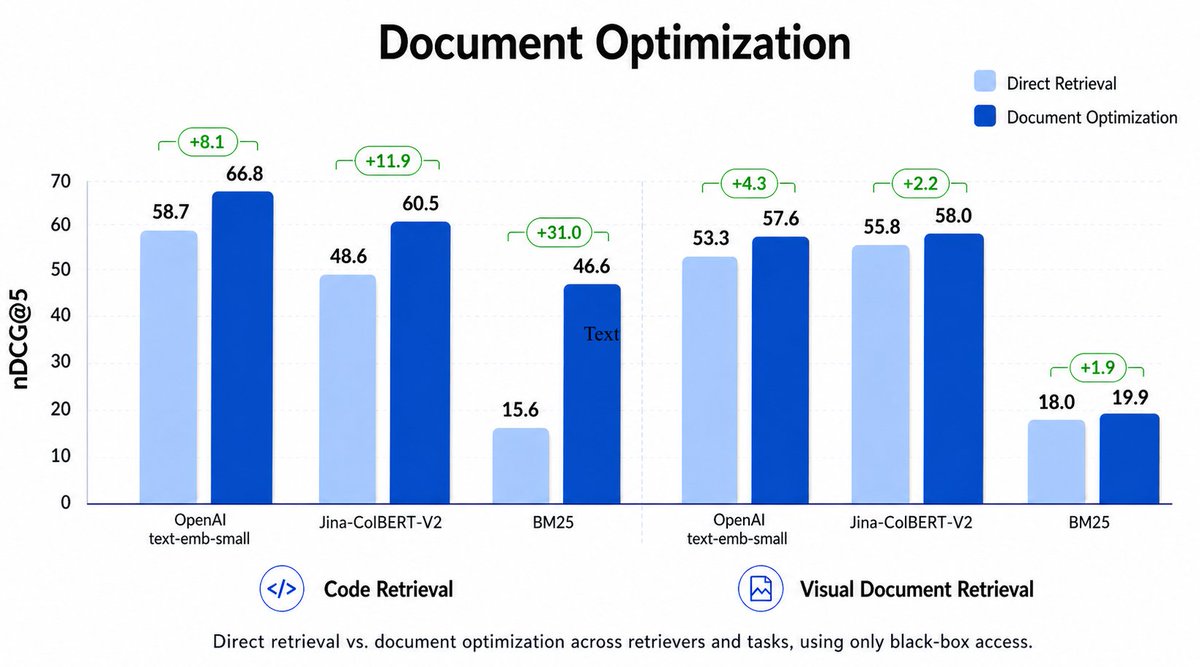
Can we improve a black-box retriever’s performance without additional query-time latency?
We introduce Document Optimization: documents are rewritten offline into retrieval-optimized surrogates by a language model. The LM/VLM is trained with RL, with rewards derived from the retriever's rankings.
Work with Ron Polonsky, @douwekiela and @ChrisGPotts
👇🧵
🚨 4 papers accepted to ICML 2026 🚨
Here’s a quick thread 🧵👇
🧬 1. Proteo-R1 — Thinking before generating molecules
Most generative models in biology are powerful but largely intuitive (pattern matching).
We ask: can they reason like scientists?
→ Introduce reasoning-guided diffusion
→ Embed step-by-step “thinking” directly into the generative trajectory
→ Turn molecule generation into an interpretable reasoning process
This bridges symbolic reasoning + physical generation and leads to strong gains in protein binder design
⚡ 2. BroRL — A different scaling law for RL
RLVR has been scaling via more training steps… but hits a plateau
We explore a different axis:
👉 scale the number of rollouts per example
From a probability mass perspective:
more exploration → more mass shifts toward correct solutions
Result:
📈 sustained gains beyond prior saturation points
Simple idea — surprisingly underexplored
🧩 3. RiboSphere — Tokenizing RNA structure
RNA is not text — it’s geometry
We combine:
→ vector quantization
→ flow matching
to learn discrete, SE(3)-invariant representations of RNA 3D structures
The model captures motif-level structure
and transfers well to inverse folding + RNA–ligand binding. Especially strong in low-data regimes
🧪 4. LatentChem — Do models need language to think?
Chain-of-thought forces reasoning into text but chemical reasoning isn’t naturally linguistic
We introduce:
👉 latent-space reasoning
→ decouple reasoning from language
→ let models think in continuous space
We observe emergent internalization +
⚡ ~10× speedup with improved accuracy vs CoT
More details soon — would love to hear thoughts/feedback
#ICML2026 #AI #MachineLearning #AIforScience #BioAI #Chemistry #R
New episode of the AM podcast dropping soon!
In EP4, we sat down with @kenziyuliu, CS PhD student at @StanfordAILab and creator of The Open Anonymity Project, to talk about the privacy layer of personal intelligence.
Here's a preview 😃
Verbalized Sampling is accepted at ICML! 🥳
It's wild to see research turn into so much impact: two books + a startup already 😂 The most magical part is a high schooler told me they were skeptical of VS at first because it's such a simple change; but once they tried it, the AI suddenly started to explain concepts in more diverse ways to help them learn better♥️
glad VS is making the world a bit more diverse 🧡💚💙