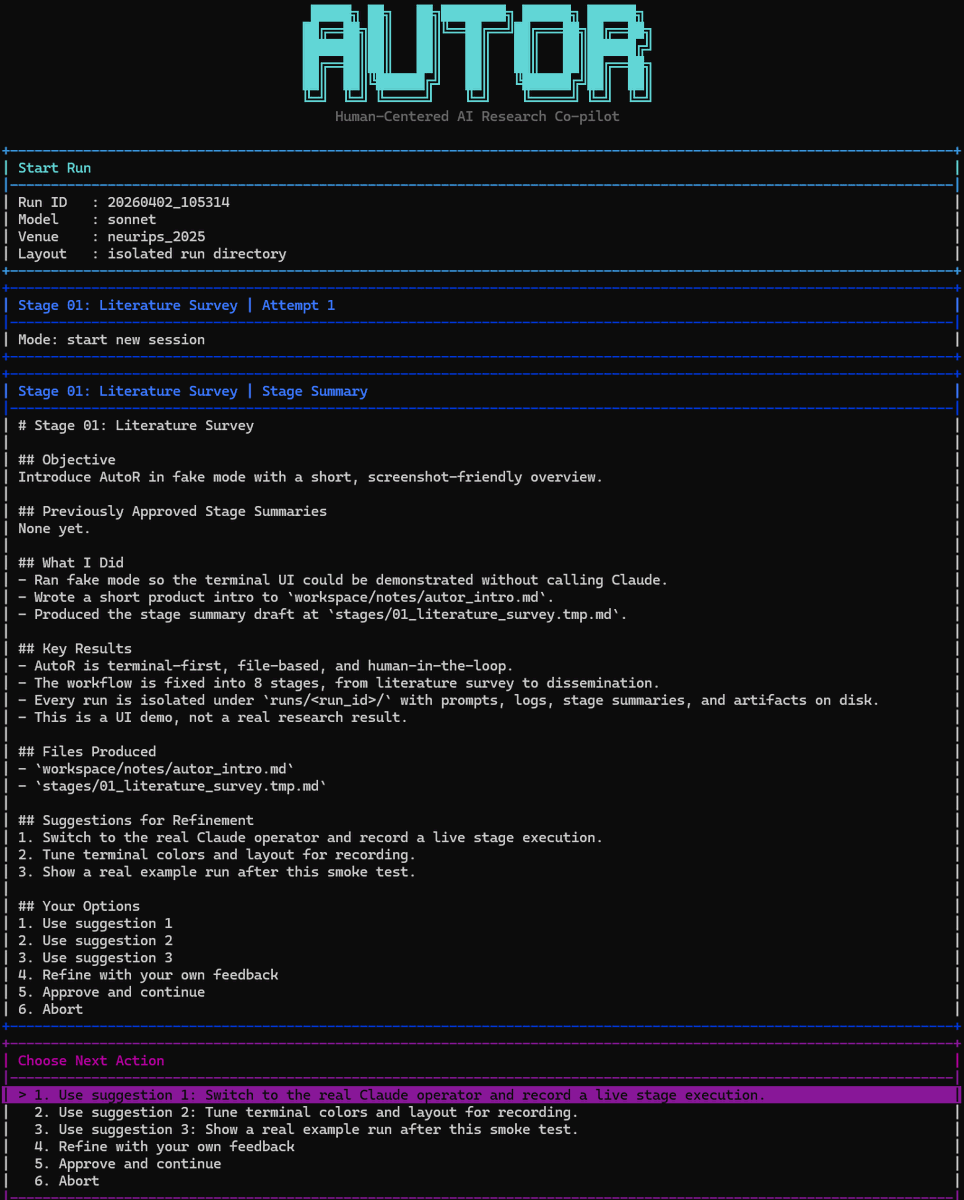
Many autoresearch systems aim for one thing: let AI run end to end and eventually output something that looks like a paper. That idea is exciting, but it misses the harder part of real research. Research rarely fails because execution is too slow. It fails because the question drifts, the experiment does not support the claim, the analysis changes the story, or the writing reveals that the argument is still weak.
https://t.co/jOlzbNZ1Pc
AutoR takes a different path: do not remove humans from research; put them back at the key decision points.
At the center of AutoR is a higher-level research loop. The lower agent loop handles reasoning and tool use. The upper AutoR loop handles stage progression, artifact validation, human approval, and resume / redo / rollback. That is why AutoR is better described as a research harness than as another agent.
That distinction matters. AutoR is not trying to make execution more theatrical. It is trying to make execution usable inside a real research process. The question is not whether the agent can keep working. The question is whether the system knows when to stop, when to ask for judgment, when to verify artifacts, and when to recover after something goes wrong.
Its value is not only in big ideas. It also shows up in smaller practical pieces that matter in day-to-day work: literature organization, automated experimentation, citation verification, artifact indexing, manuscript packaging, and recoverable long runs. You do not just get one long answer. You get one run with code, data, results, figures, writing artifacts, logs, and approval trail stored together.
That is also why AutoR is not optimized for paper-shaped output. It is optimized for verifiable research. The real question is not whether the final manuscript looks polished. The real question is whether every claim can be traced back to inspectable artifacts and human judgment.
A literature survey should leave behind structured notes. An experiment should leave behind machine-readable outputs. A writing stage should leave behind sources, build logs, and citation checks. A long run should be resumable instead of disposable. Those details are what make the system feel real.
That difference matters for anyone who has actually tried to work with long-running AI systems. The problem is rarely that the model cannot produce more text. The problem is that the surrounding workflow does not know how to preserve context, recover from drift, or keep the output tied to real artifacts. AutoR tries to solve that layer.
It does so by combining high-level control with small practical features. A literature pass should leave behind organized notes, not only a narrative summary. An experiment stage should leave behind code, data, and results, not just a paragraph saying what happened. A writing stage should leave behind sources, citation checks, and build artifacts, not just a polished-looking draft. Those details sound small, but they are exactly what separate a real research workflow from a demo.
The same is true for recovery. If a stage fails, or if a reviewer decides the story needs to be narrowed, or if a later stage reveals that an earlier assumption was weak, the system should not become useless. That is why resume, redo-stage, and rollback-stage matter. They are not side features. They are part of making the workflow durable enough for actual research.
So AutoR is not built to let AI blindly run toward a paper. It is built to make research execution human-centered, verifiable, reproducible, and durable over long runs.
This also changes what a successful run means. It means literature is organized, experiments are recorded, writing is checked, artifacts are preserved, and a human can still step in and redirect the process without losing the whole run. That combination is what makes the system useful beyond a single demo.
In that sense, AutoR is not really selling autonomy. It is selling a better contract between AI execution and human judgment. The agent can move quickly, but the researcher still decides what becomes part of the trusted record.
That is also why the smaller operational details matter so much. A system becomes useful when literature is reusable, experiments leave machine-readable traces, writing is checked instead of simply drafted, and the run can be resumed or rolled back instead of discarded. Those are not cosmetic features. They are what make the workflow durable.
So if the question is what AutoR is really trying to build, the answer is straightforward: not a paper generator, not a theatrical autonomous scientist, but a research execution system where AI can do the heavy lifting without taking control away from the human researcher.
That is why AutoR matters even to people who are skeptical of big AI claims. It turns the conversation away from spectacle and back toward workflow quality, artifact quality, and human control.
If AI tools are going to matter in research, they cannot only be good at producing output. They have to be good at producing work that researchers can inspect, steer, revise, and trust. That is the standard AutoR is trying to meet.
That is a narrower promise than full autonomy, but it is a stronger one.
It says the workflow should remain inspectable after the run, not only impressive during the run. That may sound modest, but in practice it is a much harder and more useful standard.
That is why AutoR prioritizes structure, evidence, recovery, and human approval over pure autonomous momentum.
It's Here! #SnowflakeSummit2026 starts TODAY in San Francisco 🌁
Don't forget to check the Unofficial Party & Event List before tonight — RSVP slots fill up fast.
Rooftop Parties, Yacht Experiences, the Ballpark, Busta Rhymes... it's all there!
👉 https://t.co/5edvMr44zp
#SnowflakeSummit #DataCloud #SF
@guohao_li Owning a model is advice for exactly one thing: cost. And if cost is the real problem, the fix is open weights, not finetuning.
For performance, a good harness already gets you there.
Finetuning sits between the two real answers and beats neither. I'd retire it as advice.
🎟️ SOLD OUT at #ISMB2026
Our tutorial IP2: Large Language Models and Agentic AI for Biomedical Informatics is the only sold-out tutorial on the entire ISMB 2026 program. Huge thanks to everyone who grabbed a seat so early.
Organized and taught by @xwang174 (Virginia Tech), @WenqiShi0106 (UT Southwestern), @MarkGerstein (Yale), and me.
We did not want this to be yet another "here is what an LLM is" walkthrough. The real question we want to sit with for 4 hours is bigger:
What does the future of work in bioinformatics look like in the age of LLMs and agents?
On the practical side, the afternoon covers the full stack a working computational biologist actually needs in 2026: The current LLM landscape, open source and commercial, and what each is good for in scientific settings / Prompt design that holds up under biomedical edge cases / Agentic systems that do multi step reasoning, tool use, and workflow orchestration for genuine biomedical tasks / The honest part: hallucination, bias, robustness, reproducibility, and what responsible use looks like in a clinical or scientific context
Then we zoom out. Which parts of a computational biologist's day stay deeply human. Which parts get fully automated in the next 2 years. Where the next generation of bioinformaticians should be placing their bets, and what skills compound versus what skills depreciate.
If you do any kind of biomedical data science, this is the conversation we think the field needs to have right now, and DC in July 2026 feels like the right room to have it in.
📍 Georgetown room, Washington Hilton
📅 Sunday, July 12, 2026, 14:00 to 18:00
ISMB returns to DC for the first time in over 30 years, to the same city where it started in 1993. Looking forward to seeing everyone there. 🧬
Good direction for process-level eval of biomedical agents.
But the related work somehow misses BioCoder (@MarkGerstein), the bioinformatics coding-agent benchmark since 2023. 2,269 tasks from 1,720 peer-reviewed repos, fuzz tested, multi-language.
More specifically: an agent version of BioCoder has been in the OpenHands (ICLR 2025) eval suite for testing coding agents on bioinformatics through context retrieval, self-debugging, and multi-turn reasoning.
Hope to see it in v2.
https://t.co/b3oc2PpBJU
𝗖𝗮𝗻 𝗔𝗜 𝗮𝗴𝗲𝗻𝘁𝘀 𝗽𝗲𝗿𝗳𝗼𝗿𝗺 𝗯𝗶𝗼𝗺𝗲𝗱𝗶𝗰𝗮𝗹 𝗱𝗮𝘁𝗮 𝗮𝗻𝗮𝗹𝘆𝘀𝗶𝘀 𝘁𝗮𝘀𝗸𝘀 𝗯𝗲𝗵𝗶𝗻𝗱 𝗽𝗮𝗽𝗲𝗿𝘀 𝗶𝗻 𝗡𝗮𝘁𝘂𝗿𝗲, 𝗖𝗲𝗹𝗹, 𝗮𝗻𝗱 𝗦𝗰𝗶𝗲𝗻𝗰𝗲?
To find out, we built 𝗕𝗶𝗼𝗺𝗻𝗶𝗕𝗲𝗻𝗰𝗵, a benchmark we co-developed with the original paper authors and 5+year domain experts to grade AI agents the way a peer reviewer reads a paper: scrutinizing methods, reasoning, and every analytical choice, not just the final answer.
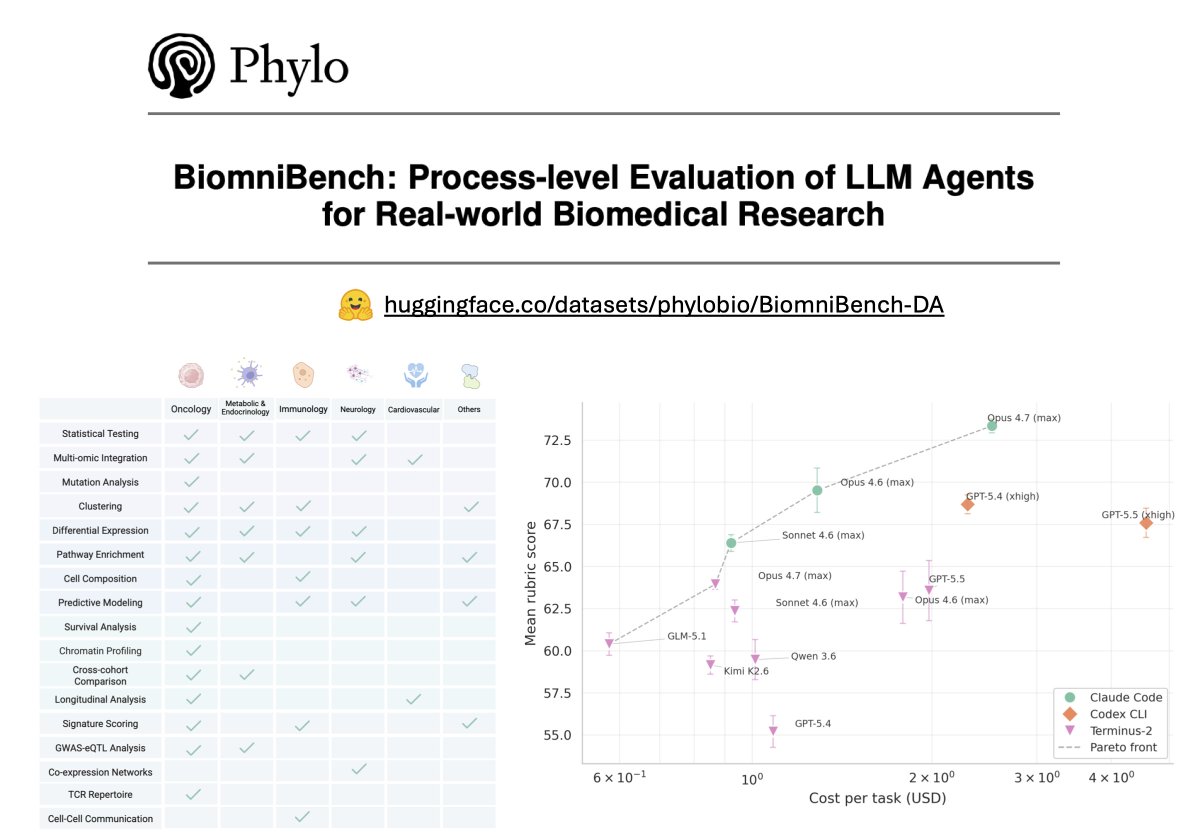
As the first track of this benchmark, 𝗕𝗶𝗼𝗺𝗻𝗶𝗕𝗲𝗻𝗰𝗵-𝗗𝗮𝘁𝗮𝗔𝗻𝗮𝗹𝘆𝘀𝗶𝘀 contains 100 data-analysis tasks drawn directly from 21 published studies in Nature, Cell, Science, Nature Medicine, and other leading journals. Each task hands the agent a real dataset and a research question, then scores its full analytical trajectory against an expert-authored rubric.
What's inside:
- 𝟭𝟬𝟬 𝘁𝗮𝘀𝗸𝘀 𝗮𝗰𝗿𝗼𝘀𝘀 𝟱 𝗱𝗶𝘀𝗲𝗮𝘀𝗲 𝗮𝗿𝗲𝗮𝘀 (𝗼𝗻𝗰𝗼𝗹𝗼𝗴𝘆, 𝗶𝗺𝗺𝘂𝗻𝗼𝗹𝗼𝗴𝘆, 𝗻𝗲𝘂𝗿𝗼𝗹𝗼𝗴𝘆, 𝗺𝗲𝘁𝗮𝗯𝗼𝗹𝗶𝗰 & 𝗲𝗻𝗱𝗼𝗰𝗿𝗶𝗻𝗲, 𝗰𝗮𝗿𝗱𝗶𝗼𝘃𝗮𝘀𝗰𝘂𝗹𝗮𝗿) 𝗽𝗹𝘂𝘀 𝗴𝗲𝗻𝗲𝗿𝗮𝗹 𝗯𝗶𝗼𝗹𝗼𝗴𝘆
- 𝟭𝟳 𝗮𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝗮𝗹 𝘁𝗮𝘀𝗸 𝘁𝘆𝗽𝗲𝘀 (𝗲.𝗴., 𝗚𝗪𝗔𝗦/𝗲𝗤𝗧𝗟 𝗰𝗼𝗹𝗼𝗰𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻, 𝗧-𝗰𝗲𝗹𝗹 𝗿𝗲𝗰𝗲𝗽𝘁𝗼𝗿 𝗿𝗲𝗽𝗲𝗿𝘁𝗼𝗶𝗿𝗲 𝗮𝗻𝗮𝗹𝘆𝘀𝗶𝘀, 𝗰𝗲𝗹𝗹-𝗰𝗲𝗹𝗹 𝗰𝗼𝗺𝗺𝘂𝗻𝗶𝗰𝗮𝘁𝗶𝗼𝗻)
- 𝗔𝗻 𝗲𝘅𝗽𝗲𝗿𝘁-𝗰𝘂𝗿𝗮𝘁𝗲𝗱 𝗿𝘂𝗯𝗿𝗶𝗰 𝗳𝗼𝗿 𝗲𝘃𝗲𝗿𝘆 𝘁𝗮𝘀𝗸, 𝘀𝗰𝗼𝗿𝗶𝗻𝗴 𝟲 𝗱𝗶𝗺𝗲𝗻𝘀𝗶𝗼𝗻𝘀 𝗼𝗳 𝗮𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝗮𝗹 𝗾𝘂𝗮𝗹𝗶𝘁𝘆
- 𝗣𝗿𝗼𝗰𝗲𝘀𝘀-𝗹𝗲𝘃𝗲𝗹 𝗲𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻 𝗼𝗳 𝟵 𝗳𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗟𝗟𝗠𝘀 (𝗚𝗣𝗧-𝟱.𝟱, 𝗖𝗹𝗮𝘂𝗱𝗲 𝗢𝗽𝘂𝘀 𝟰.𝟳, 𝗮𝗺𝗼𝗻𝗴 𝗼𝘁𝗵𝗲𝗿𝘀) 𝗮𝗰𝗿𝗼𝘀𝘀 𝟰 𝗮𝗴𝗲𝗻𝘁 𝗵𝗮𝗿𝗻𝗲𝘀𝘀𝗲𝘀 (𝗖𝗹𝗮𝘂𝗱𝗲 𝗖𝗼𝗱𝗲, 𝗖𝗼𝗱𝗲𝘅 𝗖𝗟𝗜, 𝗧𝗲𝗿𝗺𝗶𝗻𝘂𝘀-𝟮, 𝗚𝗲𝗺𝗶𝗻𝗶 𝗖𝗟𝗜)
Headline results:
- 𝗙𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗺𝗼𝗱𝗲𝗹𝘀 𝗹𝗲𝗮𝗱 𝗮𝘁 𝟳𝟯.𝟯/𝟭𝟬𝟬, 𝘄𝗶𝘁𝗵 𝘀𝘂𝗯𝘀𝘁𝗮𝗻𝘁𝗶𝗮𝗹 𝗵𝗲𝗮𝗱𝗿𝗼𝗼𝗺 𝘁𝗼 𝗶𝗺𝗽𝗿𝗼𝘃𝗲.
- 𝗧𝗵𝗲 𝗮𝗴𝗲𝗻𝘁 𝗵𝗮𝗿𝗻𝗲𝘀𝘀 𝗺𝗮𝘁𝘁𝗲𝗿𝘀 𝗮𝘀 𝗺𝘂𝗰𝗵 𝗮𝘀 𝘁𝗵𝗲 𝗯𝗮𝘀𝗲 𝗺𝗼𝗱𝗲𝗹.
- 𝗔𝗴𝗲𝗻𝘁𝘀 𝗳𝗮𝗹𝗹 𝘀𝗵𝗼𝗿𝘁 𝗼𝗻 𝗯𝗶𝗼𝗹𝗼𝗴𝗶𝗰𝗮𝗹 𝗶𝗻𝘁𝗲𝗿𝗽𝗿𝗲𝘁𝗮𝘁𝗶𝗼𝗻, 𝗺𝗲𝘁𝗵𝗼𝗱 𝘀𝗲𝗹𝗲𝗰𝘁𝗶𝗼𝗻, 𝗮𝗻𝗱 𝘀𝗰𝗶𝗲𝗻𝘁𝗶𝗳𝗶𝗰 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴.
We hope to make 𝗕𝗶𝗼𝗺𝗻𝗶𝗕𝗲𝗻𝗰𝗵 the most helpful benchmark for biologists to understand how AI agents handle real-world biomedical tasks: where they can be trusted, and where they fall short. We're actively expanding our evaluation effort, and would love to engage the broader scientific community on what comes next.
📄 https://t.co/U1rh2QP9Ht
🤗 https://t.co/513AX8AQtJ
Thanks to our amazing @phylo_bio team (Minta Lu, @TuXinming , @serena2z , @TianweiShe , @lecong , @jure , @KexinHuang5 ) and our collaborators at @LaudeInstitute , @Stanford , @Harvard , @PKU1898 , @virginia_tech , Humanlaya Data Lab, Xbench: @alexgshaw , JOU-HO SHIH, Bingqing Zhao, Minjie Shen, Haochen Yang, Jielin Yan, Rongchuan Zhang, Xinze Wu, Tingting Li, Xiaobo Hu, Yuan Jiang, Jiayun Dong, Tao Peng.
Proteo-R1 (ICML 2026), the first reasoning protein foundation model for protein design, is out! 🚀🧬
Most protein design models generate structures without ever *reasoning* about which residues matter. We think that's backwards.
Human protein engineers👩🔧 don't work this way. They identify critical interaction residues first — charged anchors, hydrophobic hotspots, specificity-determining motifs — and only then optimize geometry around those decisions.
━━━━━━━━━━━━━━━━
🔬 THE CORE IDEA
━━━━━━━━━━━━━━━━
A dual-expert architecture that explicitly decouples molecular understanding from geometric generation:
→ ⚡A multimodal LLM (understanding expert) analyzes protein sequences, structures, and text to identify key functional residues governing binding and specificity
→ ⚡A diffusion model (generation expert) then co-designs sequence + structure — but with those residues locked in as hard constraints
━━━━━━━━━━━━━━━━
📐 HOW IT'S TRAINED
━━━━━━━━━━━━━━━━
Three-stage curriculum:
① Multimodal Alignment — freeze the LLM, train projections to bridge ESM-2 + AF3-style structural features into language space
② Structural Reasoning Mid-Training — unfreeze the LLM, teach it residue grounding → pairwise geometry → interface localization → hotspot prediction
③ Joint Reasoning-Guided Design — end-to-end on antibody-antigen complexes. Gradients from the diffusion objective flow back through the reasoning expert.
━━━━━━━━━━━━━━━━
📊 RESULTS
━━━━━━━━━━━━━━━━
Evaluated on simultaneous multi-CDR redesign and the RAbD CDR-H3 benchmark:
✅ Best RMSD & DockQ on RAbD — redesigned H3 loops are geometrically accurate *and* docked well
✅ Lowest backbone dihedral divergence (JSDbb) among all baselines
✅ Reduced intra- and inter-chain steric clashes
✅ Generated sequences score lower perplexity than native antibodies under IgLM & AbLang
✅ Plug-and-play: swapping the diffusion backend to UniMoMo still improves RMSD and IMP
━━━━━━━━━━━━━━━━
💡 WHY IT MATTERS
━━━━━━━━━━━━━━━━
Proteo-R1 isn't just a better antibody design model. It's a blueprint for coupling deliberative LLM reasoning with any physical generative process — interpretable, modular, and backend-agnostic.
📄 Paper: https://t.co/efquYg3O76
💻 Code: https://t.co/Qxm06IZ4xy
🌐 Demo: https://t.co/nkfEWY32OA
Great thanks to my wonderful collaborators Weihao Xuan, Heli Qi, @Hanqun_CAO, Heng-Jui Chang, @KKuanPang@XiangruTang Zehong Wang, @hcwww_ , @KejunYing@lupantech Chiho Im, Seungju Han, @richardxp888@tikgiau. Also appreciate the guidance from advisors @YejinChoinka@jure@erranlli Naoto Yokoya, Masashi Sugiyama.
EvoClaw just dropped the most rigorous long-horizon coding benchmark yet.
6,900 milestones. Continuously evolving codebase. No cherry-picking.
Here’s what actually happened:
1/ The leaderboard
Claude Opus 4.7 xhigh: 39.81%
GPT-5.5 (Codex CLI): 37.77% at $16.43 — fastest runtime, best cost efficiency
Kimi K2.6: 34.69% at $9.96 — open-source, shocking value
GLM-5.1: competitive early, collapses late
2/ GPT-5.5’s precision story
GPT’s classic flaw was high recall, low precision — catching everything but unable to separate signal from noise.
5.5 fixed this hard. Precision nearly matches Opus 4.7 now.
The catch: price jumped significantly to get there.
3/ The Kimi K2.6 surprise
Biggest shock of the round. Kimi reclaims the open-source crown, outperforms GLM 5.1 across long-horizon tasks, and straight up beats GPT 5.4.
The tradeoff: it’s verbose. ~2x the turns of GLM 5.1. Painful to watch, but the extra iteration pays off in score.
More importantly — Kimi holds steady late game while GLM falls off a cliff after milestone 7.
4/ What Opus 4.7’s gains actually reveal
Opus 4.7 beats Opus 4.6 and GPT-5.5 mostly on early-stage tasks.
The EvoClaw team’s read: Mythos distillation primarily improved memorization, not deep reasoning.
Memorization isn’t useless. But it doesn’t compound at scale.
5/ The universal cliff
Every model degrades sharply past milestone 7.
Top scores: 48-74% on milestones 1-3. Drop to 15-24% on milestones 11+.
Long-horizon coding is a different regime entirely. Memory, planning, and cross-context consistency are the bottleneck — not raw intelligence.
This is the benchmark that actually stress-tests what agentic coding systems are made of.
https://t.co/1INtPLYV2r
Which model is the best for coding? GPT-5.5 vs Opus 4.7 vs Kimi K2.6 vs GLM 5.1
We just updated the EvoClaw long-horizon continuous coding leaderboard. This round: the overall champs (GPT-5.5 xhigh & Opus 4.7 xhigh) vs the open-source heavyweights (Kimi K2.6 & GLM 5.1).
We built research tooling for years optimizing for human reviewers. ARA asks: what if we optimized for AI agents instead?
Executable code, full specs, preserved failure traces. This is what reproducibility actually looks like.
Honored to be part of this team! 🙏
My bet: in the near future, 80%⬆️ of CS research will be done by AI in collaboration with humans. However, today's research ecosystem is still built around the human, not the AI scientist.
For example, the 8-page paper PDF is a lossy compression of months of branching exploration into a linear story, optimized for a human reviewer to skim in 30 minutes. It hides two structural taxes:
📖 Storytelling Tax — failures, rejected hypotheses, and dead ends get stripped. On RE-Bench (24,008 runs, 21 frontier models), failed runs = 90.2% of total compute cost, with a 113× median failed-to-success token ratio. Every lab independently rediscovers the same dead ends.
🔧 Engineering Tax — the gap between reviewer-sufficient prose and agent-sufficient spec. Across 8,921 PaperBench requirements (23 ICML'24 papers), only 45.4% are fully specified in the PDF. The rest is tacit lab knowledge. Tolerable when readers were human. Critical now that agents read, reproduce, and extend.
We propose ARA: the Agent-Native Research Artifact — replace the narrative PDF with an agent-executable package, in 4 layers:
🧠 structured scientific logic
⚙️ executable code w/ full specs
🌳 exploration graph (every failure preserved)
📊 evidence grounding every claim
5 papers accepted at #ICML2026 🎉
Especially proud of two where I served as last/corresponding author: LatentChem and EvoClaw (formerly DevEvol). Quick rundown of what we found, plus the other three at the end.
------------------------------------------------------
🧪 LatentChem: From Textual CoT to Latent Thinking in Chemical Reasoning
TL;DR: chemistry does not want to be written down. It wants to be thought in latent space.
Forcing chemical logic through discrete language tokens creates a modality mismatch. Chemistry is inherently continuous and structural, language is not. So we built a reasoning interface that thinks in continuous latent space instead of generating textual CoT.
The most surprising finding: spontaneous internalization. Under outcome-only optimization, the model voluntarily abandons verbose textual derivations and shifts reasoning into the latent manifold. It self-selects continuous computation as a more native substrate for chemical logic.
📊 Results across ChemCoTBench, Mol-Instructions, ChEBI-20, and ChemLLMBench:
- 59.88% non-tie win rate against a strong CoT baseline
- 5.96x wall-clock speedup
- 10.84x reduction in reasoning step overhead
Strongest gains land on open-ended generative tasks like molecule optimization.
------------------------------------------------------
💻 EvoClaw: Evaluating AI Agents on Continuous Software Evolution
TL;DR: frontier coding agents look great on isolated tasks. Drop them into a real evolving codebase and resolve rate collapses to roughly 10%.
Coding benchmarks today score isolated, independent tasks. Real software grows through long, dependency-constrained sequences of changes. We wanted to see what happens when agents face that reality.
We built DeepCommit, an automated pipeline that reconstructs verifiable software evolution trajectories from git histories as Milestone DAGs. Then we ran frontier coding agents in streaming mode over evolving codebases, scoring each milestone on new functionality acquisition and regression preservation.
📉 The gap between snapshot and streaming evaluation is brutal:
- Even frontier models reach only about 35% Score and 10% Resolve Rate in continuous environments
- A snowball effect dominates, where early regressions accumulate and block downstream milestones
- Recall keeps growing while precision saturates early, so unresolved errors propagate forward
💡 Shared lesson from both papers: how we evaluate AI agents shapes what we think they can do. Static snapshots overestimate. Linguistic CoT can be the wrong substrate for structure-heavy domains.
------------------------------------------------------
Also accepted at ICML 2026 with my fantastic collaborators:
- InteractComp: evaluating search agents on ambiguous queries that require clarification rather than guesswork
- Proteo-R1: thinking foundation models for de novo protein binder design
- Which LLM Multi-Agent Protocol to Choose? a systematic study of how protocol choice shapes multi-agent system behavior
Huge thanks to all coauthors and students who carried these papers across the finish line 🙏
Scoop! Stanford prof James Zou is raising money for a new AI lab at a ~$1 billion valuation.
His startup, which will build artificial intelligence models for research on the human body, is aiming for a ~$100 million raise, sources tell me. https://t.co/56ZVRm45dp
Many autoresearch systems aim for one thing: let AI run end to end and eventually output something that looks like a paper. That idea is exciting, but it misses the harder part of real research. Research rarely fails because execution is too slow. It fails because the question drifts, the experiment does not support the claim, the analysis changes the story, or the writing reveals that the argument is still weak.
https://t.co/jOlzbNZ1Pc
AutoR takes a different path: do not remove humans from research; put them back at the key decision points.
At the center of AutoR is a higher-level research loop. The lower agent loop handles reasoning and tool use. The upper AutoR loop handles stage progression, artifact validation, human approval, and resume / redo / rollback. That is why AutoR is better described as a research harness than as another agent.
That distinction matters. AutoR is not trying to make execution more theatrical. It is trying to make execution usable inside a real research process. The question is not whether the agent can keep working. The question is whether the system knows when to stop, when to ask for judgment, when to verify artifacts, and when to recover after something goes wrong.
Its value is not only in big ideas. It also shows up in smaller practical pieces that matter in day-to-day work: literature organization, automated experimentation, citation verification, artifact indexing, manuscript packaging, and recoverable long runs. You do not just get one long answer. You get one run with code, data, results, figures, writing artifacts, logs, and approval trail stored together.
That is also why AutoR is not optimized for paper-shaped output. It is optimized for verifiable research. The real question is not whether the final manuscript looks polished. The real question is whether every claim can be traced back to inspectable artifacts and human judgment.
A literature survey should leave behind structured notes. An experiment should leave behind machine-readable outputs. A writing stage should leave behind sources, build logs, and citation checks. A long run should be resumable instead of disposable. Those details are what make the system feel real.
That difference matters for anyone who has actually tried to work with long-running AI systems. The problem is rarely that the model cannot produce more text. The problem is that the surrounding workflow does not know how to preserve context, recover from drift, or keep the output tied to real artifacts. AutoR tries to solve that layer.
It does so by combining high-level control with small practical features. A literature pass should leave behind organized notes, not only a narrative summary. An experiment stage should leave behind code, data, and results, not just a paragraph saying what happened. A writing stage should leave behind sources, citation checks, and build artifacts, not just a polished-looking draft. Those details sound small, but they are exactly what separate a real research workflow from a demo.
The same is true for recovery. If a stage fails, or if a reviewer decides the story needs to be narrowed, or if a later stage reveals that an earlier assumption was weak, the system should not become useless. That is why resume, redo-stage, and rollback-stage matter. They are not side features. They are part of making the workflow durable enough for actual research.
So AutoR is not built to let AI blindly run toward a paper. It is built to make research execution human-centered, verifiable, reproducible, and durable over long runs.
This also changes what a successful run means. It means literature is organized, experiments are recorded, writing is checked, artifacts are preserved, and a human can still step in and redirect the process without losing the whole run. That combination is what makes the system useful beyond a single demo.
In that sense, AutoR is not really selling autonomy. It is selling a better contract between AI execution and human judgment. The agent can move quickly, but the researcher still decides what becomes part of the trusted record.
That is also why the smaller operational details matter so much. A system becomes useful when literature is reusable, experiments leave machine-readable traces, writing is checked instead of simply drafted, and the run can be resumed or rolled back instead of discarded. Those are not cosmetic features. They are what make the workflow durable.
So if the question is what AutoR is really trying to build, the answer is straightforward: not a paper generator, not a theatrical autonomous scientist, but a research execution system where AI can do the heavy lifting without taking control away from the human researcher.
That is why AutoR matters even to people who are skeptical of big AI claims. It turns the conversation away from spectacle and back toward workflow quality, artifact quality, and human control.
If AI tools are going to matter in research, they cannot only be good at producing output. They have to be good at producing work that researchers can inspect, steer, revise, and trust. That is the standard AutoR is trying to meet.
That is a narrower promise than full autonomy, but it is a stronger one.
It says the workflow should remain inspectable after the run, not only impressive during the run. That may sound modest, but in practice it is a much harder and more useful standard.
That is why AutoR prioritizes structure, evidence, recovery, and human approval over pure autonomous momentum.
Most chemical LLMs still reason in the same way: they write a long chain-of-thought in natural language, then produce an answer. That paradigm has become so common that we rarely stop to ask whether language is actually the right computational medium for chemistry. LatentChem starts from a sharper hypothesis: chemical reasoning is fundamentally continuous and structural, while natural language is discrete, low-bandwidth, and often misaligned with how chemical computation really unfolds.
If you have worked on molecule optimization or reaction prediction, you have probably seen the failure mode already. The model writes a convincing paragraph about sterics, functional groups, reactivity, or binding affinity, and then outputs a molecule that does not actually match its own reasoning. The explanation sounds plausible. The structure does not. We believe that this is not just a prompting issue. It is a representation issue.
The Core Problem: Chemistry Is Not Naturally Linguistic
Our central claim is deceptively simple: chemical reasoning is better understood as movement through a continuous, high-dimensional property landscape than as a sequence of verbalized symbolic steps. Tasks like optimizing LogP, modifying a scaffold, improving solubility, or searching for better receptor affinity are not naturally sentence-shaped operations. They are structural updates over a continuous space. When we force that process into discrete natural-language tokens, we introduce what we call a continuity–discretization gap.
That framing matters because it changes what CoT is supposed to be. In this view, textual CoT is not necessarily where reasoning truly happens. It may just be a surface-level description of a computation that would be better carried out somewhere else. LatentChem is interesting precisely because it does not try to make textual CoT more elegant. It asks whether chemistry should be reasoned through language at all.
What LatentChem Actually Changes
LatentChem decouples reasoning from generation. The system first uses a ChemAdapter to compress molecular features from the encoder into a fixed number of ChemTokens, which are prepended to the text prompt as a soft prompt. It then inserts a latent thinking phase where the model generates a sequence of continuous latent thought vectors instead of spelling out every intermediate reasoning step in words.
The key architectural twist is the ChemUpdater. Rather than treating the molecule as a static embedding that gets read once and then forgotten, LatentChem allows each latent thought to re-query the molecular representation through cross-attention. In other words, the model is not just thinking over a frozen molecular snapshot. It can keep looking back at the molecule, shifting attention toward different substructures as reasoning unfolds. A Latent Projector then maps the hidden state back into the input embedding space so the next latent step can continue the loop.
This is what makes LatentChem more than “COCONUT for chemistry.” Generic latent reasoning moves computation away from text, but LatentChem also makes molecular perception active during the reasoning process itself. That distinction is one of the main reasons the method feels natively chemical rather than merely language-model-centric.
The Most Interesting Result: The Model Chooses to Stop Writing CoT
This is the result that makes the work memorable.
After reinforcement learning, LatentChem often stops generating intermediate textual reasoning altogether. Instead, it uses its latent thinking budget, emits only a trivial transition artifact like “.” or “:”, and then directly outputs the final answer. We call this spontaneous internalization. The model is not forced to suppress CoT by a handcrafted penalty on length. It simply discovers that, when only task success matters, internal latent computation is the better strategy.
That is a much stronger claim than “latent reasoning works.” It suggests that, for chemical tasks, once the model is given the freedom to choose its own computational pathway, it often prefers continuous latent computation over explicit linguistic derivation. The shift is not stylistic. It is functional.
A Flexible Strategy, Not a Hard Rule
There is a second result that makes the story much richer.
If LatentChem had merely learned the hard rule “do not write CoT,” then reducing the latent thinking budget should not bring textual reasoning back. But that is not what happens. When the latent budget is compressed enough, the model begins to re-externalize reasoning into text. In the budget stress tests, once the allowed latent steps become scarce, explicit CoT length rises sharply.
That finding is subtle but important. It means the model is not learning an ideology against CoT. It is learning a resource-allocation strategy. When internal latent capacity is abundant, reasoning stays mostly latent. When that internal budget becomes tight, the model spills reasoning back out into language. We describe this as a kind of hydraulic trade-off between latent and explicit reasoning pathways.
This is, to me, one of the deepest implications of the work: explicit CoT may not be reasoning itself. It may be one possible externalization of reasoning, brought back online when the model needs extra room.
Results: Better Performance With Lower Reasoning Step Overhead
The benchmark results are strong.
On ChemCoTBench, LatentChem achieves a 59.88% non-tie win rate against the strong explicit CoT baseline. Across the broader suite, it reaches 85.26% on ChEBI-20, 55.58% on ChemLLMBench, and 49.88% on Mol-Instructions, where it is roughly at parity. The gains are especially pronounced on open-ended generative tasks, which is exactly where latent exploration of the chemical manifold should matter most.
The efficiency story is just as important. LatentChem delivers an average 10.84× reduction in reasoning step overhead across benchmarks by compressing verbose explicit CoT into compact latent computation. On reaction tasks, the reduction in reasoning step overhead reaches 29.9×; on molecule optimization tasks, it reaches 28.4×.
Why This Matters for AI Scientist
The reason this work feels larger than chemistry is that chemistry is a very unforgiving test case. You can write a beautiful paragraph about a molecule and still output the wrong structure. That makes chemistry a good domain for exposing the difference between explanation and computation.
Seen from that angle, LatentChem suggests a broader possibility for AI Scientist systems: maybe explicit natural-language CoT is often an interface layer rather than the native substrate of reasoning. LatentChem is not just a better chemistry model; it is a building block for scientific systems that need to search, design, plan, and verify in structured spaces where language is useful for communication but not necessarily ideal for the heavy lifting itself.
That is a meaningful shift in how we talk about reasoning models. The interesting question may no longer be “How do we get models to write better CoT?” It may be “What medium should the reasoning happen in before anything is written down at all?”
Coda
LatentChem is not anti-reasoning.
It is anti-misplaced reasoning.
It does not show that chemistry needs less thought. It shows that chemistry may need thought in a medium that matches the structure of the problem. And once the model is allowed to optimize for actual task success instead of linguistic ceremony, it often decides that the best place for the main computation is not language, but latent space.
For me, that is the real significance of the work.
The future of scientific AI may not belong to models that narrate every intermediate step.
It may belong to models that reason where the problem actually lives and only translate back into language at the end.