1/6 Hot take: Scaffold is Structured Test-Time Scaling.
Every agent scaffold you've ever built — sub-agent spawning, file-based context passing, test-then-retry loops — is doing structured test-time scaling.
And soon, the scaffold becomes the model, the model becomes the scaffold.
We wrote a unified framework to explain why it works. w/ @guanghao_ye
Check more detail:
https://t.co/9Qq8dV90cY
1/ We built the Genomics × AI blog so the genomics + ML community can share work fast and actually discuss it — incremental results, negative results, tutorials — without waiting on a publisher. Posts are live, more landing over the coming weeks: https://t.co/a4YY6avrda
The training data market has exploded for LLMs and bio foundation models are next.
But biological data is extremely complex and requires a data generation playbook that prioritizes quality over immediate scale.
@_DimensionCap Research article live now!
https://t.co/3CqSYADLJP
🚀 We are introducing PerturbPair (with @TakaKud0) — a platform that combines parallel Perturb-seq and optical pooled screening (OPS/PerturbView) in primary cells to systematically map at massive scale how genetic perturbations reshape cellular states across modalities.
With wonderful collaborators @TakaKud0, @AnaMeireles, @AntRios, @jchuetter, @MinOta, @ORozenblattRosen, @LeviAGarraway, @KGeiger, @avtarsingh, @jkpritch, and Aviv Regev.
Paper link: https://t.co/fnSUymW95s
The historic 90th CSH Symposium on AI in Biology at @CSHL has come to an end. After a decade of remarkable advances in AI x Bio, aspirations have become bolder than ever. The future looks bright but much work remains to turn hype into real-world progress. Thanks to all speakers!
Also shouting out @zhou_jian who did a lot of pioneering work on sequence-to-function models. DeepSEA is one of the earliest papers in this field, and he continues to make great contributions to the space
Just want to give a shout-out to David Kelley @drklly who I think often does not get the credit he deserves (outside our core community).
I want to highlight why I think he is such a fantastic scientist and leader in regulatory genomics. 1/
Just want to give a shout-out to David Kelley @drklly who I think often does not get the credit he deserves (outside our core community).
I want to highlight why I think he is such a fantastic scientist and leader in regulatory genomics. 1/
Huge congratulations on both incredible milestones, Prof @weijie444 A well-deserved promotion to Full Professor, and a great win for OpenAI. Highly anticipating the new breakthrough models to come! 🎉
Personal update: I've joined OpenAI while on leave from Wharton. After a decade away, glad to be back in the Bay Area and train AI models here!
One more thing, I've been promoted to full professor, a decade-long journey made possible by many, especially my students.
haha - my slide at the 90th @CSHLaboratory Symposium on AI in biology got a spontaneous applause. It was inspired by Sir Michael Atiyah's quote about algebra and geometry:
"Algebra is the offer made by the devil to a mathematician. The devil says, 'I will give you this powerful machine...all you need to do is give up your soul: give up geometry...’ The danger to our soul is there... when you pass into algebraic calculation,...you stop thinking geometrically, you stop thinking about meaning."
In the slide below:
algebra -> AI
mathematician -> biologist
geometry -> understanding
ESMC-6B, ESMFold2, and ESMFold2-Fast are now live on Biomni Lab.
Through our collaboration with @biohub, researchers can now ask Biomni to:
→ generate protein embeddings
→ run zero-shot variant effect prediction
→ predict structures from sequences
→ compare variants against structural and disease-relevant context
https://t.co/3lOQsjtkla
Start using these models on Biomni Lab’s HPC cluster today!
Great benchmark on a highly important topic!
Do you plan to test Codex + GPT-5.5 (XHigh) and Claude Code + Opus 4.7 (Max Thinking) next? @niloofar_mire
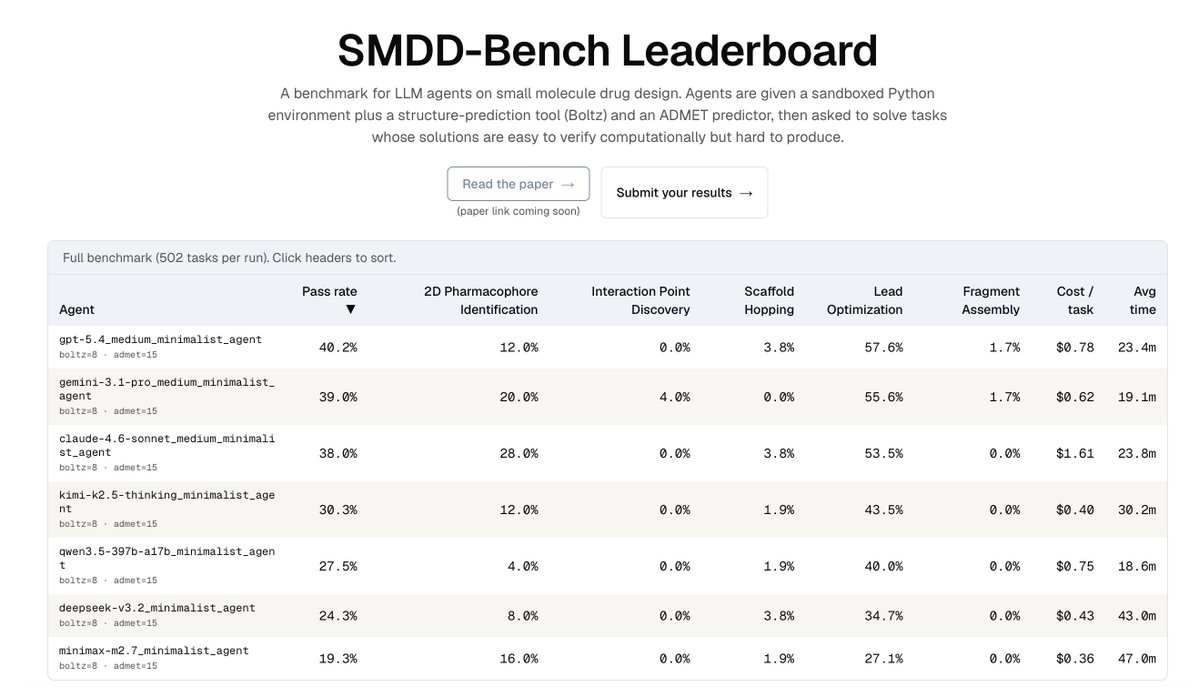
🧬New agentic AI-for-science benchmark: SMDD-Bench!
Can frontier LLM agents actually do small-molecule drug design? Real medicinal chemistry — not single-turn QA, not toy property prediction. Long-horizon, multi-turn, tool-using, with strict oracle budgets.
We release 502 agentic tasks across 5 real drug-design workflows (pharmacophore ID, scaffold hopping, lead optimization, fragment assembly, interaction point discovery), every one guaranteed-solvable via a hidden witness molecule. Agents get a Python sandbox, 8 Boltz2 calls, 15 ADMET-AI calls, no internet — and have to plan across dozens of turns to spend that budget wisely.
Result: GPT-5.4 and Gemini 3.1 Pro are neck-and-neck at the top (40.2% vs 39.0%), Claude Sonnet 4.6 right behind at 38%. Open-source models trail meaningfully. Even the best agents fail >60% of the time.
🧵 below
I tried the Edison system developed by the first team (futurehouse) and it was barely usable. Perhaps they have improved but it would be a long way from replacing scientists.
Very interesting. Three papers on agentic Science were just published in Nature today.
Been building in this exact space for a while now—my PhD thesis title is literally: "From AI for Genomics to Agentic Science." 🧐
More to come. 🚀
AI agents will fundamentally change how we do science—but first, we need to understand and measure their true capabilities. 🧬🤖
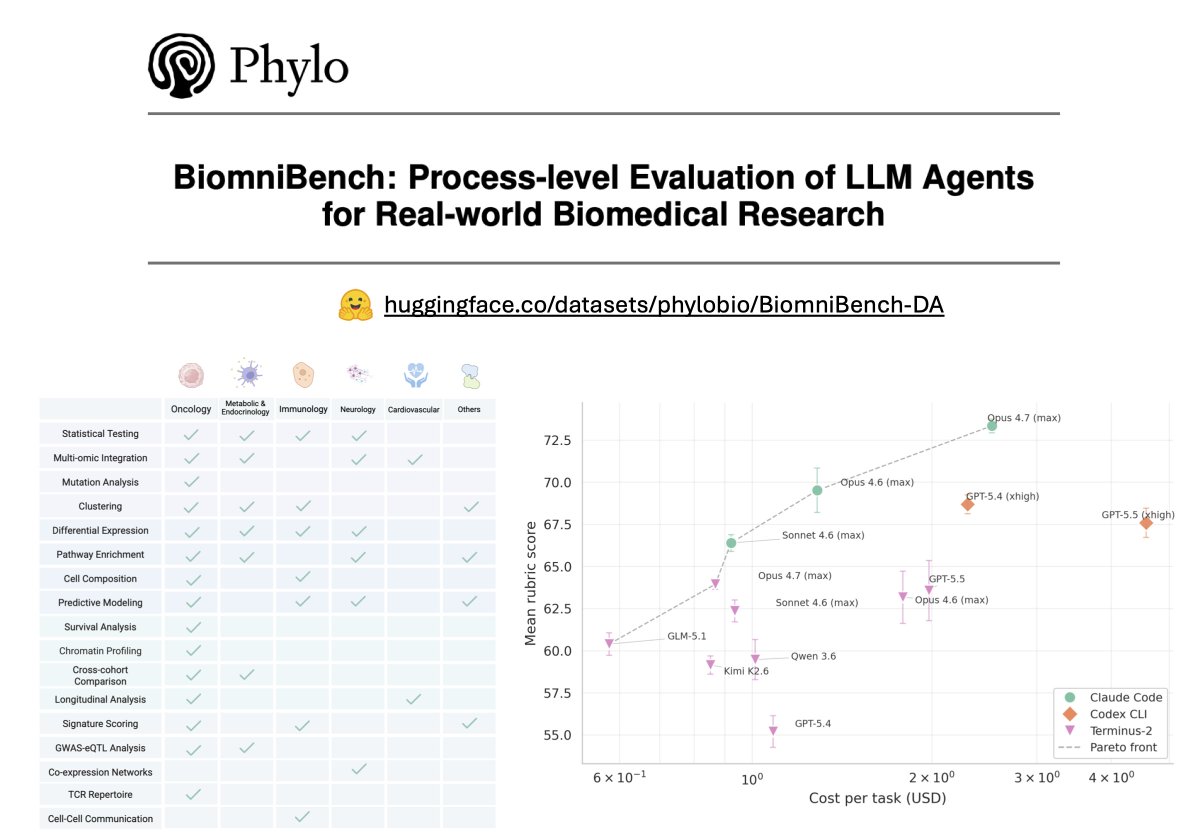
So proud to release BiomniBench! We @phylo_bio worked directly with domain experts and original authors to build 100 real-world data analysis tasks from leading journals like Nature, Science, and Cell.
We’ve released the full public set (tasks + expert rubrics) on HuggingFace for the community. Super excited for the future of agentic science! 👇
𝗖𝗮𝗻 𝗔𝗜 𝗮𝗴𝗲𝗻𝘁𝘀 𝗽𝗲𝗿𝗳𝗼𝗿𝗺 𝗯𝗶𝗼𝗺𝗲𝗱𝗶𝗰𝗮𝗹 𝗱𝗮𝘁𝗮 𝗮𝗻𝗮𝗹𝘆𝘀𝗶𝘀 𝘁𝗮𝘀𝗸𝘀 𝗯𝗲𝗵𝗶𝗻𝗱 𝗽𝗮𝗽𝗲𝗿𝘀 𝗶𝗻 𝗡𝗮𝘁𝘂𝗿𝗲, 𝗖𝗲𝗹𝗹, 𝗮𝗻𝗱 𝗦𝗰𝗶𝗲𝗻𝗰𝗲?
To find out, we built 𝗕𝗶𝗼𝗺𝗻𝗶𝗕𝗲𝗻𝗰𝗵, a benchmark we co-developed with the original paper authors and 5+year domain experts to grade AI agents the way a peer reviewer reads a paper: scrutinizing methods, reasoning, and every analytical choice, not just the final answer.
As the first track of this benchmark, 𝗕𝗶𝗼𝗺𝗻𝗶𝗕𝗲𝗻𝗰𝗵-𝗗𝗮𝘁𝗮𝗔𝗻𝗮𝗹𝘆𝘀𝗶𝘀 contains 100 data-analysis tasks drawn directly from 21 published studies in Nature, Cell, Science, Nature Medicine, and other leading journals. Each task hands the agent a real dataset and a research question, then scores its full analytical trajectory against an expert-authored rubric.
What's inside:
- 𝟭𝟬𝟬 𝘁𝗮𝘀𝗸𝘀 𝗮𝗰𝗿𝗼𝘀𝘀 𝟱 𝗱𝗶𝘀𝗲𝗮𝘀𝗲 𝗮𝗿𝗲𝗮𝘀 (𝗼𝗻𝗰𝗼𝗹𝗼𝗴𝘆, 𝗶𝗺𝗺𝘂𝗻𝗼𝗹𝗼𝗴𝘆, 𝗻𝗲𝘂𝗿𝗼𝗹𝗼𝗴𝘆, 𝗺𝗲𝘁𝗮𝗯𝗼𝗹𝗶𝗰 & 𝗲𝗻𝗱𝗼𝗰𝗿𝗶𝗻𝗲, 𝗰𝗮𝗿𝗱𝗶𝗼𝘃𝗮𝘀𝗰𝘂𝗹𝗮𝗿) 𝗽𝗹𝘂𝘀 𝗴𝗲𝗻𝗲𝗿𝗮𝗹 𝗯𝗶𝗼𝗹𝗼𝗴𝘆
- 𝟭𝟳 𝗮𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝗮𝗹 𝘁𝗮𝘀𝗸 𝘁𝘆𝗽𝗲𝘀 (𝗲.𝗴., 𝗚𝗪𝗔𝗦/𝗲𝗤𝗧𝗟 𝗰𝗼𝗹𝗼𝗰𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻, 𝗧-𝗰𝗲𝗹𝗹 𝗿𝗲𝗰𝗲𝗽𝘁𝗼𝗿 𝗿𝗲𝗽𝗲𝗿𝘁𝗼𝗶𝗿𝗲 𝗮𝗻𝗮𝗹𝘆𝘀𝗶𝘀, 𝗰𝗲𝗹𝗹-𝗰𝗲𝗹𝗹 𝗰𝗼𝗺𝗺𝘂𝗻𝗶𝗰𝗮𝘁𝗶𝗼𝗻)
- 𝗔𝗻 𝗲𝘅𝗽𝗲𝗿𝘁-𝗰𝘂𝗿𝗮𝘁𝗲𝗱 𝗿𝘂𝗯𝗿𝗶𝗰 𝗳𝗼𝗿 𝗲𝘃𝗲𝗿𝘆 𝘁𝗮𝘀𝗸, 𝘀𝗰𝗼𝗿𝗶𝗻𝗴 𝟲 𝗱𝗶𝗺𝗲𝗻𝘀𝗶𝗼𝗻𝘀 𝗼𝗳 𝗮𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝗮𝗹 𝗾𝘂𝗮𝗹𝗶𝘁𝘆
- 𝗣𝗿𝗼𝗰𝗲𝘀𝘀-𝗹𝗲𝘃𝗲𝗹 𝗲𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻 𝗼𝗳 𝟵 𝗳𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗟𝗟𝗠𝘀 (𝗚𝗣𝗧-𝟱.𝟱, 𝗖𝗹𝗮𝘂𝗱𝗲 𝗢𝗽𝘂𝘀 𝟰.𝟳, 𝗮𝗺𝗼𝗻𝗴 𝗼𝘁𝗵𝗲𝗿𝘀) 𝗮𝗰𝗿𝗼𝘀𝘀 𝟰 𝗮𝗴𝗲𝗻𝘁 𝗵𝗮𝗿𝗻𝗲𝘀𝘀𝗲𝘀 (𝗖𝗹𝗮𝘂𝗱𝗲 𝗖𝗼𝗱𝗲, 𝗖𝗼𝗱𝗲𝘅 𝗖𝗟𝗜, 𝗧𝗲𝗿𝗺𝗶𝗻𝘂𝘀-𝟮, 𝗚𝗲𝗺𝗶𝗻𝗶 𝗖𝗟𝗜)
Headline results:
- 𝗙𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗺𝗼𝗱𝗲𝗹𝘀 𝗹𝗲𝗮𝗱 𝗮𝘁 𝟳𝟯.𝟯/𝟭𝟬𝟬, 𝘄𝗶𝘁𝗵 𝘀𝘂𝗯𝘀𝘁𝗮𝗻𝘁𝗶𝗮𝗹 𝗵𝗲𝗮𝗱𝗿𝗼𝗼𝗺 𝘁𝗼 𝗶𝗺𝗽𝗿𝗼𝘃𝗲.
- 𝗧𝗵𝗲 𝗮𝗴𝗲𝗻𝘁 𝗵𝗮𝗿𝗻𝗲𝘀𝘀 𝗺𝗮𝘁𝘁𝗲𝗿𝘀 𝗮𝘀 𝗺𝘂𝗰𝗵 𝗮𝘀 𝘁𝗵𝗲 𝗯𝗮𝘀𝗲 𝗺𝗼𝗱𝗲𝗹.
- 𝗔𝗴𝗲𝗻𝘁𝘀 𝗳𝗮𝗹𝗹 𝘀𝗵𝗼𝗿𝘁 𝗼𝗻 𝗯𝗶𝗼𝗹𝗼𝗴𝗶𝗰𝗮𝗹 𝗶𝗻𝘁𝗲𝗿𝗽𝗿𝗲𝘁𝗮𝘁𝗶𝗼𝗻, 𝗺𝗲𝘁𝗵𝗼𝗱 𝘀𝗲𝗹𝗲𝗰𝘁𝗶𝗼𝗻, 𝗮𝗻𝗱 𝘀𝗰𝗶𝗲𝗻𝘁𝗶𝗳𝗶𝗰 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴.
We hope to make 𝗕𝗶𝗼𝗺𝗻𝗶𝗕𝗲𝗻𝗰𝗵 the most helpful benchmark for biologists to understand how AI agents handle real-world biomedical tasks: where they can be trusted, and where they fall short. We're actively expanding our evaluation effort, and would love to engage the broader scientific community on what comes next.
📄 https://t.co/U1rh2QP9Ht
🤗 https://t.co/513AX8AQtJ
Thanks to our amazing @phylo_bio team (Minta Lu, @TuXinming , @serena2z , @TianweiShe , @lecong , @jure , @KexinHuang5 ) and our collaborators at @LaudeInstitute , @Stanford , @Harvard , @PKU1898 , @virginia_tech , Humanlaya Data Lab, Xbench: @alexgshaw , JOU-HO SHIH, Bingqing Zhao, Minjie Shen, Haochen Yang, Jielin Yan, Rongchuan Zhang, Xinze Wu, Tingting Li, Xiaobo Hu, Yuan Jiang, Jiayun Dong, Tao Peng.
Until now, AI agent ran on one machine, and one workflow at a time. A memory-heavy step crashed six hours in, and the run started over.
Biomni agent now autonomously decides how many machines it needs, how much CPU and memory each task requires, spins them up, and distributes work across them.
It operates like a coordinated team working in parallel, rather than one researcher at a work station.
This is the foundation for agent-managed infrastructure.
The first ProgramBench task was just solved by GPT 5.5 high/xhigh. Interestingly, high/xhigh picked two different languages for the task (C vs Python). GPT 5.5 xhigh was significantly better than Opus 4.7 xhigh in all metrics. 🧵
We improve a 32-year lower bound in a challenging open problem, Ramsey numbers, through simply scaling autoresearch.
⭕ Proves R(3,17) >= 93. Previous 92 bound were obtained in 1994.
Google’s AlphaEvolve (2026) matched previous result but did not beat it.
All could be done with Claude Code / Codex + a CPU server.
Graphs and evolving history are available at https://t.co/2kCsk9Otur
[1/n]
@ChenhaoTan I ran openaireview locally and it caught some tiny but important mistakes in writing. So your actual user count is higher than the website traffic suggests!