Congrats to @sertealex for the first near-perfect transpiled submission to https://t.co/gB3O7BFauR, I can't think of a better trophy than the one he received!
https://t.co/dMxSQb9tix
One takeaway from ProgramBench is that some current LLMs tend to give up too early. I'm curious what happens if we prompt models to work until timeout, since long-running autonomous agent have interesting issues! See link https://t.co/A5jBueP8ef /cc @jyangballin@KLieret
ProgramBench is awesome! It shows there's a lot of room to improve LLMs and agents at autonomously implementing entire programs from scratch, and it's a great hill climb target https://t.co/g5nH24WwTK
Can one person really use agents to manage nearly half a million lines of JavaScript, and produce a maintainable codebase? One way to find out! https://t.co/6jVkW4kspZ
I'll be helping David Bau run a contest which will let its participants show us how far they can push agentic coding!
The task is "simple": port NetHack, over 440k lines of C and Lua, to JavaScript. Easy to verify, but still far from easy for agents.
https://t.co/Myd68sKnX1
Porting NetHack seems like a great challenge for agents. The translation can be verified using pre-recorded input-output behaviors. But the feedback for the agent is sparse, the debugging chains get long, and early architectural mistakes can look good for a long time.
The G in AGI stands for "general".
General intelligence does not mean that you have been specifically trained for a large range of tasks. It means you can approach any NEW task and figure it out, just like humans do.
If regular people can do it on their own (no guidance, no tools), why should AGI require special handholding and handcrafted instructions? If it's AGI, why would there still be a human in the loop, using their own human intelligence to guide the model on every new task?
Announcing ARC-AGI-3
The only unsaturated agentic intelligence benchmark in the world
Humans score 100%, AI <1%
This human-AI gap demonstrates we do not yet have AGI
Most benchmarks test what models already know, ARC-AGI-3 tests how they learn
I'm working on scaling Agnostics to larger problems. Esolangs are an exciting angle! I'd be glad to talk more, maybe at ICLR. Some people I know also may be interested.
See more about Agnostics here: https://t.co/zLYaRYfkWa
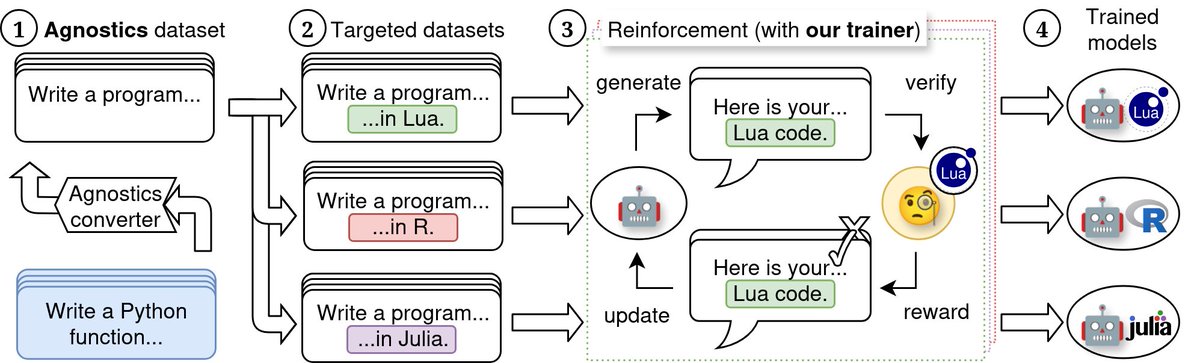
Great study! LLMs fail at rare programming languages in surprising ways. It'd be interesting to study these failure modes on larger examples. Our Agnostics may help: we show how to make problems which can be solved in any PL. Happy to chat more @lossfunk! https://t.co/VaelPySxCY
🚨 Shocking: Frontier LLMs score 85-95% on standard coding benchmarks. We gave them equivalent problems in languages they couldn't have memorized. They collapsed to 0-11%.
Presenting EsoLang-Bench.
Accepted to the Logical Reasoning and ICBINB workshops at ICLR 2026 🧵
@ShriramKMurthi In the end, a human needs to verify if the codebase satisfies some real-world requirements. It’s hard to see how to escape that in the foreseeable future.
@__protected@odersky Congratulations @odersky! Since the invitation to your lab I’ve been on a non-stop adventure of my life. Seeing your efforts was formative for me. As Jonathan said: well deserved!
The leaderboard also shows the results of training SmolLM3 using the Agnostics framework, it's a small (3B) but very capable model. The Lua variant shows the highest relative gains from all the Lua models we trained!
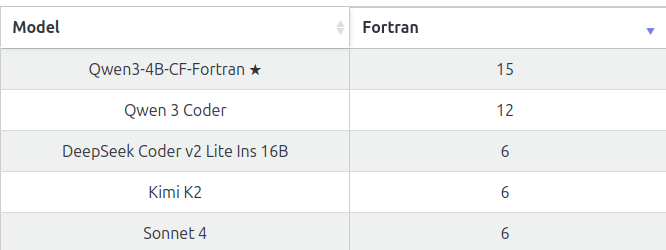
We're publishing the Ag-LiveCodeBench-X leaderboard! It shows the peformance of models on coding in low-resource programming languages, using a benchmark prepared during the Agnostics project. https://t.co/DIgChqKMQz
The leaderboard shows more results than what we included in the report. We can see that the models we trained rival Sonnet 4 on coding in R, and beat it and Qwen 3 Coder on Fortran!
@brendanh0gan Congrats on your impressive results! We published a similar report recently, although we focused on developing a universal pipeline which works on any programming language. I'm curious to see how we can learn from each other! https://t.co/EtxXybykkB
We show a way to reinforce an LLM’s ability to code in *any* programming language! We turn Qwen 3 4B and 8B into SOTA ≤16B models for low-resource programming languages, rivaling their 32B sibling.
Find out more about our Agnostics project at https://t.co/AFhqJyaelR , or here👇
We show a way to reinforce an LLM’s ability to code in *any* programming language! We turn Qwen 3 4B and 8B into SOTA ≤16B models for low-resource programming languages, rivaling their 32B sibling.
Find out more about our Agnostics project at https://t.co/AFhqJyaelR , or here👇