🎉 Oficialmente ya puedo presentar @eventos_wiki
La idea es crear, entre toda la comunidad, un único lugar con todos los eventos sobre tecnología.
¿Falta algún evento? Puedes solicitarlo con una issue en el repo de GitHub. ¡PRs son bienvenidas!
https://t.co/jUQOCY0qaF
Algo grande se está cocinando en #CommitConf. 🚀 Este año nos hemos propuesto romper moldes con un proyecto que cambiará la forma de vivir los eventos, ¡y no solo en el sector tecnológico! 💥La cuenta atrás ha comenzado.
Después de gastar billones de tokens, creo que ya puedo sacar una conclusión bastante clara:
La gente está optimizando el coste equivocado.
He probado decenas de modelos, editores y agentes:
Codex, Claude Code, Cursor, OpenCode, Codex Cloud, múltiples providers y configuraciones.
Llevo desde gpt-3.5 usando IA para programar.
Al principio como asistente y desde diciembre del año pasado, no escribo código manualmente: programo exclusivamente con IA.
Además lo he hecho en proyectos reales. En productos en producción con millones de usuarios, como Calisteniapp.
Me costó todo este tiempo darme cuenta de qué es lo realmente importante a la hora de elegir modelos y tools.
La mayoría mira únicamente el precio por millón de tokens, o el uso que tiene incluido en la suscripción de turno, y la calidad del resultado.
Tienden a usar el mejor modelo calidad/precio que se pueden permitir.
Pero esta métrica, aislada, no significa nada.
Porque el verdadero coste no son los tokens. Es el efecto compuesto:
- el número de iteraciones,
- el tiempo humano,
- la carga mental,
- la pérdida de flow,
- y el coste de revisar trabajo mediocre.
Con modelos baratos tipo Kimi K2.6, para una misma tarea, normalmente necesito 1 o 2 iteraciones más que con GPT-5.5 o modelos sota.
Sí, el modelo barato cuesta 2-3 veces menos por token.
Pero si necesito:
- más prompts,
- más revisiones,
- más contexto,
- más correcciones,
- y más tiempo pensando…
Entonces el modelo "barato" termina siendo más caro.
Porque no estás pagando solo tokens.
Estás pagando tiempo humano y carga cognitiva.
Y el tiempo humano de un programador senior no vale precisamente poco.
Tomemos un baseline conservador: 40 céntimos por minuto.
Si un modelo mediocre me hace perder 10 minutos extra revisando, iterando o corrigiendo, ya he gastado 4€ invisibles.
Ese es el coste oculto de usar modelos "calidad/precio".
Y esto se vuelve todavía más evidente usando modos xhigh o max. Mucha gente piensa: no compensa, consume demasiados tokens.
En mi experiencia, la mayoría de las veces ocurre exactamente lo contrario.
Los modos de razonamiento profundo suelen ser más baratos en coste total real porque:
- resuelven mejor,
- hacen menos errores,
- necesitan menos iteraciones,
- y llegan mucho más cerca del one-shot.
A veces gastas más tokens. Pero menos tiempo humano. Y eso es lo importante.
Pero hay otro factor más que la gente subestima y que casi nadie mide:
La velocidad de inferencia.
Hay tareas donde no necesitas el modelo más inteligente del planeta.
Por ejemplo:
- commits,
- pushes,
- tareas mecánicas,
- scripting simple,
- operaciones repetitivas.
Pero ahí tampoco compensa necesariamente usar modelos lentos y baratos.
Compensa usar modelos suficientemente inteligentes… pero absurdamente rápidos.
Modelos como GLM 4.7 o GPT OSS 120B en providers optimizados pueden trabajar a cientos o incluso miles de tokens por segundo.
¿Resultado?
Tareas que antes tardaban 2 minutos pasan a tardar 10 segundos.
Y otra vez: el ahorro no está en tokens. Está en no romper el flow.
Dos minutos esperando un commit automático son dos minutos donde tu cerebro sale del contexto.
Son dos minutos de tu tiempo que cuestan mucho más que esos tokens.
Te sugiero cambiar el chip:
- No optimizar €/millón de tokens.
- Sino optimizar coste total cognitivo y operativo.
Si te interesa saber qué modelos y configuraciones uso, en mi perfil tienes un repo abierto con todo.
Si piensas diferente, me gustaría conocer tu opinión.
- planeas con gpt-5.5 xhigh
- /implement usa glm-4.7 para lanzar un worktree para cada tarea
no te casas con nadie, pagas por lo que usas.
amo @opencode
He publicado el repo con las personalizaciones de @opencode que más han cambiado mi flujo de trabajo diario.
https://t.co/YawddUsiJI
Básicamente incluye 2 plugins, 5 comandos y mi setup local con OpenCode + Worktrunk + Ghostty.
Plugins
1. Un plugin TUI que cambia el título de cada pestaña/ventana según el estado de OpenCode:
🟡 trabajando
🟢 idle / terminado
🔴 requiere atención / error
2. Un plugin server que manda notificaciones locales en macOS cuando una sesión termina o necesita intervención.
Comandos
Los comandos no tienen demasiada magia. Son atajos para no escribir siempre el mismo prompt/flujo:
/clean-code
Auditoría read-only de arquitectura, mantenibilidad, SRP, SOLID y code smells.
/audit
Auditoría de seguridad read-only sobre la PR actual o el repo completo.
/branch
Cuando ya tengo un plan claro, crea un worktree aislado con Worktrunk y abre una sesión limpia de OpenCode allí con el plan como prompt inicial.
/push
Revisa el diff, ejecuta checks/tests relevantes, crea un commit convencional y hace push.
/ship
Prepara una rama para review: checks, commit si hace falta, push, PR en GitHub y revisión del estado de CI.
La idea no es automatizarlo todo de forma mágica, sino quitar fricción a las acciones que repito muchas veces al día.
Mi stack ahora mismo:
- OpenCode como cockpit de agentes, comandos y plugins.
- Worktrunk para ramas/worktrees aislados.
- Ghostty como terminal principal.
Es pequeño, local y bastante opinado, pero me está ahorrando muchísimo cambio de contexto.
Espero que te sirva.
En la última semana Codex ha pasado de tener 5 millones de instalaciones semanales a más de 85.
Esto ha sido porque mucha gente ha migrado de Claude Code allí por tener los límites más altos.
Seguramente este sea uno de los motivos por los cuáles Anthropic acaba de hacer un acuerdo con SpaceX para poder usas sus servidores.
Gracias a este acuerdo:
- Doblan el uso en la ventana de tiempo de 5h.
- Quitan el límite de horas punta.
- Aumentan los rate limits para los modelos Opus.
Que haya esta competencia nos beneficia a los usuarios.
Llevo meses apostando contra la mayoría.
Parece que empiezo a no estar tan loco.
La idea central es simple, pero incómoda:
Nadie quiere usar tu app.
Ni tu SaaS.
Ni tu herramienta.
La gente solo quiere resolver su problema y seguir con su vida.
Pero seguimos construyendo software como si el objetivo fuera que lo usen.
La semana pasada di una charla a 150 personas sobre esto.
La mayoría está pensando el futuro del software completamente mal.
El discurso dominante es:
habrá más software.
Más apps. Más herramientas. Más sistemas personalizados.
Cada persona con su propio CRM, su propio stack, su propio “todo”.
La misma cajita de siempre, pero multiplicada por mil.
Eso no es el futuro.
Eso es pensar en velas más grandes cuando lo que viene es la bombilla.
Porque nadie quiere apps.
Nadie se levanta pensando:
“ojalá hoy pueda usar 5 herramientas nuevas”
La gente quiere:
- entrenar sin complicarse
- llevar su negocio sin fricción
- resolver cosas rápido y ya
El software es solo el medio. Nunca fue el fin.
Y aquí está el cambio de verdad:
No es que vaya a haber más software.
Es que el software como producto deja de tener sentido.
Hasta ahora:
Abres una app → navegas → te adaptas → ejecutas
Te adaptas tú a la herramienta.
Pero lo que viene es lo contrario:
Dices lo que quieres → obtienes lo que necesitas
Un diseño emergente: sin menús, sin flujos, sin cajitas predefinidas.
“Quiero empezar calistenia”
→ plan generado
→ explicación
→ seguimiento
→ adaptación
El software ya no se usa.
El software responde.
No existe antes de que lo necesites.
Aparece en el momento.
Pensar que esto acaba en “más apps” es caer en tres sesgos:
- Cierre funcional: imaginamos el futuro como una versión mejorada de lo actual
- Continuidad: creemos que el cambio será gradual
- Extrapolación lineal: proyectamos el presente en vez de cambiar el modelo
(velas más grandes, caballos más rápidos…)
Pero el cambio no es evolutivo. Es de paradigma.
lo relevante?
Si el software se genera…
el software deja de ser la ventaja.
Quedan tres capas:
- Infraestructura (alguien tiene que hacer que todo funcione)
- Datos (que nutran los llms)
- Interfaz (sensorial y generativa)
Y fuera de eso, lo único defensible es:
- entender problemas
- tener distribución
- generar confianza
Porque al final: nadie quiere tu app, quiere el resultado.
Y eso no cambia.
Lo que sí cambia es dónde está el valor.
Mientras el software se comoditiza,
la diferenciación se mueve a:
- marca
- comunidad
- autoridad
La gente no quiere “una solución”.
Quiere TU solución.
Y aquí viene la pregunta incómoda que dejé en la charla:
Si mañana tu app desaparece... ¿qué queda?
Si la respuesta es “nada”,
no tienes producto.
Tienes una cajita, un envoltorio. Te has quedado con el medio en lugar de con el fin.
Tenemos web 🌐
https://t.co/mcFTTsZBHD
Ahí está todo documentado públicamente: el perfil molecular, la ciencia detrás del caso, el equipo de cuatro países, la cronología semana a semana.
Para quien se acaba de unir: tengo cáncer de mama metastásico con una biología tan rara que las guías clínicas no tienen respuesta para él.
Hace unas semanas decidí investigar mi propio caso con IA. Un hilo. Un equipo espontáneo. Y ahora esto.
No sé lo que viene. Pero voy con más información que nunca y con el mejor equipo posible.
Si eres oncólogo/a, investigador/a o simplemente quieres entender qué está pasando está todo ahí 👇
🙌 ¡Se abre el Call for Volunteers de #CommitConf 2026! Buscamos personas que quieran vivir el evento desde dentro, conocer a la comunidad tech y formar parte del equipo durante esta nueva edición.⏳ Inscripciones abiertas hasta el 30 de abril.
@inakitajes@opencode Yo llevo un par de días probando Opus 4.7 para SDD en la fase de exploración y definición. Creo que tiene mejor entendimiento a nivel de código. Lo peor es el coste, la implementación me la llevo a GPT-5.4
Necesito una biopsia molecular avanzada para saber qué tratamiento aún puede funcionar. He creado un crowdfunding para poder hacerla. Cualquier ayuda (donar o compartir) suma 💙
Maxima transparencia👇
https://t.co/pAiXLl36Lc
La mayoría de empresas NO necesitan otro chatbot.
Necesitan un entorno:
- abierto,
- multi-modelo,
- multi-agente,
- conectado a sus herramientas,
- y construido sobre su propio conocimiento.
Eso es Arche. Open source. Gratis.
Te cuento por qué importa:
(1/6)
Sorteamos 1 entrada gratis a la #JSConfES 🎉
Ya están las entradas agotadas, así que es tu última oportunidad para conseguir asistir 😊
Cómo participar:
1️⃣ RT de este post
2️⃣ Follow a @CodelyTV
3️⃣ Follow a @midudev (organizador)
4️⃣ Estar en el directo del Café con Codely de este viernes 6 de marzo (empieza a las 9h CET)
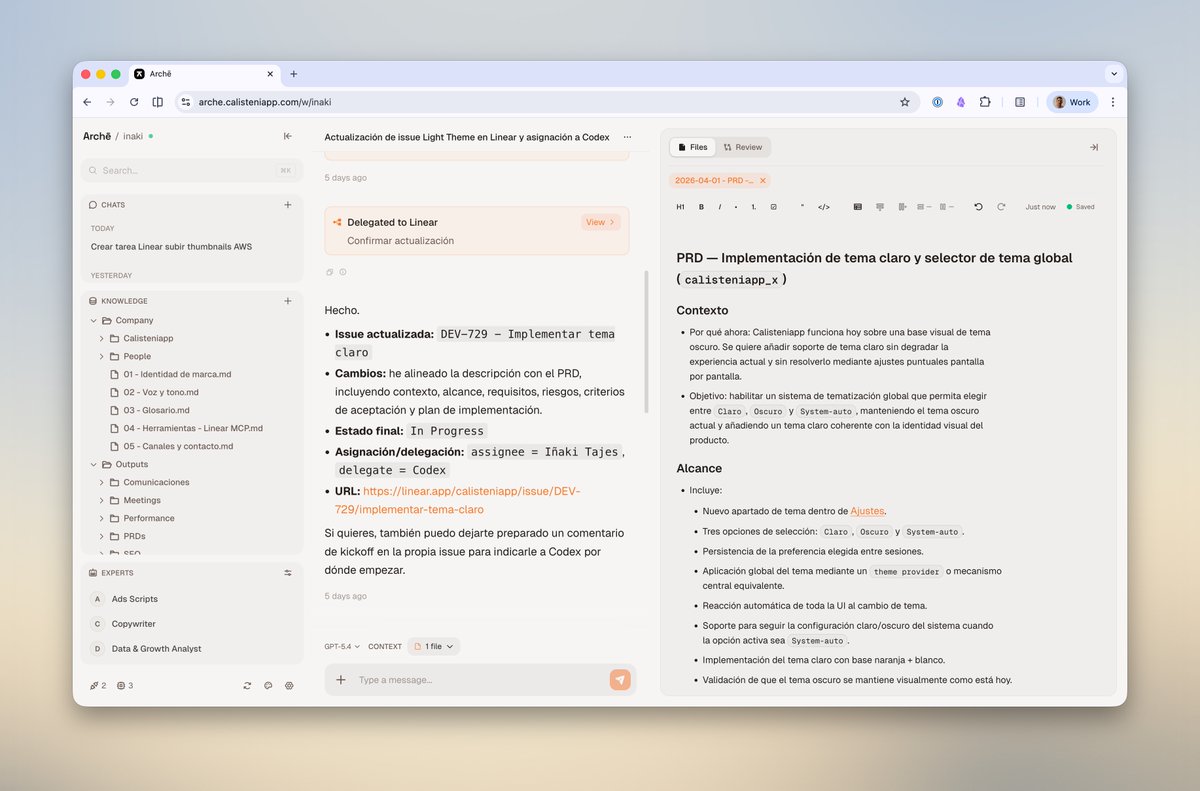
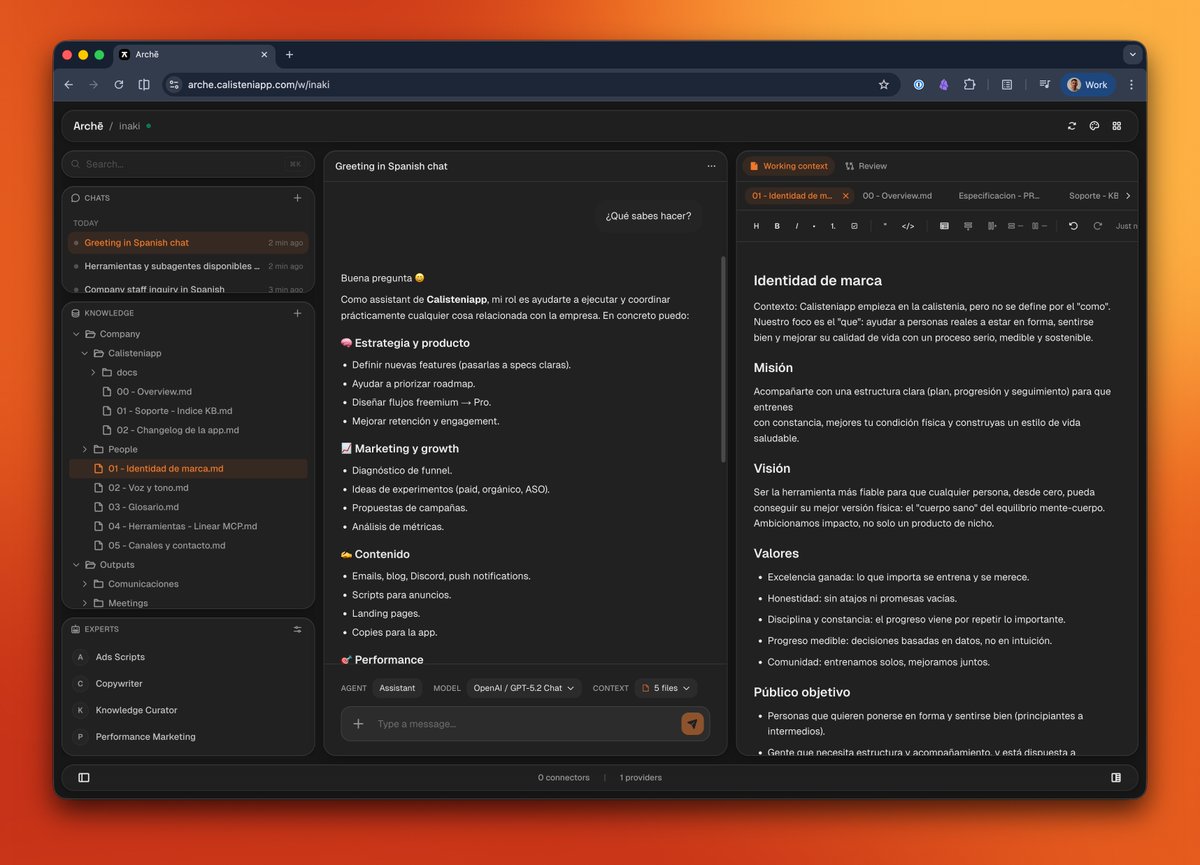
Archē is live! An open-source, AI native operating system for your company.
One goal: Bring the best tools together and create shared context for more efficient day to day operations.
It is built around @opencode and adds a layer of sugar. Custom tools, a shared versioned knowledge base, multi user remote workspace, and centralized configuration.
Best part. One click deploy on a cheap VPS. Up and running in minutes with its templating engine.
If you like it, try it and share. Still early stage. PRs welcome.
Cc: @p3rd0mo@ixJosemi
Arche está casi listooo!
No inventamos nada nuevo, solo unimos las mejores herramientas en un solo pack abierto, interoperable y sencillo de poner a funcionar.
Les dejo algunas novedades aprovechando un loom que le envié a un amigo :)
La revolución de la IA nos da un x10 en productividad.
Pero no sale gratis.
Quizás lo más duro de la transformación que estamos viviendo en el trabajo es que no todo el mundo está preparado física y anímicamente.
Una de las cosas que más drena de energía a un founder/c-level es la toma constante de decisiones y el context switching.
Estar a mil cosas en paralelo.
No parar de decidir.
Decisiones determinantes, todo el rato.
El ser humano no es multitarea.
Lo que hacemos es multiplexar tiempo: unos minutos para esto, otros para lo otro. Intercalamos tareas.
Y eso tiene un coste enorme: esfuerzo cognitivo, fatiga de decisión, burnout mental.
No todo el mundo puede (ni quiere) ocupar estos roles.
Empieza a ser evidente que, cuanto más rápida es la IA, más claro queda que el cuello de botella
seremos nosotros.
No podemos cambiar de contexto tantas veces y seguir tomando buenas decisiones al mismo tiempo.
Lo comenté en la última reunión trimestral con el equipo: el verdadero objetivo de este x10 en productividad debería ser darnos más espacio para pensar mejor.
No ir como caballos desbocados haciendo más, pero peor. Ni sacrificar salud por velocidad.
Productividad no es hacer más.
Es decidir mejor.