On-Policy Distillation is the most active new research direction being explored in RL for LLMs. Had the chance to discuss how it works with Dwarkesh and why it fits so nicely into large-scale pipelines.
wow this @reve 2.0 launch copy is supurb.
"it is now clear that the key to both controllable image generation and editing is not denser prompts, but a highly detailed, highly manipulatable, intermediate representation expressed as code."
"Creativity is not, and will never be, a one-shot workflow. But modern image generation models punish iteration through progressive degradation."
"Alan Kay famously said that people who are serious about software should make their own hardware. At Reve, we believe the same principle applies to creativity: companies that are truly serious about creative tooling should train their own models."
and dang look at these:
I promise this will be the best 20 min you spend today! Robotics: Endgame, the sequel to my last year's Sequoia AI Ascent talk, "Physical Turing Test". I laid out the roadmap for solving Physical AGI as a simple parallel to the LLM success story. Be a good scientist, copy homework ;)
And stay till the end, more easter eggs and predictions for your polymarket!
00:30 DGX-1 origin story at OpenAI, I was there in 2016 signing with Jensen and Elon. Heading to the Computer History Museum!
01:42 The Great Parallel
03:31 Robotics, the Endgame
03:39 Why VLAs fall short
04:32 Video world models as the 2nd pretraining paradigm
06:09 World Action Models (WAM)
07:46 Strategies for robot data collection and the FSD equivalent to physical data flywheel for robot manipulation
11:06 EgoScale and the Dexterity Scaling Law we discovered recently
14:00 Physical RL: bridging the last mile
15:39 DreamDojo: an end-to-end neural physics engine for scaling RL in silico
17:00 Civilizational Technology Tree and my predictions for the near future. Spoiler: it's closer than you think.
Thanks to my friends at Sequoia for inviting me back to AI Ascent this year! I had a blast! Last year's talk is attached in the thread if you missed it.
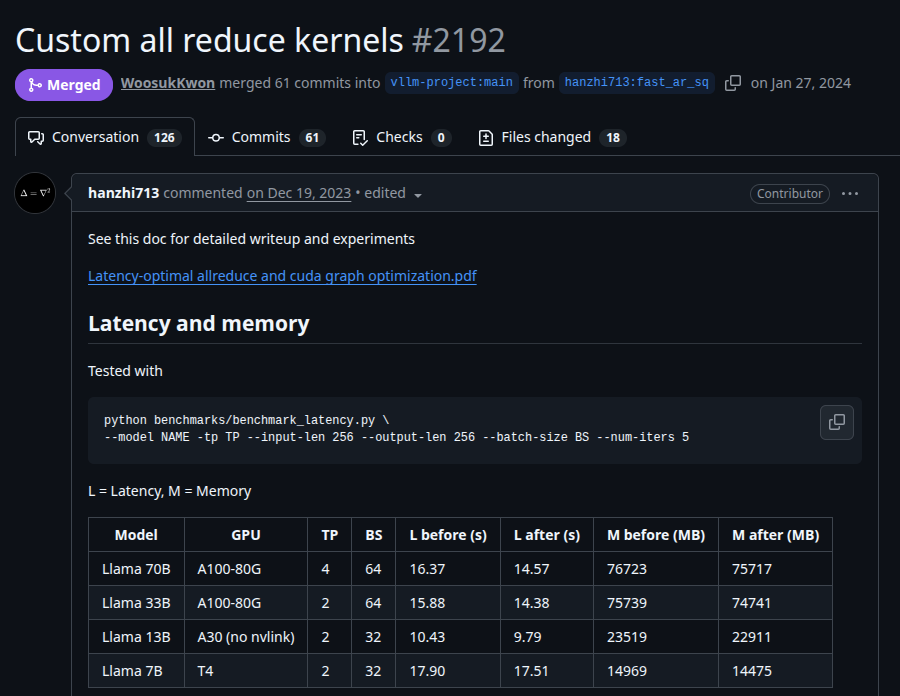
Not many know but the GOAT that created the custom allreduce kernel that runs everyone's decode since 3 years wrote a doc explaining the background and algorithims behind it. Give it a read
Inference got a hundred times cheaper this year. The compute bill went up anyway.
If you understand why those two sentences are both true at the same time, you understand the most important thing happening in AI right now.
I work on inference for a living, at @nebiustf, where we run open-source managed inference at scale. Most of what follows is what I'm seeing from inside the bill.
12 months ago, the cost of 1M tokens of frontier-class reasoning was somewhere on the order of $60.
Today, an equivalent quality of output costs roughly $0.50.
Price /token of o1-level intelligence has dropped about a 128x in a year.
Price of GPT-4-level output has dropped roughly 100x since the original GPT-4 shipped.
By any normal reading of a technology cost curve, this should be deflationary. It should be saving customers money.
The opposite has happened. The total compute bill at every hyperscaler is going up, not down. Anthropic just signed multi-year capacity deals with both XAI and Amazon. Microsoft's Azure capex guide for 2026 starts with an eight. OpenAI is reportedly spending more on compute every quarter than it did in all of 2023. Nvidia paid roughly twenty billion dollars to acquire Groq, an inference-specialist company that did not exist as a serious commercial entity three years ago.
The cost curve and the demand curve crossed, and then the demand curve lapped the cost curve.
Here is what happened underneath.
A reasoning model burns roughly 10x the output tokens of a non-reasoning model on the same task, because it spends most of its tokens thinking out loud before answering. An agentic workflow chains roughly twenty times the requests of a single-shot completion, because it loops, calls tools, plans, retries, and synthesizes. A modern deep-research query (the kind a research analyst can fire off in fifteen seconds and then walk away from for ten minutes) costs more compute than 10 original GPT-4 queries combined. We made every individual token a hundred times cheaper, and then we built a generation of products that consume ten thousand times more tokens.
This is the Jevons paradox playing out at trillion-dollar scale, in compressed time, in front of everyone. Jevons noticed in 1865 that making coal-burning more efficient did not reduce coal consumption. It increased it, because efficiency unlocked uses that were previously uneconomic. Steam engines became more practical at smaller scales. Whole industries that could not afford coal at the old price suddenly could. Britain's coal consumption rose sharply, not despite the efficiency gains, but because of them.
The same thing is happening to AI compute right now and it is happening faster than any analogous historical cycle. Falling token prices did not contract demand. They unlocked agents, deep research, code-writing systems, multi-step reasoning, persistent memory, the entire next layer of AI products. Every product in that next layer consumes orders of magnitude more compute than the chat interfaces it is replacing.
The math at the aggregate level is brutal: 100x cheaper tokens times 10 000 more tokens equals a 100x larger total bill.
The implications stack quickly.
If you are running a hyperscaler, your 2026 capex guide is not a peak. It is a step on a curve. Inference is structurally always-on, twenty-four hours a day, in a way that training never was. Training is bursty. You spin up a cluster, run for weeks or months, and stop. Inference runs continuously, scales with usage, and the usage curve is exponential. Your power bill, your cooling bill, your transceiver count, your storage footprint, all of these were sized for a workload mix that no longer exists.
If you are running an AI software company built on top of someone else's closed API, you have a problem that did not exist a year ago. Your gross margins get worse as your customers get more value out of your product, because the more they use it, the more compute you pay for. The companies that win this are the ones that figured out vertical integration before the math caught them.
If you are watching this from a distance and trying to understand where the next bottlenecks form, the answer is everywhere downstream of "more inference compute, always-on, with massive memory state per session." The KV cache, the running memory state of a long conversation or an agent loop, is the silent monster of the inference era. It does not scale linearly with parameters. It scales linearly with context length and number of agent steps. A long agent session can hold tens of gigabytes of state per user, per session.
Multiply that by every concurrent user of every product, and you understand why $MU, $SNDK, $TOWCF, and the entire memory and packaging layer have re-rated the way they have.
The CPU-to-GPU ratio is evolving. Training is 1:8. Basic chat inference is 1:4. Agentic inference is 1:1, sometimes CPU-heavy. Google has split its TPU line in two, with a dedicated inference chip carrying tripled SRAM for KV cache. $INTC and $AMD just spent two earnings calls explaining that this shift is structural, not cyclical. The hardware map is redrawing in real time and the financial press is mostly still writing about training clusters.
The right framing of where we are right now is not that AI is hitting a wall. The framing a year ago that scaling was hitting a wall was the most expensive bad take of the cycle. The right framing is that AI got dramatically cheaper, dramatically more capable, and dramatically more useful, and the cost of running it at the new equilibrium of demand is much higher than the cost at the old equilibrium of demand, because the new equilibrium is enormous.
A meaningful share of what we actually do at Token Factory, day to day, is help customers stop their bills from running away from them. KV-cache management. Speculative decoding. Quantization. Routing. The kind of vertical integration that, eighteen months ago, every product team was happy to leave abstracted away behind a closed API. The reason this stack matters now is the same reason this whole essay matters: at the new equilibrium of inference demand, the cost of treating compute as a commodity is no longer survivable. The companies that figure out the layer beneath the API are the ones who keep their margins.
Cheaper tokens. More tokens.
Same coal as 1865.
For the past few years, humans have been doing “prompt engineering” to coax the best performance out of different LLMs. In this work, we explored what happens if we train an AI to do that job instead.
By training a Conductor model with RL, we found that it naturally learns to write highly effective, custom instructions for a whole pool of other models. It essentially learns to ‘manage’ them in natural language.
What surprised me most was how it dynamically adapts. For simple factual questions, it just queries one model. But for hard coding problems, it autonomously spins up a whole pipeline of planners, coders, and verifiers.
Really excited to see where this paradigm of “AI managing AI” goes next, especially as we start moving from single-agent chain-of-thought to multi-agent “chain-of-command”.
Link to our #ICLR2026 paper: https://t.co/EwbjjRPLUb
Along with our TRINITY paper which we announced earlier, this work also powers our new multi-agent system: Sakana Fugu (https://t.co/2m8VRdOYqG) 🐡
love this replay buffer paper from Meta:
https://t.co/JysdD9gLIn
"methods like PPO or GRPO typically operate as on-policy as possible, meaning rollouts are generated, used for a single gradient update, and immediately discarded."
this is crazy and we shouldn't do this!
I wrote about the GIL, a source of perennial confusion in high-performance Python, as I found myself confused by how, exactly, it works.
https://t.co/olRIwtjFvZ
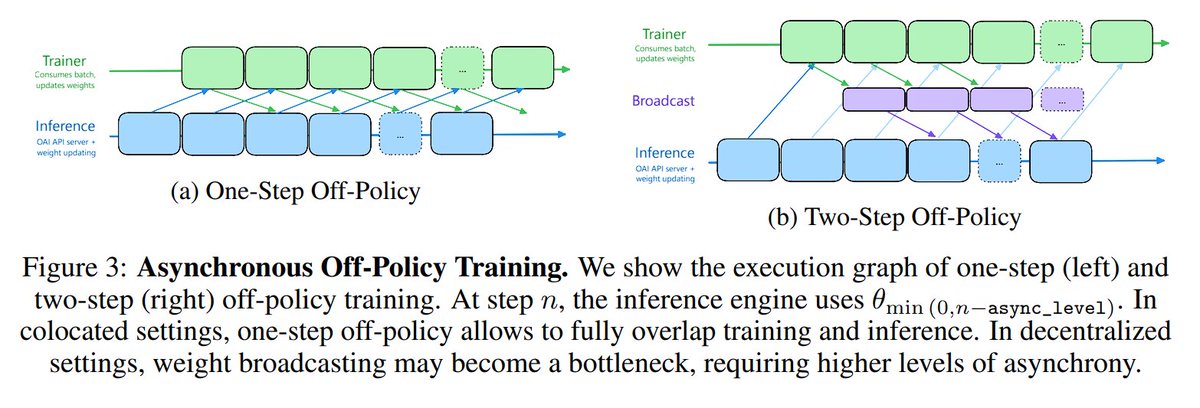
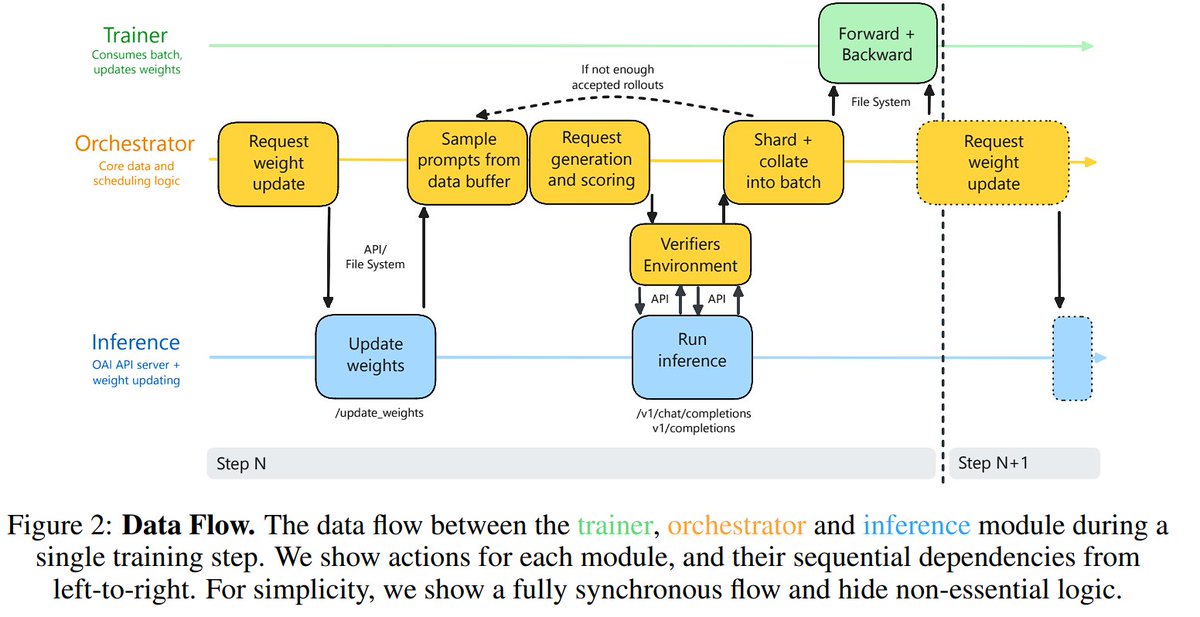
For Olmo 3, we moved from a synchronous RL setup to an asynchronous one. This made our code 4x faster in terms of throughput (tokens/second).
I wrote about the changes in the paper, but I finally found the time to go deeper on what was involved:
https://t.co/7aky9ouxYU
repo link:
→ https://t.co/RuKiOxUiX2
Shoutout to @addyosmani for building this and making it open-source for the community! 🤗
Don't forget to drop a ⭐️ on to help boost visibility!
sharing my first open source project
a CLI for downloading and syncing your X bookmarks locally so your agent can access them. it's free
› npm install -g fieldtheory
› login to your X account in a chrome tab
› ft sync (done!)
bonus:
› ft viz
› ft classify
I second the suggestion to learn about async RL by using prime-RL, their code is very clear and hackable.
But if you prefer to learn about async RL for LLMs via papers, I recommend these early ones:
- https://t.co/7lx15EIDar
- https://t.co/JTVTWuU2P5
https://t.co/7A7arVaxHR
a lot of folks have been DM’ing me about how to dive into async RL. i’d recommend not jumping straight into papers (they can be pretty overwhelming at first). imo the best place to start is Prime-RL. the codebase is clean, modular and easy to follow. work through it to understand the core components and implementation details then dig into the design choices and why they were made. after that there’s a deep rabbit hole to explore on your own (like the async RL nuances in kimi, GLM, composer, etc).
Let's say we wanted to rewrite PyTorch from scratch, because such a thing is topic du jour in the age of LLMs. What would the goals of such a rewrite be? What problems could a rewrite solve that incremental evolution from where the code is today not? 🧵
The AI Scientist: Towards Fully Automated AI Research, Now Published in Nature
Nature: https://t.co/nNfpSV5e5I
Blog: https://t.co/i6h8LVQOdl
When we first introduced The AI Scientist, we shared an ambitious vision of an agent powered by foundation models capable of executing the entire machine learning research lifecycle.
From inventing ideas and writing code to executing experiments and drafting the manuscript, the system demonstrated that end-to-end automation of the scientific process is possible.
Soon after, we shared a historic update: the improved AI Scientist-v2 produced the first fully AI-generated paper to pass a rigorous human peer-review process.
Today, we are happy to announce that “The AI Scientist: Towards Fully Automated AI Research,” our paper describing all of this work, along with fresh new insights, has been published in @Nature!
This Nature publication consolidates these milestones and details the underlying foundation model orchestration. It also introduces our Automated Reviewer, which matches human review judgments and actually exceeds standard inter-human agreement.
Crucially, by using this reviewer to grade papers generated by different foundation models, we discovered a clear scaling law of science. As the underlying foundation models improve, the quality of the generated scientific papers increases correspondingly. This implies that as compute costs decrease and model capabilities continue to exponentially increase, future versions of The AI Scientist will be substantially more capable.
Building upon our previous open-source releases (https://t.co/H1tBT14Yx8), this open-access Nature publication comprehensively details our system's architecture, outlines several new scaling results, and discusses the promise and challenges of AI-generated science.
This substantial milestone is the result of a close and fruitful collaboration between researchers at Sakana AI, the University of British Columbia (UBC) and the Vector Institute, and the University of Oxford. Congrats to the team!
@_chris_lu_@cong_ml@RobertTLange@_yutaroyamada@shengranhu@j_foerst@hardmaru@jeffclune
I discuss some more details in the blogpost (https://t.co/HR5vMgUQFD). I'm very excited to see what comes out of this, and related work in the residency, like @BillyHoy1_'s stuff - hopefully it will spark more work on open multi-agent RL!
C++: Memory Layout and Compiler Directives
https://t.co/yv92dZT4NS
Same struct. Three layouts. Wildly different sizes.
default → 8 bytes. packed → 5. alignas(16) → 16.
Where it matters:
- Network Protocols: Use packed structs for a minimal "wire format" to avoid sending wasted padding bytes.
- Hardware Interfaces: Use specific alignments for memory-mapped I/O where hardware expects data at particular boundaries.
- Performance Optimization: Use aligned access for vectorization (SIMD) to enable faster data processing.
- Cross-Platform Compatibility: Ensure a consistent memory layout when compiling code across different architectures.