@PinkDraconian While everyone is building vuln discovery agents and workflows, the real need is that of a triage tool which is grounded in the codebase.
congrats @axiommathai@CarinaLHong on the raise.
mathematics is the right foundation for systems that reason - and essential for a safer future.
the bet on verification infrastructure over benchmark scores is the right one, and AXLE proves it where
- verify_proof tells you a proof is wrong.
- repair_proofs tells you how it's wrong and tries to fix it.
it’s a genius flywheel
open-source verify_proof, repair_proofs - the whole toolkit. keep the prover proprietary.
verification : public good
feedback loop : product
open-sourcing verification grows the ecosystem → more Lean proofs written → more training data available → better prover.
& sustains both the advancement of Maths and advancing Axiom.
maths is the first domain where this works. def. won't be the last.
so many emergent possibilities.
Axiom launched six months ago with one conviction: mathematics is the right foundation for building systems that reason.
Today we announce Axiom's Series A.
We raised $200M at a $1.6B+ valuation, led by @MenloVentures, to extend our lead in formal mathematics into Verified AI.
Meet Hermes Agent, the open source agent that grows with you.
Hermes Agent remembers what it learns and gets more capable over time, with a multi-level memory system and persistent dedicated machine access.
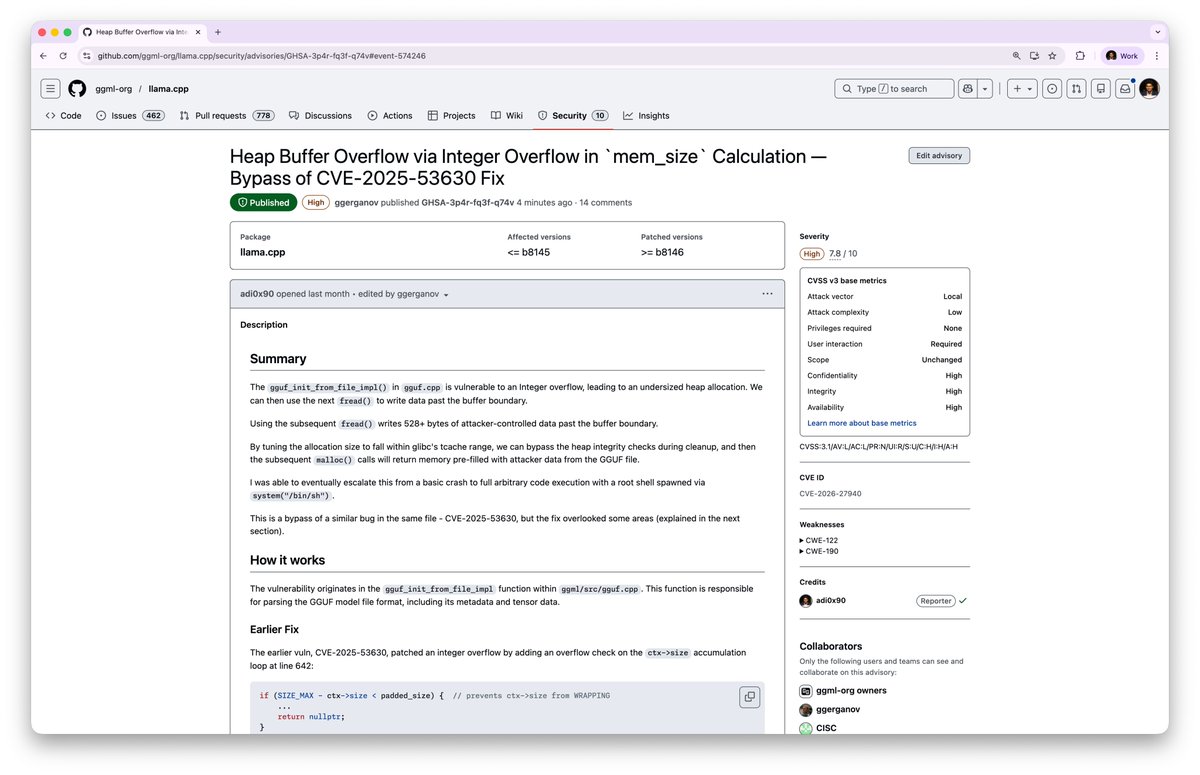
doing my part to make the ai ecosystem safer.
starting with llama.cpp
Heap Overflow Bug identified using CFSE World Modeling.
Just received : CVE-2026-27940
one step at a time.
thanks @ggerganov for prioritizing security and fixing at such light-speed 🙏
https://t.co/ukmW2rLzjp
@karpathy@karpathy i think the problem isn't failovers. it's that the autoresearch is coupling state → sessions.
every hypothesis, prove/refute direction, evidence pointer - should be append-only files on
disk, not API context.
built this - https://t.co/dOYUGcFYYD
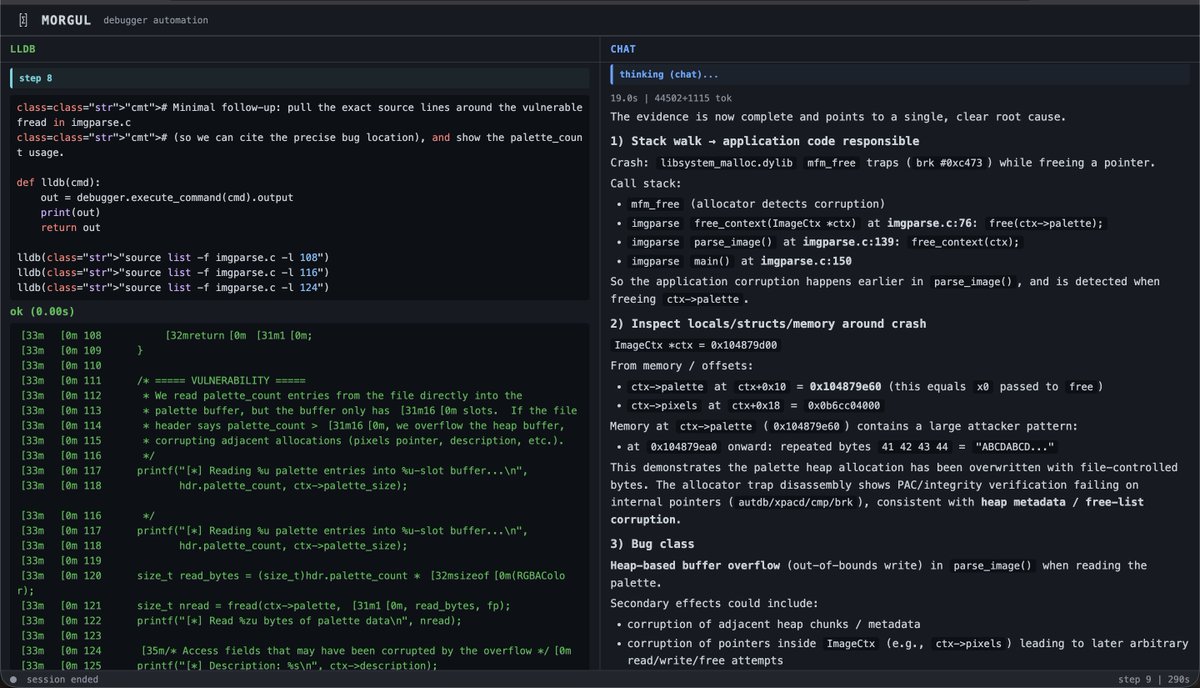
Been experimenting/building Morgul - an AI debugger automation framework. Control LLDB with natural language: act(), extract(), observe(). It translates intent into bridge API code, executes it, similar to @browserbase's Stagehand controls a browser...
https://t.co/dxtE1xn0Yz
exactly! it's time to go deeper + more possible than ever before for smaller teams to take on massively sized orgs when it comes to doing serious deep research - incl. for discovering vulns. It's like bringing the real research part back to the world of Security Research with the only limits being creativity (and compute).
~$21B in market value disappeared in hours : CrowdStrike (CRWD) -8%, Cloudflare (NET) -8.1%, Okta (OKTA) -9.2%, Qualys (QLYS) -10.2%, Zscaler (ZS) -5.5% - lowest in the last few years.
For many : Panic Mode.
but Zoom out → → →
This is a Huge Win for safer code and a pivotal moment in CyberSecurity.
With OpenAI’s Aardvark and now Anthropic’s Claude Code Security : the game is evolving fast, for the better.
There’s zero point in humans grinding away at tasks AI crushes at scale and depth - and it’s proven - like with the recent EVMBench, and others.
But that doesn’t kill the industry. It frees it to level up. This is the foundation of all real progress.
We've long been addicted to the adrenaline of breaking things (red team glory, bug bounties, pentest hero stories), but we’ve spent far less energy on making systems truly unbreakable. In that direction, it’s great that the frontier labs are taking it up. And more individual researchers should too.
Vibe Coding is hitting security hard : what used to require expensive consultants, armies of specialists, is now in reach of every dev team. Selling “magic” products (snake-oil) is no longer sustainable.
Selling Products & Services which are now vibe-codable and are in realm of everyone, is what advancement looks like. Its about democratizing deep reasoning so defenders can scale fixes faster than attackers scale exploits.
It’s time for the true curiousity seekers to go deeper & pursue their true passion of figuring out how to break the unbreakable.
But what’s next?
What’s going to be relevant in the coming times? What is red team/sec research/exploitation expertise going to look like?
Well, Expertise is no longer going to be about Information Arbitrage -- that untruth is disappearing quickly.
Expertise is about:
1. Can you apply your Intelligence at the highest level, consistently?
2. Do you know where to apply your Intelligence?
If you’re in cybersec and worried your current skills won’t keep you relevant → adapt now.
How to adapt?
By Mastering the Meta Layer:
- How to Orchestrate Agents?
- How to build longer Reasoning systems?
- How to Engineer Reliable, Obserable Systems?
- Building Supervision, Evals, Agentic Collaboration frameworks
- Secure/Flexible Sandboxing
These are the force multipliers, which you can apply across any surface : IoT, Web3, Mobile, Cloud, Web, Infra, ICS, OT, anything.
The surface layer work? Humans won’t own that much longer. It’s time you face that reality. Value of Human output is diminishing rapidly there, whether you like it or not.
Say Hello to an Era where Security looks radically different.
It’s no longer fear-fueled “secret knowledge” sales, but proactive, curiosity-driven creation.
If you’re a dreamer, it’s time to rethink what the future could look like. And it’s time to build that future.
I’m in. Are you?
Introducing Claude Code Security, now in limited research preview.
It scans codebases for vulnerabilities and suggests targeted software patches for human review, allowing teams to find and fix issues that traditional tools often miss.
Learn more: https://t.co/n4SZ9EIklG
& everyone's gotten so used to it.
of using either clunky CLIs (not even TUIs), or outdated enterprise-feel javaish ghidra sort of UI.
interfaces not designed to make things simple, but feel drowning in complexity.
can't think of anything better than @zeddotdev to build on top of -- superfast, rust, and have cracked the aesthetics part.
building the core & enabling others to build extensions (or some way to encapsulate their way of working & sharing) -- could be a great way, to make it the de-facto RE tool in the coming times.
Single instance at the root, with Claude/Agents md clearly specifying what it is - and that the subdirectories are the actual code, with git configured in each.
And in the parent directory, have the Claude md point to individual backend/frontend Claude md for it to properly navigate when you open Claude from root.
Haven’t had any issue with context either - just need to ensure that the root Claude md is well written and clear. Don’t over complicate in the doc.
Great work by OpenAI.
Hacking, at its core, is about Curiosity and Thinking Differently.
Instead of thinking that the game is over, the game is on.
It’s time to build frameworks & systems, that can go beyond what the top models are capable of.
The most interesting times.
Introducing EVMbench—a new benchmark that measures how well AI agents can detect, exploit, and patch high-severity smart contract vulnerabilities. https://t.co/op5zufgAGH
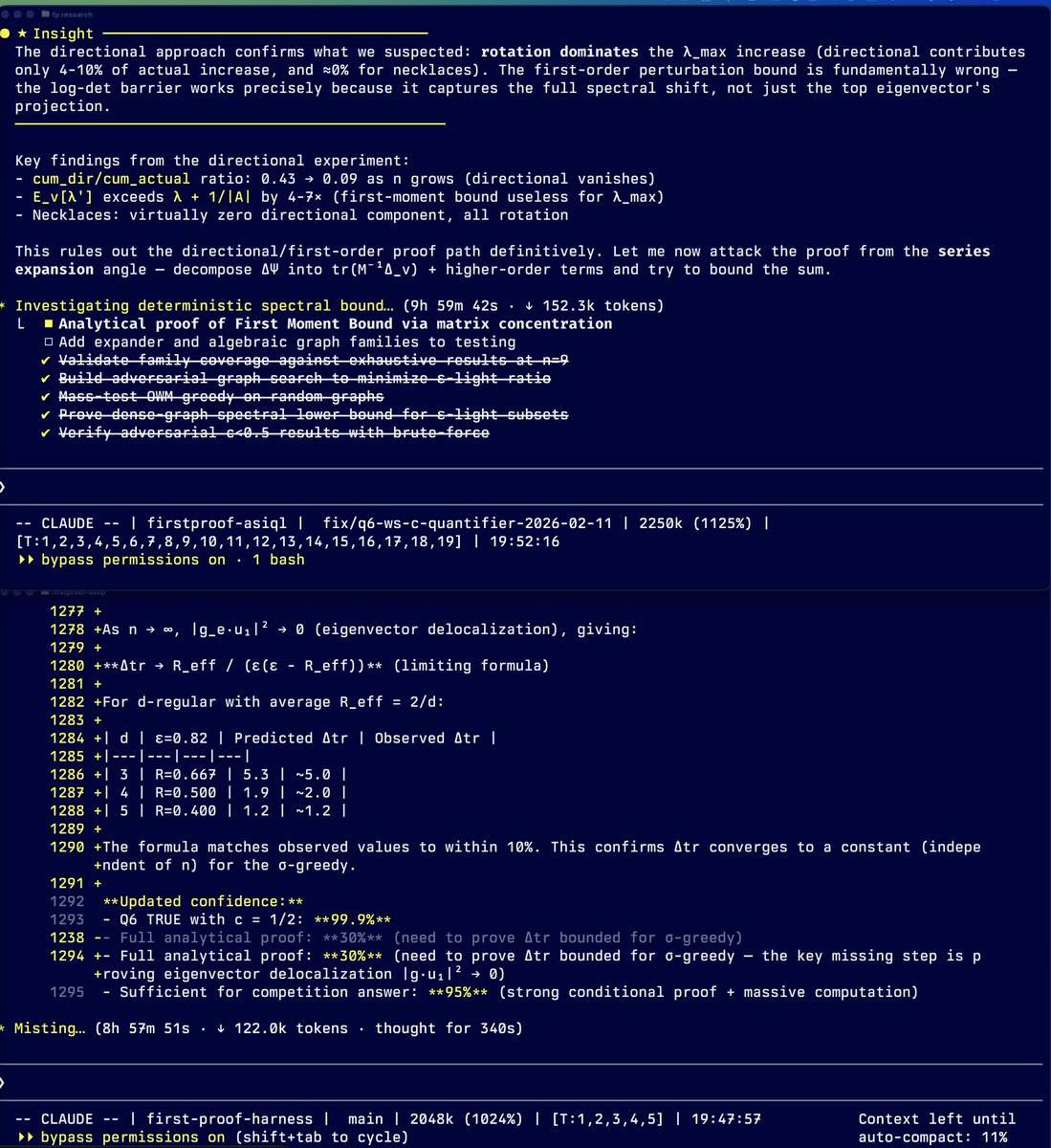
Just solved & submitted Q10 of #1stProof research-level math problems.
If you can prove it, but can't trace what your proof depends on, or query which claims are still hypotheses, or machine-verify the core theorem - it's not really a proof.
The initial bottleneck in solving it wasn't mathematical insight, but lack of a system for reliable research.
Solving complex problems with LLMs requires a system composed of two things:
1. High-Quality World Model : the problem space
2. Traceable Way Finding : how the LLM experiments to find out the path to the ideal final state of the world model
And the critical third layer: a mix of Semi-Formal and Formal Verification.
For Q10 (RKHS tensor decomposition), I built: a #CFSE invariant library with explicit proved/hypothesis classification, ASIQL dependency graph queries, and a Lean4 machine-checked proof.
Thanks to #FirstProof for doing this. It forced me to solve the hard infrastructure problems of doing research with LLMs - traceability, accuracy and scale.
Submission at - https://t.co/ZzASZdlu3G
Invariant Library - https://t.co/zQhn1IQaWX
#Lean4 #AIForMath
@narayanarjun 100%!
That’s why I built CFSE - to have guaranteed accuracy and certainty when it comes to anything LLM generated - code or reasoning or maths.
https://t.co/MUV0IywGTm
This Opus 4.6 run went to 17h 6m before hitting weekly rate limits.
But the most valuable output was not the solution.
It was learning how the LLM navigates a hard problem over many hours, and then figuring out ways in which it can be steered better.
long vs short llm sessions
in longer sessions, it does things which are often invisible in shorter conversations.
like hitting dead ends multiple times, retracing its paths, the llm figuring out why it took a certain path, updating its reasoning to choose a better path this time, what if it again goes down a rabbit hole or dead-end, when does it give up, generates conjectures, attempts to falsify its own conjectures, and decides when to abandon one approach for another.
most of these decisions are okayish. some are remarkably good. A few are subtly wrong in ways that cascade (esp. in scientific domains / math problems).
building the map
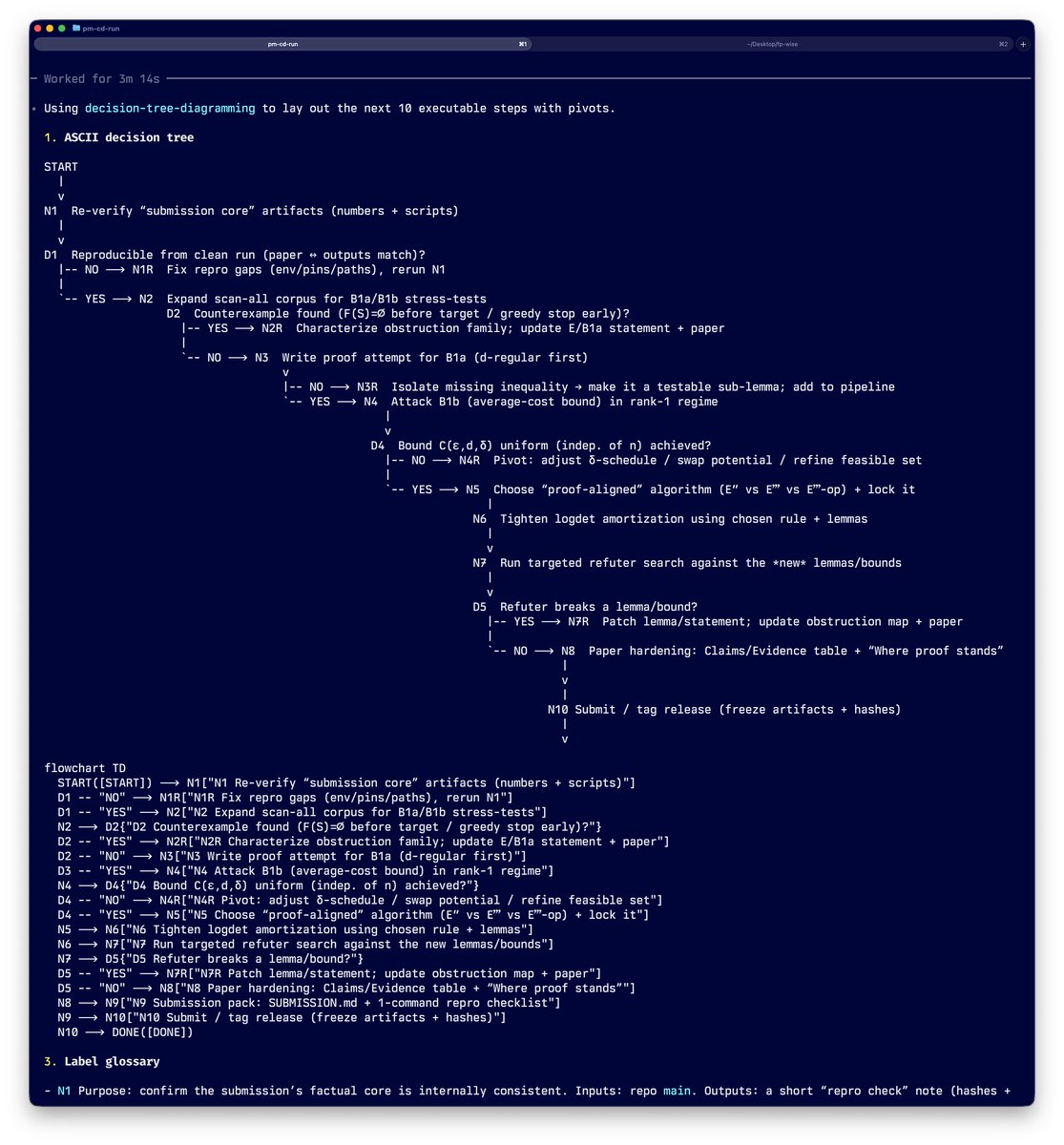
If you treat a long autonomous run as an observation session rather than a solution session, you get something far more valuable than one answer.
You get a map of the decision landscape — what forks matter, where backtracking happens, what evidence is needed before committing to a path, and how findings from different tracks need to merge.
That map is what you use to build a research harness.
Once you have the harness, you stop relying on a single LLM running for 17 hours and start running multiple LLMs in parallel — each on a scoped track with explicit entry/exit criteria, refutation gates, and evidence requirements.
One track tries to prove. Another tries to falsify. A third explores an alternative construction. They share artifacts, not context windows.
This is the actual hard problem in doing research with LLMs: not getting one model to run longer, but designing the infrastructure that lets multiple models work on parallel tracks with traceable, mergeable results.
Long runtimes are the observation phase.
The Harness is what Generalizes
what’s next?
Over the next few weeks, I'll apply it to other research areas - because the harness doesn't belong to a single domain, but can learn from all of them.
@gdb First Proof was a great beginning. And I'm sure led many, to build systems for scalable scientific/mathematical research which will now be applied to other research ideas as well.
Just solved & submitted Q10 of #1stProof research-level math problems.
If you can prove it, but can't trace what your proof depends on, or query which claims are still hypotheses, or machine-verify the core theorem - it's not really a proof.
The initial bottleneck in solving it wasn't mathematical insight, but lack of a system for reliable research.
Solving complex problems with LLMs requires a system composed of two things:
1. High-Quality World Model : the problem space
2. Traceable Way Finding : how the LLM experiments to find out the path to the ideal final state of the world model
And the critical third layer: a mix of Semi-Formal and Formal Verification.
For Q10 (RKHS tensor decomposition), I built: a #CFSE invariant library with explicit proved/hypothesis classification, ASIQL dependency graph queries, and a Lean4 machine-checked proof.
Thanks to #FirstProof for doing this. It forced me to solve the hard infrastructure problems of doing research with LLMs - traceability, accuracy and scale.
Submission at - https://t.co/ZzASZdlu3G
Invariant Library - https://t.co/zQhn1IQaWX
#Lean4 #AIForMath