you know what
all of these "which is better" polls are silly
use codex or claude code, whatever works best for you
i am grateful we live in a time with such amazing tools, and grateful there is a choice
Palo Alto is one of the few places where you walk into a random café and, within 5 minutes,
somebody stops you saying, “I know you from your papers”… and then you casually run into @gabriberton and chat about SLAM.
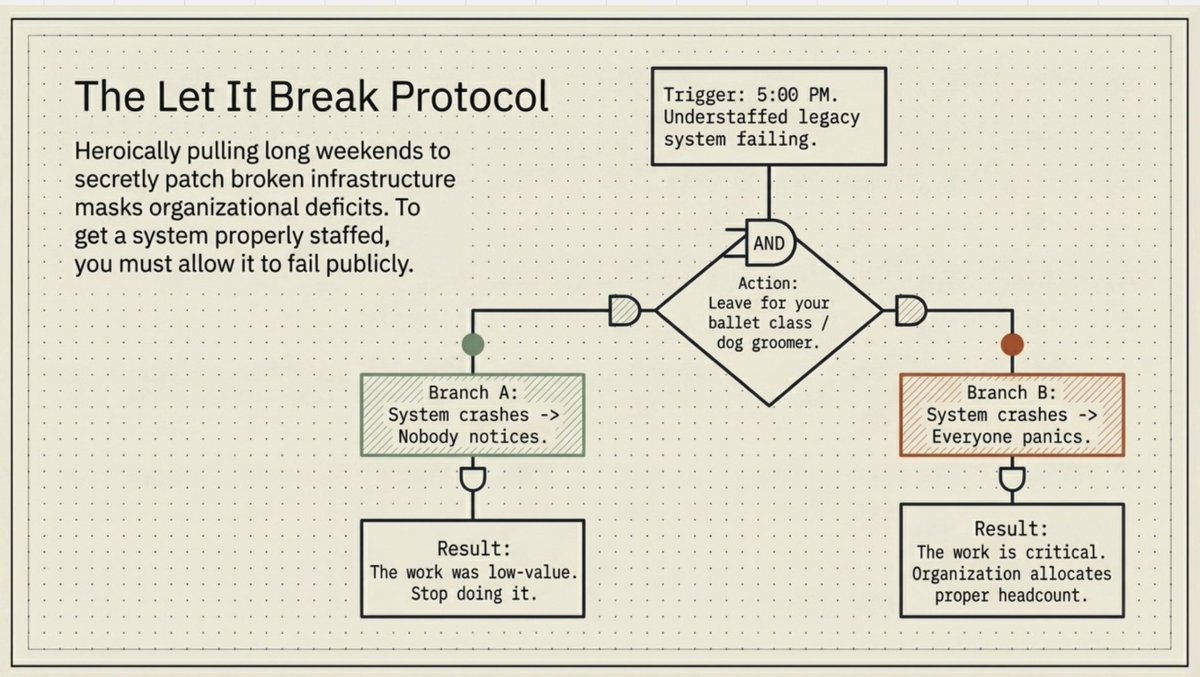
Google has an internal "let it break" essay about a hero engineer whose hard work ends up being a net negative (by masking the underlying issues). My manager sent me that essay when I was trying too hard to get the collective TensorFlow unit test suite green.
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
Not a single meaningful company has yet to say that they are making at least 2x+ from all of this incremental money they are spending since even last Fall!
When ROI?
Champions ⭐️⭐️⭐️ Phenomenal win for Team India in Ahmedabad. Absolutely no match for the explosive cricket played by us throughout the tournament. Brilliant character shown by the boys to keep fighting in tough situations and become world champions once again. Congratulations to all the players and all the members of the management for achieving this feat. Jai Hind 🇮🇳❤️
@prajdabre Need micro batching and data parallelism to solve this.
GPU 1 must finish processing the first 4 layers before GPU 2 can even start on the next 4, and while GPU 2 is working, GPUs 1, 3 and 4 sit idle. Only one GPU is active at any time (<25% GPU utilization)