I just ran the first n=1 dynamic regulome experiment. On myself.
A 72-hour fast where we tracked all 4,000+ components of the genome regulatory 'software' to see how they respond
And over 30% changed, most never mentioned in fasting literature
Why does this matter?
Well, why do you sometimes wake up feeling like garbage after eight hours of sleep? Your HRV looks fine. You got your morning sunlight. Your bloodwork is normal. Even your genome doesn't have a glaring mutation.
The answer lives in the regulome. It's your body’s real-time operating system, interpreting the environment and making decisions
It decides how your genome responds to stress, sleep, food, toxins, exercise, and more.
Now we can finally read it. Full write-up in the comments.
More experiments coming:
- Sleep deprivation (new baby incoming)
- Ultramarathon recovery
- Sauna // ice bath
- Alcohol
What else do you want to see? Follow along. Subscribe for updates. Apply for access to our tech.
We’re just getting started.
Its hilarious the extent to which people dont understand that mass specs actually work amazingly well right now today for protein sequencing
I think it is primarily the fault of our community in doing a poor job of applying the technology.
🐠 Everything we know about biology has been built on an incomplete picture. DNA tells us what a cell might do. Proteins tell us what it’s actually doing.
Pumpkinseed announced their $20M Series A today (led by Future Ventures and NfX) to build the platform that reads proteins directly—for the first time.
Proteomics has always faced a fundamental constraint: you can only measure what you already know to look for.
The current workhorse, mass spectrometry, requires matching protein fragments against reference databases. If a protein isn't in the database, or doesn't ionize reliably, it's invisible. Other approaches rely on fluorescent labels or antibody-based affinity methods, which introduce their own biases and blind spots.
The result is a field that has spent decades generating an increasingly detailed map of a small, well-lit corner of the proteome, while biology’s most important data layer remains hidden.
This isn't a sensitivity problem. It's a category problem. Existing tools were never designed to read proteins directly de novo. They were designed to find what researchers already suspected was there.
Pumpkinseed is built to find everything else. And proteomics is harder than most people outside the field appreciate. When we account for post-translational modifications, non-canonical amino acids, and glycan decorations, there are roughly a thousand distinct chemical monomers in the proteomic alphabet, compared to the four bases of DNA.
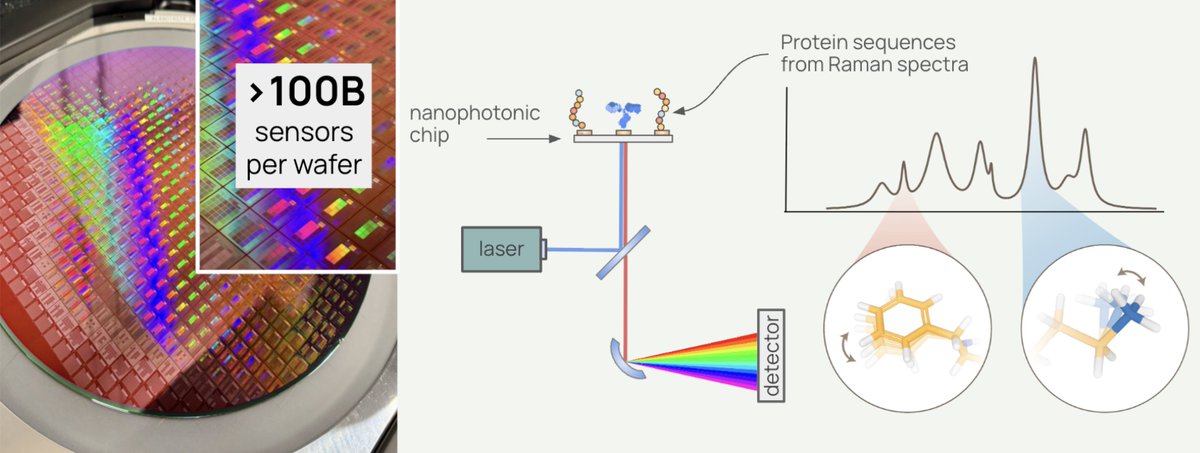
deSIPHR (de novo Sequencing and Identification of Proteins with High-throughput Raman spectroscopy) is Pumpkinseed's proprietary nanophotonic chip platform, fabricated with semiconducting manufacturing.
With over 100 million sensors per square centimeter, it reads proteins, known or unknown, letter by letter — amino acid by amino acid — without a reference catalog of proteins, and at high-throughput. The result is direct, high-resolution proteomic data, including post-translational modifications, non-canonical amino acids, and single-cell detail, that mass spectrometry-based approaches cannot match.
What is Raman spectroscopy? Rather than tagging or fragmenting proteins, Raman spectroscopy reads the molecular vibrations of individual molecules. Each amino acid vibrates at a characteristic frequency, producing a unique physical signature that deSIPHR detects directly. This is physics reading biology in the most literal sense.
With conventional Raman spectroscopy, only about one in ten million photons interacts with a molecule usefully, far too weak for single-molecule work. Pumpkinseed's answer is a silicon photonic chip patterned with a billion sensors per wafer. Those sensors concentrate light into volumes smaller than a single protein, amplifying Raman scattering efficiency by over 10 million-fold.
And their future ventures?
“The longer-term ambition is the virtual cell, a computational model that simulates not just how proteins fold but how they interact, respond to drugs, and behave under perturbation inside a living system. AlphaFold demonstrated what structural AI can do once a sequence is known. The gap that cannot be closed is determining the sequence itself from biological samples, particularly for proteins carrying modifications absent from existing databases. Pumpkinseed is designed to supply that input layer.
"If the Human Genome Project was the data infrastructure that enabled genomic medicine, we believe the high-resolution proteomic dataset Pumpkinseed is building could be the analogous foundation for AI-driven biological discovery," co-founder Dr. Jen Dionne says. "In our vision, the molecular signatures driving disease, aging, and ecosystem health become fully legible. Medicine shifts from reactive to proactive. Optimal healthspan moves from aspiration to achievable reality." —https://t.co/BVnCMSuebR
• The biology mining company: https://t.co/1HJuyEUxP1
• Today’s News: https://t.co/FKShnGS8CV
Drug hunters everywhere, sear the lesson of Revmed and daraxonrasib in your brain:
Life is too short for incrementally me-too and me-better. Drug the fucking undruggrable and you can double OS, even in pancreatic cancer.
Absolutely inspiring. LFG.
There’s an enormous gap in the longevity field that almost no one is talking about.
No existing therapeutic modalities are capable of both systemic distribution and complex transformations.
Until we solve this, we won’t solve aging. 🧵
Nice progress on drugging p53. It’s true that we need to find new targets, but it’s also important to keep expanding the druggable universe with better technologies.
Lots of great targets we already know about that are just waiting for the right molecule
Seeing several platform biotech companies from the '21 boom roaring back with compelling programs after staying heads down for a few years. Exciting times
Did anyone else notice that the PRV was renewed last week?
If you develop a medicine for a rare pediatric disease in the next 3 years, you get a voucher worth $150M+
So why isn’t there an orphan drug gold rush underway?
Imagine not having to test transcription factors one-by-one to rejuvenate cells / avoid cancer
We'd need an AI trained on real TF activity data that actually understands how this network of 1000s of proteins behaves
That’s our bet at Talus Bio. Observe the regulome, learn the rules, then control it.
New study: for years Yamanaka factors have driven longevity optimism. They factory reset cellular age, also erase the cellular identity. The drawback is potential cancer.
Transcription Factor Perturbations is a new scalpel approach targeting specific rejuvenation levers while keeping the cell's identity.
Example breakthrough
EZH2: mouse liver age reversal by 8 human-year equivalent by reducing liver fibrosis and fat by 50% and significantly improving glucose tolerance.
Study details
Transcriptional factors, particularly the Yamanaka factors (OSKM), are key to understanding and potentially reversing aging. OSKM can perform a cellular "factory reset," erasing epigenetic memory and inducing a stem cell-like state. Partial reprogramming with OSKM offers a path to rejuvenation, but its clinical use requires precise temporal and dosage control to prevent dedifferentiation and tumor formation.
A recent study established a Transcriptional Rejuvenation Discovery Platform (TRDP) to identify novel transcription factor perturbations capable of driving cellular rejuvenation and reversing aspects of replicative aging in human fibroblasts. The platform was trained on transcriptional shifts between early- and late-passage human cells in culture to identify gene expression and transcription factor changes associated with aging. These changes were ranked computationally to prioritize transcription factors relevant to rejuvenation.
The top 200 candidates were screened by parallel overexpression (CRISPRa) or inhibition (CRISPRi), followed by single-cell RNA sequencing to evaluate transcriptional consequences. Rejuvenating factors were identified by their ability to reverse aging-associated gene expression, quantified by a negative correlation score (R₍rej₎). Four were selected for further study: inhibition of STAT3 and ZFX, and activation of EZH2 and E2F3.
Findings in human cells (fibroblasts in cell culture)
In high-passage cells, all four perturbations induced rejuvenation-associated phenotypes, including increased proliferation (KI67), improved proteasome activity, reduced lysosomal staining, p21 downregulation, and improved mitochondrial function (strongest with EZH2). These effects mirrored in vitro OSKM reprogramming for the measured hallmarks, but without changing cellular identity. DNA methylation clocks remained stable, consistent with the decoupling of senescence and epigenetic aging.
Findings in aging mouse livers
For in vivo validation, the aging mouse liver was chosen. EZH2 was selected due to its age-associated decline, favorable safety profile over E2F3, and lack of STAT3-like disease-specific liver involvement. Three weeks of liver-specific EZH2 overexpression via AAV8 delivery reversed aging-associated gene expression and phenotypes by an equivalent of roughly eight months of mouse aging, including reductions in steatosis and fibrosis and improvements in glucose tolerance.
EZH2 overexpression produced stronger rejuvenation-associated transcriptional changes in vivo than those observed in vitro, particularly affecting inflammatory pathways and age-related loss of cellular identity, including inappropriate activation of muscle and cardiac gene programs in aged liver tissue. In 20-month-old mice, fibrosis and glucose intolerance improved by approximately 50% relative to young mice. Importantly, cellular identity was preserved, no liver damage or histological abnormalities were observed, and comparisons with multiple mouse liver cancer models showed no overlap with cancer-associated transcriptional signatures over the short treatment window.
Significance
This work introduces a systematic framework for identifying transcriptional factors as potential levers for longevity and rejuvenation. EZH2 emerges as a promising target for further exploration via gene therapy or targeted modulators, based on rejuvenation-associated signatures observed in human fibroblasts and functional rejuvenation of the aging mouse liver without overt damage or cancer-like signals.
While the OSKM reprogramming strategy demonstrate the reversibility of aging through global epigenetic resetting, it carries intrinsic risks related to identity destabilization. In contrast, targeted transcription factor perturbations enable the reversal of multiple aging-associated hallmarks without engaging in full or partial reprogramming, suggesting a more precise and potentially safer route to rejuvenation. These distinct approaches collectively indicate that rejuvenation operates across various biological layers, from broad epigenetic resets to targeted transcriptional network recalibration.
Limitations
The current screening strategy and computational model are biased towards transcription factors effective in replicative aging models of passaged neonatal human dermal fibroblasts, which differ substantially from organismal aging in vivo. While many hallmarks overlap, this model does not fully capture aging in post-mitotic cells or complex tissue and organ environments.
The platform uses cellular proliferation and survival in culture as proxies for rejuvenation, whereas in vivo aging is influenced by additional factors such as differentiation state, immune interactions, and intercellular communication. Reliance on proliferative capacity also carries inherent oncogenic risk. Although cancer-associated transcriptional signatures were not observed in this study, longer-term effects cannot be excluded.
Finally, liver rejuvenation was demonstrated in a single organ over a short treatment period in mice. The absence of damage or oncogenic signatures cannot be considered a definitive safety signal, and long-term studies, including large-animal and non-human primate models, will be required to establish safety, durability, and systemic relevance.
proteomics is closer to biology than RNA-seq
functional proteomics is closer to biology than 'regular' proteomics
let's build virtual cells with better data
Target crowding is a real issue, but centralized subsidy seems like a gift to the subsidized, not a gift to patients.
To encourage more novel-target discovery, I’d prefer a “cover song fee” — 5% mandatory royalty back to the first innovator that hits ph2 with a new target.
Innovator shouldn’t block new entrants with improved pk/pd like they used to 30 years ago — but innovators deserve to get paid when they lay the groundwork for future cures… even if their specific attempt fails. It’s a risky business we’re in!
And it shouldn’t matter how the drugs are made! AI, immunization, spontaneous discovery — however you get there, a drug in patients is a drug we can learn from.
Underrated for sure
This is why we're building the biggest dataset ever of transcription factor function and how to change function with small molecules
AlphaFold can't even predict Tf structure, we think this is the way
Underrated Ideas in Biotech (#7)
AlphaFold predicts a protein's structure solely by looking at its sequence. But structure does not always suggest function. The next frontier is to train a model that can predict any protein's FUNCTION solely from its sequence.
This is incredibly important because the most useful tools in biotechnology come from NATURE. The thermostable polymerase used in PCR came from microbes in a Yellowstone geyser. The "repeats" in CRISPR were first identified in extremophilic microbes in Spain. GFP was discovered in a jellyfish. The list goes on.
If we had a good model for sequence-to-function prediction, we could send biologists into nature to hunt for proteins with new, useful functions. They could sequence samples from the Arctic and jungles and oceans, upload those data into the model, and then discover lots of useful proteins that could be adapted into tools!
This vision is not so far from reality, either. A nonprofit, called The Align Foundation, is already collecting the datasets needed to train this predictive model. The training dataset needs three variables:
1. The amino acid sequences of proteins;
2. Some kind of "quantitative functional score" indicating how well each protein performs in an experiment;
3. A function-definition, aka a detailed description of the experiment used to benchmark what the protein does. (There are many "classes" of protein functions, like antibodies, proteases, transcription factors, and so on.)
Align is collecting millions of datapoints. They have scaled up a lot, and are now routinely collecting hundreds of thousands of data points in a single experiment, at a cost of ~$0.05 per protein.
Say Align wanted to collect data on antibiotic resistance proteins. They would take antibiotic resistance genes, mutate them to make thousands of variants, and insert those sequences (with unique 'barcodes') into living cells. Next, they'd expose the cells to an antibiotic. Cells with functional proteins survive; many others die. Some variants will do 'OK,' but those cells grow slowly. By sequencing the barcodes, they can quantify the population of each variant, and thus figure out which proteins are REALLY GOOD, JUST OKAY, or fail entirely.
Given these data, the next step is to train a model that predicts whether a given protein variant will be good or bad at defending a cell against antibiotics. The model will be good at doing this for antibiotic resistance proteins, but not much else! Align's goal, then, is to do these assays for proteins with many different functions and then "merge" them to build a model that can generalize across proteins.
"As the dataset grows and more islands are sampled [they write], the models will become more generalized and capable of predicting the function of protein sequences that are increasingly distant from those that have been...measured."
I hope this works. It would legitimately be one of the greatest unlocks for biotech progress more broadly.
The recent breakthroughs from @nablabio & @chaidiscovery emphasize a split in early biotech strategy.
For the specific range of problems that antibodies address, making the binder, is becoming trivial. This forces a choice between 'fast but competitive' and 'AI intractable'. 🧵
The recent breakthroughs from @nablabio & @chaidiscovery emphasize a split in early biotech strategy.
For the specific range of problems that antibodies address, making the binder, is becoming trivial. This forces a choice between 'fast but competitive' and 'AI intractable'. 🧵














![NikoMcCarty's tweet photo. Underrated Ideas in Biotech (#7)
AlphaFold predicts a protein's structure solely by looking at its sequence. But structure does not always suggest function. The next frontier is to train a model that can predict any protein's FUNCTION solely from its sequence.
This is incredibly important because the most useful tools in biotechnology come from NATURE. The thermostable polymerase used in PCR came from microbes in a Yellowstone geyser. The "repeats" in CRISPR were first identified in extremophilic microbes in Spain. GFP was discovered in a jellyfish. The list goes on.
If we had a good model for sequence-to-function prediction, we could send biologists into nature to hunt for proteins with new, useful functions. They could sequence samples from the Arctic and jungles and oceans, upload those data into the model, and then discover lots of useful proteins that could be adapted into tools!
This vision is not so far from reality, either. A nonprofit, called The Align Foundation, is already collecting the datasets needed to train this predictive model. The training dataset needs three variables:
1. The amino acid sequences of proteins;
2. Some kind of "quantitative functional score" indicating how well each protein performs in an experiment;
3. A function-definition, aka a detailed description of the experiment used to benchmark what the protein does. (There are many "classes" of protein functions, like antibodies, proteases, transcription factors, and so on.)
Align is collecting millions of datapoints. They have scaled up a lot, and are now routinely collecting hundreds of thousands of data points in a single experiment, at a cost of ~$0.05 per protein.
Say Align wanted to collect data on antibiotic resistance proteins. They would take antibiotic resistance genes, mutate them to make thousands of variants, and insert those sequences (with unique 'barcodes') into living cells. Next, they'd expose the cells to an antibiotic. Cells with functional proteins survive; many others die. Some variants will do 'OK,' but those cells grow slowly. By sequencing the barcodes, they can quantify the population of each variant, and thus figure out which proteins are REALLY GOOD, JUST OKAY, or fail entirely.
Given these data, the next step is to train a model that predicts whether a given protein variant will be good or bad at defending a cell against antibiotics. The model will be good at doing this for antibiotic resistance proteins, but not much else! Align's goal, then, is to do these assays for proteins with many different functions and then "merge" them to build a model that can generalize across proteins.
"As the dataset grows and more islands are sampled [they write], the models will become more generalized and capable of predicting the function of protein sequences that are increasingly distant from those that have been...measured."
I hope this works. It would legitimately be one of the greatest unlocks for biotech progress more broadly.](https://pbs.twimg.com/media/G7qaKpTagAQfCl8.jpg)





















![NikoMcCarty's tweet photo. Underrated Ideas in Biotech (#7)
AlphaFold predicts a protein's structure solely by looking at its sequence. But structure does not always suggest function. The next frontier is to train a model that can predict any protein's FUNCTION solely from its sequence.
This is incredibly important because the most useful tools in biotechnology come from NATURE. The thermostable polymerase used in PCR came from microbes in a Yellowstone geyser. The "repeats" in CRISPR were first identified in extremophilic microbes in Spain. GFP was discovered in a jellyfish. The list goes on.
If we had a good model for sequence-to-function prediction, we could send biologists into nature to hunt for proteins with new, useful functions. They could sequence samples from the Arctic and jungles and oceans, upload those data into the model, and then discover lots of useful proteins that could be adapted into tools!
This vision is not so far from reality, either. A nonprofit, called The Align Foundation, is already collecting the datasets needed to train this predictive model. The training dataset needs three variables:
1. The amino acid sequences of proteins;
2. Some kind of "quantitative functional score" indicating how well each protein performs in an experiment;
3. A function-definition, aka a detailed description of the experiment used to benchmark what the protein does. (There are many "classes" of protein functions, like antibodies, proteases, transcription factors, and so on.)
Align is collecting millions of datapoints. They have scaled up a lot, and are now routinely collecting hundreds of thousands of data points in a single experiment, at a cost of ~$0.05 per protein.
Say Align wanted to collect data on antibiotic resistance proteins. They would take antibiotic resistance genes, mutate them to make thousands of variants, and insert those sequences (with unique 'barcodes') into living cells. Next, they'd expose the cells to an antibiotic. Cells with functional proteins survive; many others die. Some variants will do 'OK,' but those cells grow slowly. By sequencing the barcodes, they can quantify the population of each variant, and thus figure out which proteins are REALLY GOOD, JUST OKAY, or fail entirely.
Given these data, the next step is to train a model that predicts whether a given protein variant will be good or bad at defending a cell against antibiotics. The model will be good at doing this for antibiotic resistance proteins, but not much else! Align's goal, then, is to do these assays for proteins with many different functions and then "merge" them to build a model that can generalize across proteins.
"As the dataset grows and more islands are sampled [they write], the models will become more generalized and capable of predicting the function of protein sequences that are increasingly distant from those that have been...measured."
I hope this works. It would legitimately be one of the greatest unlocks for biotech progress more broadly.](https://pbs.twimg.com/media/G7qaKzzaoAAyVwD.jpg)



















