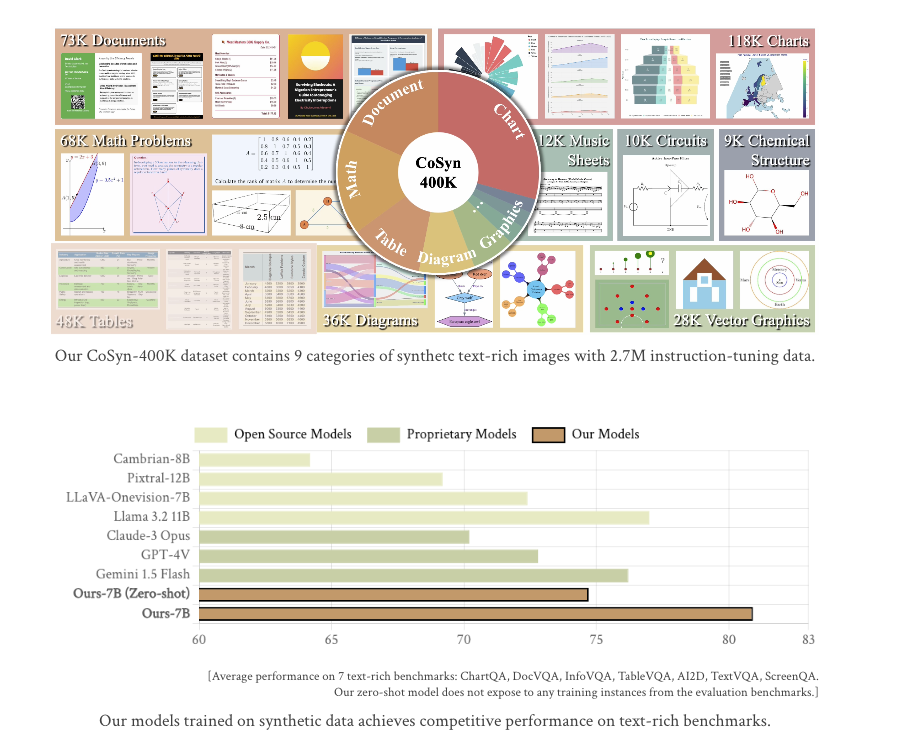
We share Code-Guided Synthetic Data Generation: using LLM-generated code to create multimodal datasets for text-rich images, such as charts📊, documents📄, etc., to enhance Vision-Language Models.
Website: https://t.co/U2y96rxMzS
Dataset: https://t.co/AT4QmiYwdp
Paper: https://t.co/mZFpN7kYoP
Code: https://t.co/HyDdcuwjsn
🚀 Synthetic data is revolutionizing AI & ML!
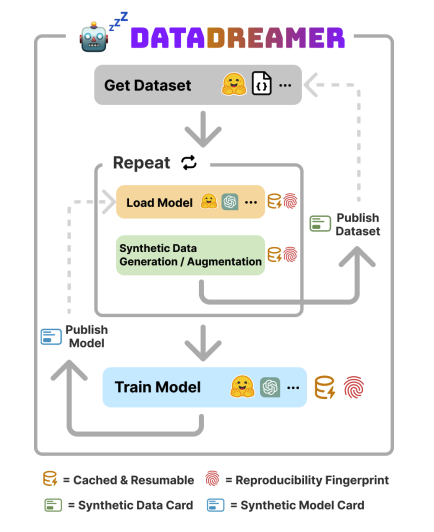
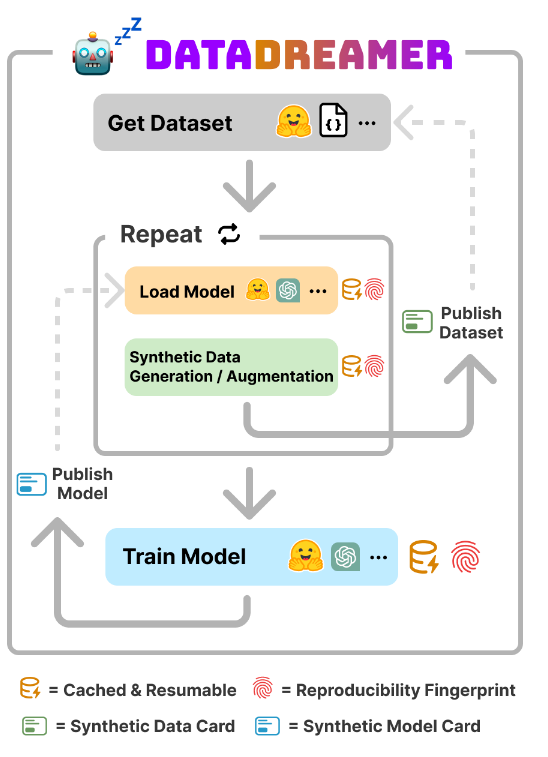
DataDreamer, an open-source Python library, makes generating synthetic data seamless & integrates effortlessly with @huggingface . Easily push datasets to the Hub and share them with the community
🔍 Learn how: https://t.co/oyZ6bpqXU1
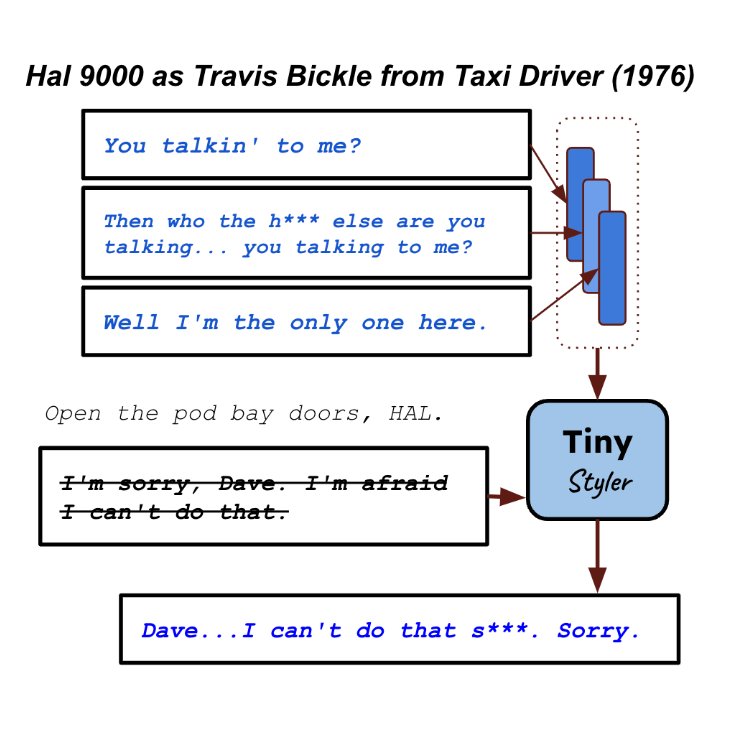
I'm at #EMNLP2024 presenting ✨TinyStyler✨, an efficient, effective, and fast method for few-shot text style transfer!
Paper: https://t.co/xQmMHvy8tk
Demo: https://t.co/DQ3OEZrC67
Code: https://t.co/aYS5lqwqAj
Olmo goes multimodal!
We are launching Molmo, a open family of multimodal models that rival the best closed VLMs out there 🤯
We spent the last 9 months meticulously curating PixMo, a dataset of (a) high-quality image-caption pairs and (b) multimodal instruction data.
Very nice coverage of @csspenn's just-launched Media Bias Detector. I'm very excited about this project, which has been a Herculean team effort!
https://t.co/FlCSIfBp5L
https://t.co/j5L4aRBzDN
New exciting research by @DinuMariusC with @ajayp95 (U of Pennsylvania) and @ExtensityAI. We show LLM self-improvement with synthetic data for web agent tasks on WebArena, and introduce an extended VERTEX score for measuring the trajectory quality of agent workflows.
Excited to present our work “Large Language Models Can Self-Improve At Web Agent Tasks”. We show that synthetic data self-improvement boosts task completion by 31% on WebArena and introduce quality metrics for measuring autonomous agent workflows. #AI#MachineLearning#LLMs [1/n]
Large Language Models Can Self-Improve At Web Agent Tasks
abs: https://t.co/G84JKYmK49
"We explore fine-tuning on three distinct synthetic training data mixtures and achieve a 31% improvement in task completion rate over the base model on the WebArena benchmark through a self-improvement procedure."
DataDreamer
A Tool for Synthetic Data Generation and Reproducible LLM Workflows
Large language models (LLMs) have become a dominant and important tool for NLP researchers in a wide range of tasks. Today, many researchers use LLMs in synthetic data generation, task evaluation, fine-tuning, distillation, and other model-in-the-loop research workflows. However, challenges arise when using these models that stem from their scale, their closed source nature, and the lack of standardized tooling for these new and emerging workflows. The rapid rise to prominence of these models and these unique challenges has had immediate adverse impacts on open science and on the reproducibility of work that uses them. In this paper, we introduce DataDreamer, an open source Python library that allows researchers to write simple code to implement powerful LLM workflows. DataDreamer also helps researchers adhere to best practices that we propose to encourage open science and reproducibility.
Are GPT-style LMs best for prompting🤔? Our work shows maybe not! Catch us at the poster for "Bidirectional Language Models are Also Few-Shot Learners" (joint w/ @ajayp95, @colinraffel
) in person at #ICLR2023 in Kigali May 3, 11:30-1:30 PM #162 or https://t.co/p8TZHJBstE
Bidirectional LMs like T5 learn superior representations, but the field mostly trains unidirectional LMs like GPT-3 since the "emergent" property of prompting was never seen in T5. We show that T5 can be prompted, outperforming GPT-3 with 50% fewer params. https://t.co/WNUa3HvnVk





























![DinuMariusC's tweet photo. Excited to present our work “Large Language Models Can Self-Improve At Web Agent Tasks”. We show that synthetic data self-improvement boosts task completion by 31% on WebArena and introduce quality metrics for measuring autonomous agent workflows. #AI #MachineLearning #LLMs [1/n] https://t.co/qBIV6lfw6h](https://pbs.twimg.com/media/GO6KikDaoAEisGP.png)