🎉 Meet our WiCV 2026 at @CVPR speakers!
We are honoured to welcome Cordelia Schmid, Sarah Parisot, Georgia Gkioxari, Sanja Fidler, and Katie Bouman for inspiring talks and discussions on the future of computer vision.
https://t.co/hCpis14Ime
See you at CVPR!
#WiCV#CV
If you want to work with our group while living in New-York and also spend time in Tokyo and Germany!, check out the new positions available at the NYU and Flatiron Institute by @cosmo_shirley
post-doc: https://t.co/TvVTBiAiol
research-scientist: https://t.co/ivqess9uKb
Really excited that our workshop on weight-space symmetries @weightsymmetry is one of the accepted workshops this year at @icmlconf. Please consider submitting your work, see you all in Seoul!
I will be presenting "Generative Re-Photography with Video Models" at several places over the next month. Hit me up if you are around!
MIT Media Lab-Apr 1
Harvard-Apr 2
MIT CSAIL-Apr 7
Cornell Tech-Apr 9
Princeton-Apr 10
CMU-Apr 13
Stanford-Apr 24
Berkeley-Apr 28
We're launching the European Student Robotics Association (ESRA, @esra_robotics) (13 universities, 8 countries, 2.5k+ members)!
We’re young, driven and together we’re tackling the European fragmentation problem heads on.
Who are we?
- ETH Robotics Club (Zürich) @ethroboticsclub
- RoboTUM (Münich)
- EPFL AI Team (Lausanne) @epflaiteam
- Unaite (Paris)
- Team Polar (Eindhoven)
- TU Wien Robotics Club (Vienna)
- Robotics Collective (Aachen) @robocollectiv
- KTH AI Society (Stockholm) @KTHAISociety
- Delft Robotics Student Association
- KN CybAiR (Poznan)
- AEA Polimi (Milan)
What do we do?
→ Pan-European robotics competitions
→ Cross-border technical project collaborations
→ Coordinated access to funding opportunities across Europe
And this is just the beginning!
Thanks @andreasklinger, @lukas_m_ziegler and @IlirAliu_ for helping us spread the word :)
Meet Lisa Koch, Asst. Professor Bern Uni 🇨🇭 & ELLIS Member. Her research: ML for biomedical data & medical imaging, with a focus on trustworthy AI. Her goal: "certifiably safe & effective ML tools aligned with clinicians' & patients' needs."
#WomenInELLIS
Career Update: After 6 formative years at FAIR, I'm joining @sainingxie, @ylecun and @jingli9111 at @amilabs to work on the second paradigm of pre-training: world modeling.
Next word prediction gave us language intelligence. Next physical state prediction is how we get physical intelligence.
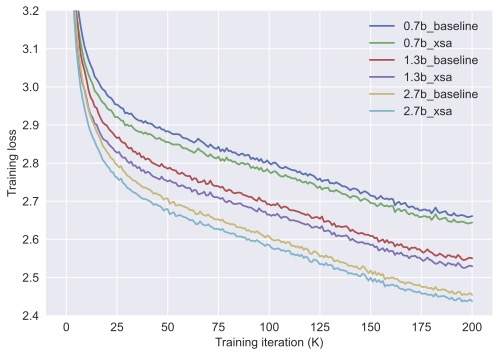
Say hi to Exclusive Self Attention (XSA), a (nearly) free improvement to Transformers for LM.
Observation: for y = attn(q, k, v), yᵢ and vᵢ tend to have a very high cosine similarity
Fix: exclude vᵢ from yᵢ via zᵢ = yᵢ - (yᵢᵀvᵢ)vᵢ/‖vᵢ‖²
Result: better training/val loss across model sizes; increasing gains as sequence length grows.
See more: https://t.co/fiX3JbU4HW
Meet @akshitac8, #ELLISPhD at @TUDarmstadt 🇩🇪 w/ an exchange at Google Zurich🇨🇭. Her research area is multimodal reasoning & generation with focus on developing methods for long-form videos.
By sharing her experiences, she hopes to help others feel encouraged 👏🏻
#WomenInELLIS
world modeling is never about rendering pixels.
rendering is local. world state is global. as soon as more than one agent exists, the only thing that truly matters is the shared representation beneath individual views. that shared representation is what scales into collective capability.
this is why I'm super excited to share project Solaris -- our new work focused on building a multiplayer video world model in minecraft.
This release includes three main pieces.
1⃣Solaris Engine, a fully featured multiplayer data collection system with built in visuals. the team put a huge amount of work into this since nothing like it really exists yet.
https://t.co/dw9lTmr9Pk
2⃣Solaris Model, a multiplayer DiT with a new memory efficient self forcing design, trained on 12.6M frames of coordinated Minecraft gameplay.
https://t.co/cVjlGKcNUf
3⃣Solaris Eval, which uses a VLM as a judge to evaluate different multiplayer capabilities.
read the full technical breakdown by @ojmichel4, and start building with Solaris.
https://t.co/1NkdqSRZy5
🎮 We release VisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents (w/ @junyi42@aomaru_21490)
🌐 With 17 environments across multiple domains, we show systematically the brittleness of VLMs in visual interaction, and what training leads to.
🧵[1/8]
New #NVIDIA Paper
We introduce Motive, a motion-centric, gradient-based data attribution method that traces which training videos help or hurt video generation.
By isolating temporal dynamics from static appearance, Motive identifies which training videos shape motion in video generation.
🔗 https://t.co/TbKXjQMN3H
1/10
With a new year comes a new Editor-in-Chief! Please give a warm welcome to Laurent Charlin (@lcharlin, @HEC_Montreal and @Mila_Quebec)!
He rounds out the team with Gautam Kamath (@thegautamkamath), Naila Murray (@NailaMurray) and Nihar Shah to help lead TMLR through 2026.
Reposting, in case this went under the radar during NeurIPS. Phillip Isola, Saining Xie, and I will hire joint postdocs to work on multimodal learning.
Info and link to the form in the post below.
@phillip_isola@sainingxie
📢 Phillip Isola @phillip_isola, Saining Xie @sainingxie, and I @zamir_ar are hiring joint postdocs in machine learning with a focus on multimodal learning. What brings us together is our shared interest in multimodality and our intention to move the boundaries of current approaches in this area. Our team has access to substantial compute resources through the Swiss National Supercomputing Centre Swiss AI initiative and our industry partners. The postdocs will work at the intersection of our groups. For now the positions will be based at EPFL with visiting stays at MIT and NYU, and will be co-advised by two or all three of us.
🔗 Apply here if interested: https://t.co/4vkUCuPT0Z
Excited to share our paper “When Are Concepts Erased from Diffusion Models?” at @NeurIPSConf!
We introduce two conceptual models for erasure mechanisms in diffusion models, and a suite of probes to recover supposedly forgotten concepts.
Project website: https://t.co/pKQmjEASHK