Thank you @kotoba_tech and special thanks to @jungokasai and @noriyuki_kojima! Wonderful and rewarding experience in Tokyo for the summer, surrounded by such a passionate team of talented engineers. Always excited about Kotoba's next release and look forward to keeping in touch!
🔥 Excited to share my new preprint: Can LLMs Use Linguistic Uncertainty Markers to Reliably Reflect Intrinsic Confidence? 🔥
When an LLM says "I think" or "probably," does it actually mean something consistent internally? The answer: not really 😬
Check out details in 🧵(1/n):
I will be attending #EMNLP2025 this week to present LiteASR, a compression method for speech encoders (a collaborative work with @kotoba_tech).
Catch our poster at the first poster session on Wednesday morning. Happy to chat about efficiency, speech, or both!
As PhD students, we believe research automation systems should belong to everyone, not just Google, so we built freephdlabor.
Customize your multi-agent system for end-to-end research that WORKS FOR YOUR DOMAIN within hours.
full source code: https://t.co/NkiFnLwqVM
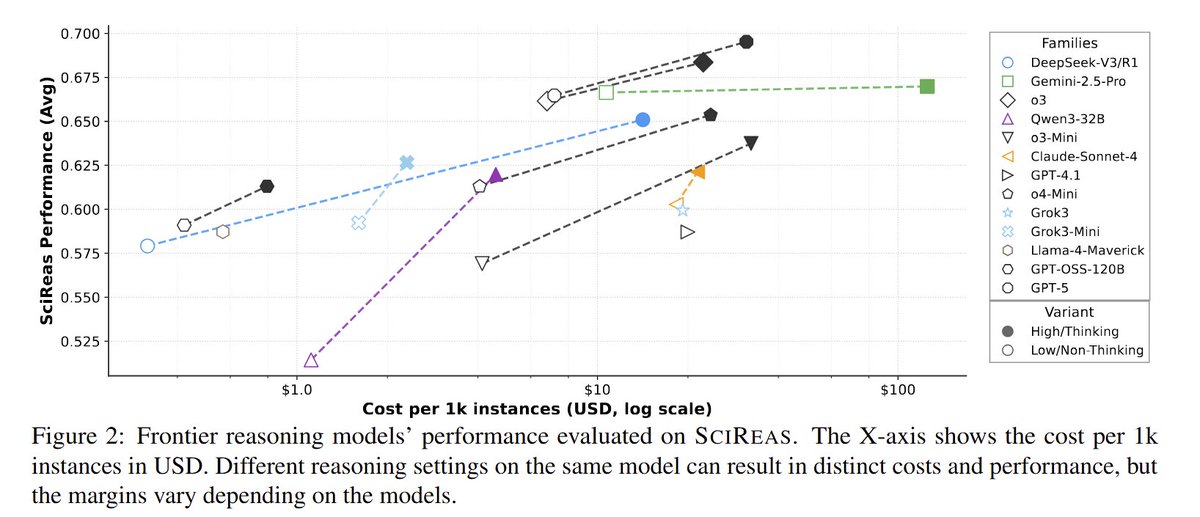
New Harvard+Yale paper says, strong reasoning helps, but accessing the right knowledge first is what really limits performance.
So knowledge recall is the main bottleneck in scientific problem solving with LLMs.
They build benchmark suites SCIREAS and SCIREAS‑PRO to measure scientific reasoning end to end
They also release a simple 8B baseline for science tasks that benefits from a math+STEM mix.
🎯 The problem
Scientific questions need 2 things at once, solid domain knowledge and multi‑step reasoning, but most tests only hit one side or lock into one format.
There was no unified way to score science reasoning across domains, and almost no clean way to tell whether a model failed because it lacked a fact or because it could not reason with the fact.
1/9 🚀 New paper: Demystifying Scientific Problem-Solving in LLMs — How does reasoning enhancement affect knowledge recall, and do LLMs benefit from external knowledge complimentary to reasoning?
Tldr;
📊 SciReas: holistic and efficient evaluation suite for scientific reasoning
🧠 KRUX: a novel framework to study knowledge vs reasoning in LLMs
🔑 Findings: knowledge is a bottleneck; reasoners + in-context knowledge help; long CoT helps knowledge recall/utilization
8/9 This work is a collaboration between YaleNLP @yalenlp and Ai2 @allen_ai .
Code/benchmark 📈 https://t.co/uCVKwpXhvl.
Paper: 📄 https://t.co/XP8011DqsU
Models: 🤗 https://t.co/Qm9SzmBh4p
Today at 4 PM, we’re presenting our tutorial:
“Evaluating LLM-based Agents: Foundations, Best Practices, & Open Challenges”
If you’re in Montreal for @IJCAIconf, come join us to dive into the future of #AgentEvaluation! 🇨🇦🤖
w. @RoyBarHaim@LilachEdel and @alanli2020
Excited for the release of SciArena with @allen_ai!
LLMs are now an integral part of research workflows, and SciArena helps measure progress on scientific literature tasks.
Also checkout the preprint for a lot more results/analyses. Led by: @YilunZhao_NLP, @kaiyan_z
📄 paper: https://t.co/BW09ssX5Ig
This was a massive team effort and we're thrilled to finally share it!
Excited to see more investigation into LLM creativity. We have some pioneering work on this topic as well:
Creativity or Brute Force?
Using Brainteasers as a Window into the
Problem-Solving Abilities of Large Language Models. https://t.co/QNyQp1Zs80.