BREAKING: You no longer need to hire a designer.
Claude + Figma just replaced a $10,000 agency workflow in under 3 hours.
Here are 7 Claude + Figma prompt combos that build production-ready websites from scratch:
Bookmark this.
My pleasure to come on Dwarkesh last week, I thought the questions and conversation were really good.
I re-watched the pod just now too. First of all, yes I know, and I'm sorry that I speak so fast :). It's to my detriment because sometimes my speaking thread out-executes my thinking thread, so I think I botched a few explanations due to that, and sometimes I was also nervous that I'm going too much on a tangent or too deep into something relatively spurious. Anyway, a few notes/pointers:
AGI timelines. My comments on AGI timelines looks to be the most trending part of the early response. This is the "decade of agents" is a reference to this earlier tweet https://t.co/NiSn6jftqq Basically my AI timelines are about 5-10X pessimistic w.r.t. what you'll find in your neighborhood SF AI house party or on your twitter timeline, but still quite optimistic w.r.t. a rising tide of AI deniers and skeptics. The apparent conflict is not: imo we simultaneously 1) saw a huge amount of progress in recent years with LLMs while 2) there is still a lot of work remaining (grunt work, integration work, sensors and actuators to the physical world, societal work, safety and security work (jailbreaks, poisoning, etc.)) and also research to get done before we have an entity that you'd prefer to hire over a person for an arbitrary job in the world. I think that overall, 10 years should otherwise be a very bullish timeline for AGI, it's only in contrast to present hype that it doesn't feel that way.
Animals vs Ghosts. My earlier writeup on Sutton's podcast https://t.co/rSp1noyGBr . I am suspicious that there is a single simple algorithm you can let loose on the world and it learns everything from scratch. If someone builds such a thing, I will be wrong and it will be the most incredible breakthrough in AI. In my mind, animals are not an example of this at all - they are prepackaged with a ton of intelligence by evolution and the learning they do is quite minimal overall (example: Zebra at birth). Putting our engineering hats on, we're not going to redo evolution. But with LLMs we have stumbled by an alternative approach to "prepackage" a ton of intelligence in a neural network - not by evolution, but by predicting the next token over the internet. This approach leads to a different kind of entity in the intelligence space. Distinct from animals, more like ghosts or spirits. But we can (and should) make them more animal like over time and in some ways that's what a lot of frontier work is about.
On RL. I've critiqued RL a few times already, e.g. https://t.co/mYrMFVdVDW . First, you're "sucking supervision through a straw", so I think the signal/flop is very bad. RL is also very noisy because a completion might have lots of errors that might get encourages (if you happen to stumble to the right answer), and conversely brilliant insight tokens that might get discouraged (if you happen to screw up later). Process supervision and LLM judges have issues too. I think we'll see alternative learning paradigms. I am long "agentic interaction" but short "reinforcement learning" https://t.co/2L7FiaoKsw. I've seen a number of papers pop up recently that are imo barking up the right tree along the lines of what I called "system prompt learning" https://t.co/df5mJDdN3C , but I think there is also a gap between ideas on arxiv and actual, at scale implementation at an LLM frontier lab that works in a general way. I am overall quite optimistic that we'll see good progress on this dimension of remaining work quite soon, and e.g. I'd even say ChatGPT memory and so on are primordial deployed examples of new learning paradigms.
Cognitive core. My earlier post on "cognitive core": https://t.co/q2s1ihGy0T , the idea of stripping down LLMs, of making it harder for them to memorize, or actively stripping away their memory, to make them better at generalization. Otherwise they lean too hard on what they've memorized. Humans can't memorize so easily, which now looks more like a feature than a bug by contrast. Maybe the inability to memorize is a kind of regularization. Also my post from a while back on how the trend in model size is "backwards" and why "the models have to first get larger before they can get smaller" https://t.co/6k0FZRGXsb
Time travel to Yann LeCun 1989. This is the post that I did a very hasty/bad job of describing on the pod: https://t.co/fQgqaXPyp6 . Basically - how much could you improve Yann LeCun's results with the knowledge of 33 years of algorithmic progress? How constrained were the results by each of algorithms, data, and compute? Case study there of.
nanochat. My end-to-end implementation of the ChatGPT training/inference pipeline (the bare essentials) https://t.co/SIetgyoKWN
On LLM agents. My critique of the industry is more in overshooting the tooling w.r.t. present capability. I live in what I view as an intermediate world where I want to collaborate with LLMs and where our pros/cons are matched up. The industry lives in a future where fully autonomous entities collaborate in parallel to write all the code and humans are useless. For example, I don't want an Agent that goes off for 20 minutes and comes back with 1,000 lines of code. I certainly don't feel ready to supervise a team of 10 of them. I'd like to go in chunks that I can keep in my head, where an LLM explains the code that it is writing. I'd like it to prove to me that what it did is correct, I want it to pull the API docs and show me that it used things correctly. I want it to make fewer assumptions and ask/collaborate with me when not sure about something. I want to learn along the way and become better as a programmer, not just get served mountains of code that I'm told works. I just think the tools should be more realistic w.r.t. their capability and how they fit into the industry today, and I fear that if this isn't done well we might end up with mountains of slop accumulating across software, and an increase in vulnerabilities, security breaches and etc. https://t.co/8556ESSpyY
Job automation. How the radiologists are doing great https://t.co/FVUI872dkD and what jobs are more susceptible to automation and why.
Physics. Children should learn physics in early education not because they go on to do physics, but because it is the subject that best boots up a brain. Physicists are the intellectual embryonic stem cell https://t.co/p72Elk8lPV I have a longer post that has been half-written in my drafts for ~year, which I hope to finish soon.
Thanks again Dwarkesh for having me over!
Ivan Zhao is the founder of Notion.
He just held a 1 hour keynote at Notion's first in-person conference.
What he announced today, will blow your mind.
Here are the key takeaways (+8 new launches):
Mil gracias a todos
Many thanks to all
Merci beaucoup à tous
Grazie mille à tutti
谢谢大家
شكرا لكم جميعا
תודה לכולכם
Obrigado a todos
Vielen Dank euch allen
Tack alla
Хвала свима
Gràcies a tots
People with “founder mentality” can’t rest once a problem or opportunity is identified. They take on personal responsibility without complaint, learn & recruit skills as needed, and deliver results despite politics. There is unlimited global demand for founder mentality.
@naval
In 2010, YouTube had 800M active users + streamed 2B+ videos daily.
But internally, we were flying by the seat of our pants.
One burning question was on our minds:
How were people actually using YouTube?
Here's the story of how one UX researcher ignited sweeping changes to how the company approached building the product:
—
I joined YouTube in 2009 and still recall my first planning meeting with the search team.
We sat around a table and the PM asked:
“So what do you all think would be cool to build?”
In asking a few questions of my own, I realized the team had been building without understanding how people experienced the product.
We lacked the information to make informed choices about what to prioritize across YouTube.
And so we started to grow the research team.
—
In 2010, we convinced @kerryrodden (they/them), Google’s first Quantitative UX Researcher, to join YouTube.
To get oriented, Kerry started asking PMs, Designers, Engineers, Execs, and other UX Researchers what their most pressing questions were. One question came up again and again:
How were people actually using YouTube?
Kerry combed through existing qualitative research, and honed in on understanding how people navigated through the site.
To do this, Kerry jumped into YouTube’s user logs and was delighted to discover that YouTube’s data showed a user’s entire session — revealing a user’s navigation across all the pages they visited.
(Note: User sessions were completely anonymized, so no session data was attached to an identifiable person.
Also, usage data was separated from video content, so we analyzed only page types e.g., watch page or search results page, but not the actual videos or search queries.)
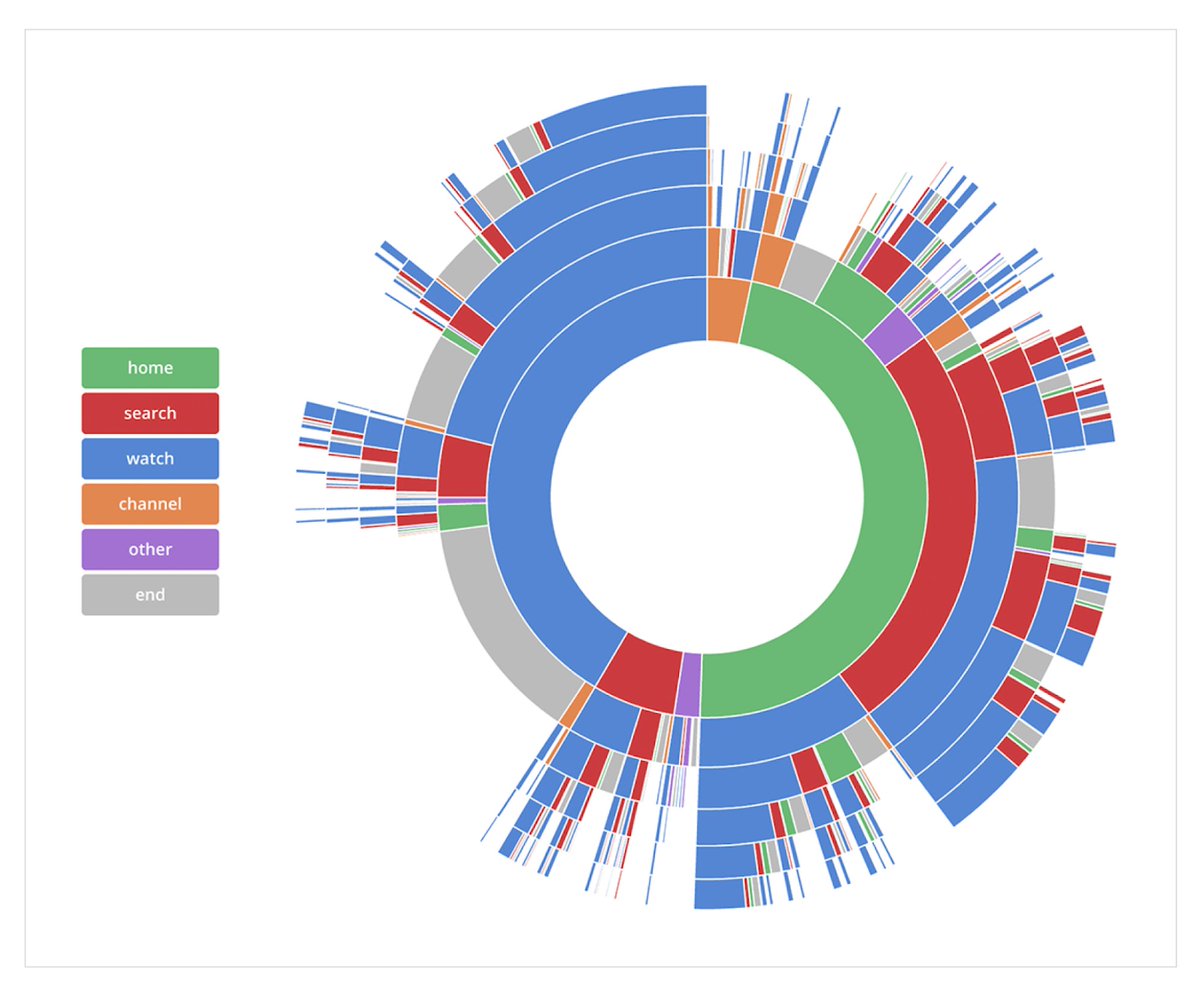
To simplify the data, Kerry categorized all the pages of YouTube into five page types: Home, Search, Watch, Channel, and Other (account, settings, etc.).
Kerry counted usage for each page type and then likelihood of the next page to visit.
e.g. If someone was on the home page, what percentage of the time did they search vs watch a video?
When sharing these eye-opening findings with PMs, Designers, and Engineers, Kerry was met with a barrage of additional questions:
- Where were people most likely to start?
- Where did they go?
- What did a typical session look like?
- How/when/where did sessions end?
These questions led Kerry to analyze whole sessions.
So they calculated where people started, and from each page, where they were most likely to go next.
—
Kerry had overcome the first challenge of making sense of the data.
But their goal was not only to understand how people navigated YouTube, it was also to show the data in a way that everyone inside of YouTube could easily understand.
After exploring several formats, Kerry landed on a radial sunburst format to visualize the data.
In this view, it was easy to see the relative % of sessions that started with each page type and it was also easy to follow a user’s path across an entire session.
Kerry built an interactive version that allowed us to hover and trace any path from start to end, with the percentage of sessions that followed that exact path.
The image below is static, but shows the breakdown of paths people took through YouTube.
(Starting from the inside and working your way to the outermost ring)
—
Kerry’s visualization went viral inside YouTube.
It was turned into posters and hung up on the walls, printed onto t-shirts, and referenced in exec strategy decks and new hire orientation.
The mystery of how people used YouTube had been unlocked.
—
We had all assumed YouTube’s homepage was important.
The homepage had 45M+ visits per day and companies were doing home page buyout ads for huge sums of money.
But Kerry’s research revealed less than half of sessions started on the homepage and people mostly came to the home page to search.
The homepage showed a bunch of videos that were driven by a mass algorithm (and was pretty much the same experience whether a person was logged in or not).
We were missing the opportunity to show 45M people the content they wanted to watch each day.
Kerry’s visualization was an inflection point in YouTube’s history.
Their findings created lasting ripple effects that elevated how well we understood users’ experiences, how we approached building products, and how so many subsequent video-first companies shaped their products.
Ultimately, the team invested in building personalized recommendations, which helped transform the homepage from a search portal into a destination for finding content to watch.
This transition was especially pivotal later, when everyone shifted to mobile.
Personalized recommendations set YouTube up to become the dominant mobile video app, where “homepage” discovery was foundational to its success.
Today, we open the YouTube app and start watching videos without even thinking — it just works.
—
This story has stuck with me for the past 15 years.
It is a great example of what can happen when a single person is devoted to understanding the full user experience and is willing to put in the effort to cross traditionally accepted boundaries.
It is so important to have a clear picture of how people experience your product — both qualitatively and quantitatively.
Understanding this fuller picture can open your eyes to gaps and unexpected behaviors as well as focusing on perfecting the parts of your product where the magic happens.
—
A big thanks to @kerryrodden, as well as @shivar + @mags to jog my memory of different facets of this story.
For more on design insights + stories, follow me at @elizlaraki.