What if anything does computational complexity have to say about how brains work (or vice versa)?
Cris made this discussion NP easy
https://t.co/bILjW27f8g
Engineers have developed a process for training #LLMs that uses 14 percent less energy without sacrificing speed. Their method involves adjusting the clock frequency of the GPU during computation. https://t.co/eDAeIKGeZl
Very cool work from @jit_infinity:
🔥Leve: filesystem-first, durable agent framework built on LangGraph.
You describe an agent as a directory of files. Leve compiles that directory into an agent and runs it
Inspired by Vercel's Eve
https://t.co/cfWpii90Yn
Google ha acabado con la mafia de las GPU 💀
VS Code ahora se conecta directamente a Google Colab.
→ Obtienes una GPU T4 gratuita dentro de tu editor.
→ Tus archivos locales. Su potencia de cómputo.
⬇️ Download the World Distribution of Uranium Deposits map in HD!
This edition features nearly 5300 deposits, a revised classification system & improved geological visual offering a comprehensive view of 🌍 #uranium resources.
Get it here 🗺️ https://t.co/e5MZAmlyVL
it was fun giving a talk at MLSS 2026 in NYC. i talked about my recent efforts in "computatinalizaing" statistical and causal estimation, from learning to estimate pop. std. dev, mutual info., bayes ppd and causal effect to causal identification.
links to the slide deck and the papers below.
Oh and Kim Morrison used Claude + Aristotle + Codex to formalize the negation of the Erdos unit distance conjecture: https://t.co/Y0mPvIm7S1
It's nice to see that this was built on top of PNT+; so despite the fact that we haven't been able to upstream it to Mathlib (the Residue Theorem we have in PNT+ is just for rectangles, and Mathlib will want a much more general version...), it's still useful in other applications!...
A Research Scientist at Google DeepMind just dropped a 58 page paper on building agents that specialize in game theory.
Here are the most important parts:
TIL Jurafsky & Martin, the textbook I used for Computational Linguistics in undergrad many years ago (when TAU didn't offer that class), released a second edition in 2026, and it has one of the clearest explanations of Transformers I have seen to date.
https://t.co/FyCukgQTtb
COMPANY BEHIND TIKTOK JUST OPEN SOURCED AN AI AGENT THAT DOES YOUR WHOLE JOB FOR YOU
China doesn't miss 😳
everyone's been crowning hermes the #1 agent then bytedance dropped deerflow
72,000+ github stars. 9,700+ forks. FREE. MIT
it doesn't just run tools like hermes. it does the entire task
you give it one job and it plans the steps, spins up a team of sub-agents, writes the code, tests it, fixes its own errors, and hands you finished work in its own sandbox
research, full websites, dashboards, slide decks, reports. done, not drafts
full beginner setup:
easiest way (if you use claude code, cursor or codex):
paste this to your agent and it installs everything for you:
"clone deerflow and set it up for local dev using https://t.co/jPhzWtcHwr"
manual way (about 5 min):
1. install the basics: git, docker, node 22+, uv, pnpm (deerflow's "make check" flags anything missing)
2. clone the repo:
git clone https://t.co/VdMJHx0YOu
cd deer-flow
3. run the setup wizard:
make setup
it asks which model you want and saves your key. point it at openrouter, groq or nvidia nim to run it free
4. check it works:
make doctor
5. start it with docker:
make docker-init
make docker-start
6. open it in your browser and give it your first task
now the part that'll start a fight:
hermes is the most used agent on openrouter (224B tokens a day) and i've been all in on it
but hermes runs your tools. deerflow runs your whole project end to end
i'm actually tempted to switch and i did not expect that
so which one wins right now?
- hermes: american, lean, lives on your laptop
- deerflow: chinese, bytedance muscle, replaces a whole team
bookmark this and tell me which agent you're running
Neural Network Implementation of the Renormalization Group for Fault Diagnosis with Class Imbalance
Evgeny Nikulchev, Dmitry Ilin
https://t.co/AHeomEzZ4f [𝚌𝚜.𝙻𝙶]
On the Residual Scaling of Looped Transformers: Stability and Transferability
Shaowen Wang, Bingrui Li, Ge Zhang, Wenhao Huang, Shen Yan, Jian Li
https://t.co/TBHHCYz7FK [𝚌𝚜.𝙻𝙶]
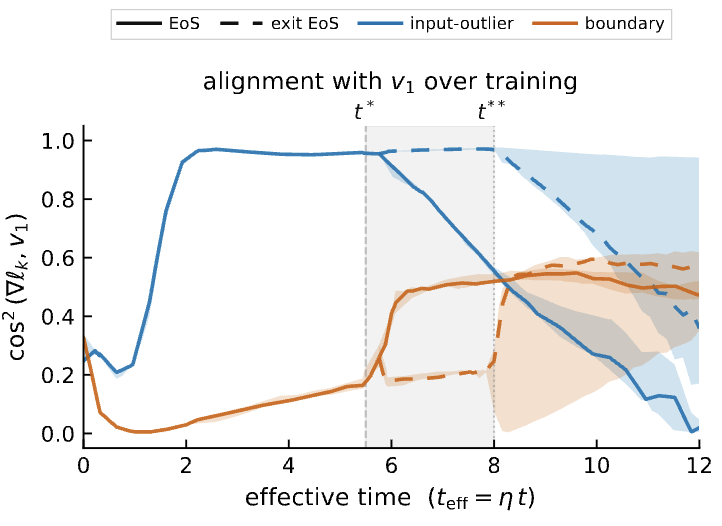
Edge of Stability has been a thing for a while now. We can show that most training happens at the edge of stability. This is very surprising because of a "negative " fact: Most theory does not apply (e.g., Descent Lemma).
The question becomes:
Does the fact that training happens at the EoS impact performance? In what way? With what mechanisms? How is that affected by the architecture?
To our knowledge, these questions they are unanswered to date and our new paper is the about the first step towards this!
EoS picks what part of the distribution to learn and at what speed!
https://t.co/sefeVZMzbz
In particular, the consequence is that for MLPs:
EoS can improve robustness or OOD behavior, but only when the relevant subset is the one selected by EoS.
If boundary points dominate, EoS helps near-boundary robustness.
If distributional outliers dominate, EoS helps extrapolate toward the tail.
Precisely:
1. We make EoS causal. We fork training from the same state at EoS onset:
one branch stays at EoS, the other exits by lowering the learning rate. Same everything, only the stability constraint changes.
2. EoS is selective:
it learns some parts of the data distribution faster, while slowing others.
3. The selector is surprisingly simple. A group benefits from EoS when its gradient is big and
has high alignment with v_1, the top Hessian eigenvector.
Translation: to benefit from EoS, a subset must
(i) point in the sharpest direction, and
(ii) keep a non-vanishing gradient.
This gives concrete answers to the questions above:
Does EoS affect performance?
Yes, but not uniformly. It reallocates learning.
In what way?
It prioritizes the subset with largest curvature influence.
By what mechanism?
Self-stabilization at the sharpness boundary couples training to v_1; only groups aligned with v_1, and whose gradients persist, get the extra progress.
How does architecture matter?
Architecture changes the map from input geometry to gradient geometry. Thus it can change which subset dominates, but the same predictor remains:
largest curvature influence wins.
With the amazing Shauna Kwag, @anakha_g, and @TomasoPoggio!
Photon number as a learning-capacity knob: a polynomial scaling advantage in quantum machine learning
In most variational models, capacity is something you buy through parameters and data. Add more trainable weights, feed more examples, and the model learns to generalize. But what if a physical resource of the hardware itself could do that work for you? In photonic quantum machine learning, that resource turns out to be the number of photons you send through the circuit.
Yong Wang and coauthors prove, and then measure, that the learning capacity of a linear optical circuit scales polynomially with photon number. They quantify capacity using the rank of the data quantum Fisher information matrix, which counts the independent directions in parameter space that actually move the model. For an m-mode circuit, single-photon states give a capacity that grows like m, while multi-photon states push it toward m². More photons means a larger accessible state space, which is the geometric signature of better trainability and generalization.
The practical payoff shows up in two experiments on a fully programmable 6-mode photonic chip, trained online with SPSA. In a unitary-learning task, single photons need at least 4 training states to recover a 5×5 unitary, while two-photon states do it with only 2, cutting the data requirement roughly in half and matching the theory exactly. In a metric-learning task on a vowel-recognition dataset, two-photon states reach markedly higher class separation and lower test loss than single-photon states under the same ansatz and training budget. The lesson is clean: you can trade a hardware resource (photon number) for what would otherwise cost you training data.
For learning pipelines on photonic hardware, this reframes a scaling decision. Instead of only enlarging circuits or gathering more labeled examples, which is the expensive part in domains like molecular property prediction, materials screening, or spectroscopy-driven discovery, you can raise photon number to extract more capacity from the same chip. That matters wherever labeled data is scarce or costly to acquire, since fewer training states to reach generalization translates directly into shorter, cheaper experimental loops.
Paper: Wang et al., npj Quantum Information (2026), CC BY 4.0 | https://t.co/XRq7vi5Cyj