AI builder + runner chasing sub-25 5K. Crrently tinkering at some early ideas - more soon. Prev: 2x healthcare/fitness co-founder, AI/ML research. 🎓 IIT Bombay
i wish i could do more - i wish i had a thousand hands and a thousand eyes and a thousand years and army of angels and a thousand stars that lit the sky so bright that the night would never come and that our sleepless dreams would fill this world
These numbers are shocking. It's like we got a new frontier AI model but for the body.
Lilly's phase 3 results for retatrutide:
> highest dose lost 28.3% of body weight in 80 wks
> 70 lbs ave
> 45% lost 30% or more of their body weight
> 65% on the top dose no longer clinically obese
Retatrutide is more dynamic than semaglutide and tirzepatide because it targets three receptors (GIP, GLP-1, and glucagon), versus one and two, respectively.
Side effects, on the highest dose (12mg), were higher for retatrutide than tirzepatide (nausea and GI), with an 11.3% drop out rate. The lowest 4mg dose still delivered 19% loss with fewer dropouts than placebo.
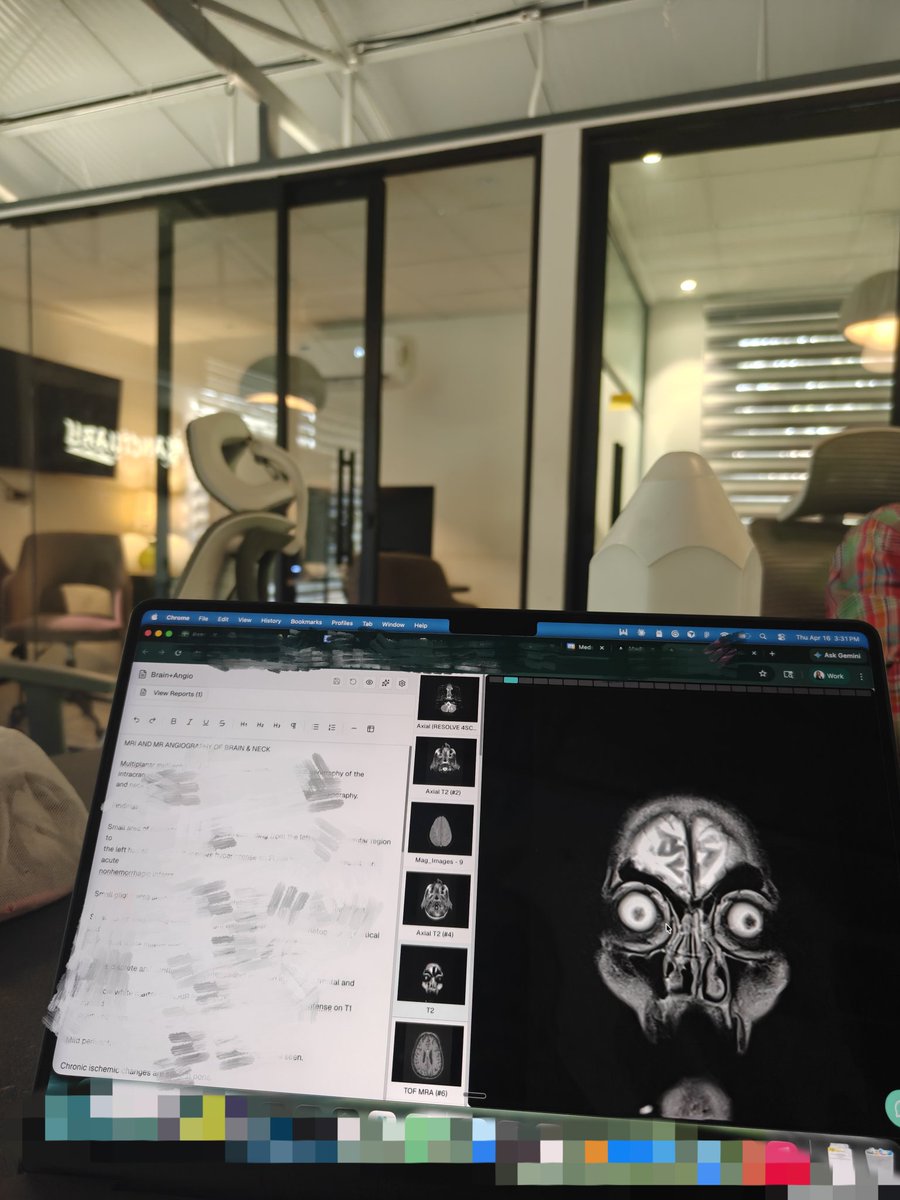
we ran a small investigation: can claude opus read a spine mri and find a spinal lesion?
short answer - yes. with chain-of-thought, textbook descriptions - the model found a lesion (and reasoned through where and why) that a generic prompt missed entirely.
(the cv nerd🤓 in me also wrote up how vision ai got here - from sobel edge detectors to cat🐱 detectors to reasoning models.)
https://t.co/idUVek2GF1
🧵
@jukan05 don't think it is that complex - heterogenous older GPU clusters are good only for inference, and xAI doesn't really have the demand yet as their models haven't reached parity. Once the new models are trained they will take back Colossus 1 for inference
I spent a bunch of time a year ago thinking about the data wall. A blackpill at the time for me was when I realized that the total stock of natural text data is depleting much faster than Chinchilla's infamous 20 tokens per param compute optimal ratio suggested. Here is a naive BOTEC from back then:
Famously, Chinchilla showed that using about 20 tokens per param was compute optimal, measured at 6*10^23 FLOPs. It turns out that even though MoEs are more compute efficient than dense models, training them compute optimally needs a lot more data! In fact, at a 1:32 (97%) sparsity it uses ~6x more tokens per active params (see [1]). The Llama 3 405B report measured 40 token per param to be optimal with their data at 4*10^25 FLOPs. And for a 1:32 sparse MoE model such as DeepSeek v3, this suggests 240 tokens per param could well end up being optimal!
At this ratio, things would break down. A 4*10^27 FLOPs model (a pretraining run that might be planned e.g. for 2026) will need 400T tokens. A 5*10^28 FLOPs model would require O(1400T) tokens. These are insane numbers, and they only get worse into the 2030s! The totally unfiltered Common Crawl is about 240T tokens. People have been offsetting this to some extent by training for multiple epochs or repeating the same data a la "Scaling Data-Constrained Language Models" by Muennighoff et al. (2023). Of course, this is a naive BOTEC, and I'm happy to dive into more details, e.g. how much compute might be put into other uses, such as long-horizon RLVR which could well require a lot of those 5*10^28 FLOPs.
But we are casually talking about hundreds of trillions to over a quadrillion tokens as compute-optimal! It makes one question whether these numbers are actually necessary for the kind of capability gains we want. We are working on this question at @flappyairplanes, and we're excited to be advised by @karpathy. I will end here with this @ilyasut quote from the @dwarkesh_sp episode with him:
"The data is very clearly finite. What do you do next? Either you do some kind of souped-up pre-training, a different recipe from the one you’ve done before, or you’re doing RL, or maybe something else. But now that compute is big, compute is now very big, in some sense we are back to the age of research. [...]
Up until 2020, from 2012 to 2020, it was the age of research. Now, from 2020 to 2025, it was the age of scaling—maybe plus or minus, let’s add error bars to those years—because people say, “This is amazing. You’ve got to scale more. Keep scaling.” The one word: scaling.
But now the scale is so big. Is the belief really, “Oh, it’s so big, but if you had 100x more, everything would be so different?” It would be different, for sure. But is the belief that if you just 100x the scale, everything would be transformed? I don’t think that’s true. So it’s back to the age of research again, just with big computers."
[1] arxiv: 2501.12370
There are some really niche VC funds out there...
Thinking about how when I started raising a fintech fund in 2016 I got no's from LP's who thought fintech was too small a category...
What are some other niche VC funds?


















![kushal1t's tweet photo. I spent a bunch of time a year ago thinking about the data wall. A blackpill at the time for me was when I realized that the total stock of natural text data is depleting much faster than Chinchilla's infamous 20 tokens per param compute optimal ratio suggested. Here is a naive BOTEC from back then:
Famously, Chinchilla showed that using about 20 tokens per param was compute optimal, measured at 6*10^23 FLOPs. It turns out that even though MoEs are more compute efficient than dense models, training them compute optimally needs a lot more data! In fact, at a 1:32 (97%) sparsity it uses ~6x more tokens per active params (see [1]). The Llama 3 405B report measured 40 token per param to be optimal with their data at 4*10^25 FLOPs. And for a 1:32 sparse MoE model such as DeepSeek v3, this suggests 240 tokens per param could well end up being optimal!
At this ratio, things would break down. A 4*10^27 FLOPs model (a pretraining run that might be planned e.g. for 2026) will need 400T tokens. A 5*10^28 FLOPs model would require O(1400T) tokens. These are insane numbers, and they only get worse into the 2030s! The totally unfiltered Common Crawl is about 240T tokens. People have been offsetting this to some extent by training for multiple epochs or repeating the same data a la "Scaling Data-Constrained Language Models" by Muennighoff et al. (2023). Of course, this is a naive BOTEC, and I'm happy to dive into more details, e.g. how much compute might be put into other uses, such as long-horizon RLVR which could well require a lot of those 5*10^28 FLOPs.
But we are casually talking about hundreds of trillions to over a quadrillion tokens as compute-optimal! It makes one question whether these numbers are actually necessary for the kind of capability gains we want. We are working on this question at @flappyairplanes, and we're excited to be advised by @karpathy. I will end here with this @ilyasut quote from the @dwarkesh_sp episode with him:
"The data is very clearly finite. What do you do next? Either you do some kind of souped-up pre-training, a different recipe from the one you’ve done before, or you’re doing RL, or maybe something else. But now that compute is big, compute is now very big, in some sense we are back to the age of research. [...]
Up until 2020, from 2012 to 2020, it was the age of research. Now, from 2020 to 2025, it was the age of scaling—maybe plus or minus, let’s add error bars to those years—because people say, “This is amazing. You’ve got to scale more. Keep scaling.” The one word: scaling.
But now the scale is so big. Is the belief really, “Oh, it’s so big, but if you had 100x more, everything would be so different?” It would be different, for sure. But is the belief that if you just 100x the scale, everything would be transformed? I don’t think that’s true. So it’s back to the age of research again, just with big computers."
[1] arxiv: 2501.12370](https://pbs.twimg.com/media/G_xw2UkbsAAVz1d.jpg)































