Nikhyl's new Skip episode on PM reinvention is excellent.
His framing: the shift from capital-M Manager to builder is hardest for senior PMs, because what got us here no longer differentiates.
My honest reaction: I'm more excited about being in product than I've been in years. We get to build again.
https://t.co/CIexdTEYwN
Imagine every pixel on your screen, streamed live directly from a model. No HTML, no layout engine, no code. Just exactly what you want to see.
@eddiejiao_obj, @drewocarr and I built a prototype to see how this could actually work, and set out to make it real. We're calling it Flipbook. (1/5)
Been waiting for this one. Clear open-source coding SOTA. Would love K2.6 on @cerebras at 1000+ tps and this would be a game-changer. Congrats to our friends @ Moonshot team.
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on https://t.co/YutVbwktG0 in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: https://t.co/uvoSJKyGCY
-
🔗 API: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/9wWvgIQSS3
🔗 Weights & code: https://t.co/Be0hjs2RTP
@swyx@aiDotEngineer So cool you are organizing sg edition. If you have time come by our office for a coffee. Also: Plenty of grab folks going. Would love to join the sg tour :)
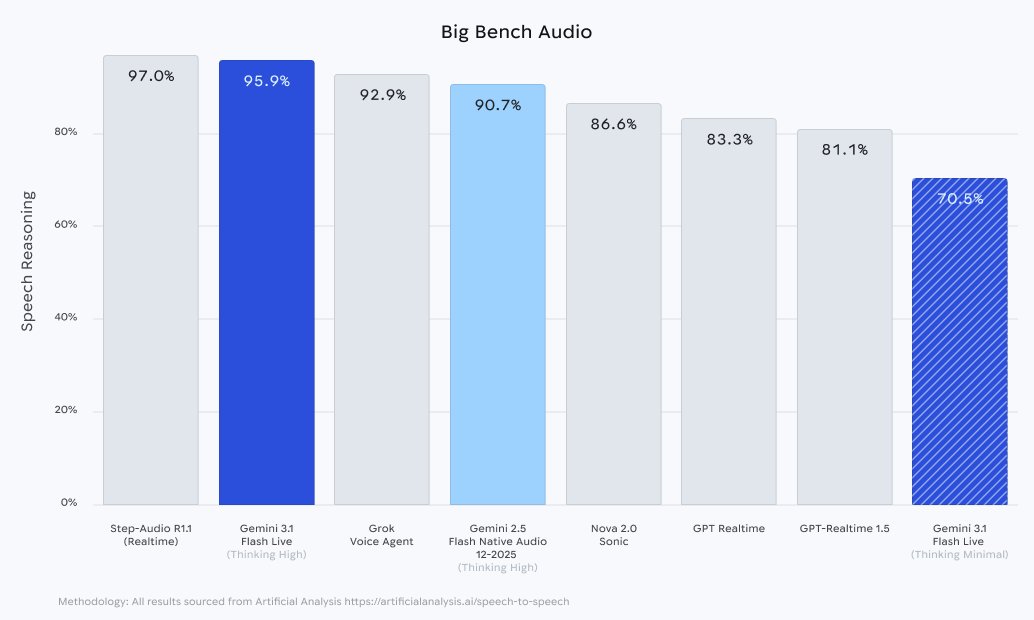
What stands out to me is the jump in intelligence, accuracy, and function calling - and that they enable search grounding. This is the kind of progress that could make voice agents genuinely useful, not just impressive in demos.
Introducing Gemini 3.1 Flash Live, our new realtime model to build voice and vision agents!!
We have spent more than a year improving the model + infra + experience, the results? A step function improvement in quality, reliability, and latency.
Google just dropped Gemini 3.1 Flash Live and it looks like a real step forward for real-time audio models. This is super cool as I got a chance to play a bit with it.
World Models are the next evolution after LLMs, and the most exciting thing happening in maps right now.
The Seoul World Model from Naver/KAIST: a real, promptable Seoul built from 1.2M street-view images. Navigate freely for kilometers.
Reshape scenes with text. No hallucinated cities, this is grounded in reality.
Incredible work https://t.co/SpmTHqo2kp
Beep, boop. Come in, rebels. We’ve raised a 60m seed round to build the next developer platform. Open. Scalable. Independent. And we ship our first OSS release today.
https://t.co/OvPKCcjXbq
What happens when AI agents can transact, coordinate compute, and operate onchain at scale?
Across Asia, this infrastructure is already live. Agent-native payments, decentralized GPU networks, and onchain identity systems are moving into production at blazing speeds.
Today we’re releasing The 2026 AI × Blockchain Convergence Report, built with @Superscrypt, @base, and @awscloud, with contributions from @GrabSG , @AethirCloud, @virtuals_io, @MessariCrypto, @chatandbuild, @Sogni_Protocol, @KaitoAI and others.
LFG!
@AlirezaGhods2@solana Thanks so much for organizing / hosting - so great to see all the innovation you are driving . Really happy for us partnering together!
We’re excited to announce the release and open-source of HunyuanImage 3.0 — the largest and most powerful open-source text-to-image model to date, with over 80 billion total parameters, of which 13 billion are activated per token during inference.The effect is completely comparable to the industry’s flagship closed-source model.🚀🚀🚀
HunyuanImage 3.0 originates from our internally developed native multimodal large language model, with fine-tuning and post-training focused on text-to-image generation. This unique foundation gives the model a powerful set of capabilities:
✅Reason with world knowledge
✅Understand complex, thousand-word prompts
✅Generate precise text within images
Different from traditional DiT architecture image generation models, HunyuanImage 3.0’s MoE architecture uses a Transfusion-based approach to deeply couple Diffusion and LLM training for a single, powerful system. Built on Hunyuan-A13B, HunyuanImage 3.0 was trained on a massive dataset: 5 billion image-text pairs, video frames, interleaved image-text data, and 6 trillion tokens of text corpora. This hybrid training across multimodal generation, understanding, and LLM capabilities allows the model to seamlessly integrate multiple tasks.
Whether you're an illustrator, designer, or creator, this is built to slash your workflow from hours to minutes. HunyuanImage 3.0 can generate intricate text, detailed comics, expressive emojis, and lively, engaging illustrations for educational content.
The current release focuses solely on text-to-image generation and future updates will include image-to-image, image editing, multi-turn interaction, and more.
👉🏻Try it now: https://t.co/hHhQpNxJ4e
🔗GitHub: https://t.co/B2bkhlbXxk
🤗Hugging Face: https://t.co/s0G2Lix3ZD
Meituan just dropped a new LLM with “Dynamic Activation.”
Think of it as a brain that decides when to think harder: it activates more experts for tricky parts of a question, fewer for easy ones.
Closer and closer to how our own brains allocate effort. 🧠⚡
Qwen is really on a roll lately. Image generation model looks amazing with text generation and ultra high accuracy rendering. Thanks for releasing it under an open license!
🚀 Meet Qwen-Image — a 20B MMDiT model for next-gen text-to-image generation. Especially strong at creating stunning graphic posters with native text. Now open-source.
🔍 Key Highlights:
🔹 SOTA text rendering — rivals GPT-4o in English, best-in-class for Chinese
🔹 In-pixel text generation — no overlays, fully integrated
🔹 Bilingual support, diverse fonts, complex layouts
🎨 Also excels at general image generation — from photorealistic to anime, impressionist to minimalist. A true creative powerhouse.
Blog:https://t.co/FZ415nwcAp
Hugging Face:https://t.co/XSLwjJ6lYa
ModelScope:https://t.co/mcZ0dHeD64
Github:https://t.co/A9yvJZ6TJc
Technical report:https://t.co/tld83OrOUP
Demo: https://t.co/MgEAr4uqoR