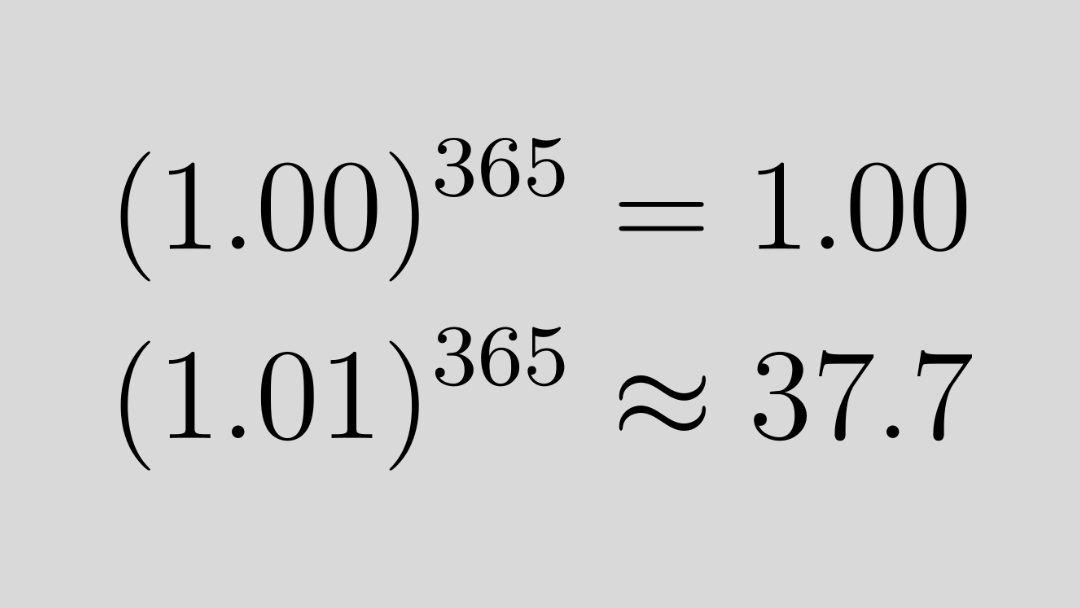The events of the last 6 months in technology are arguable amongst the most important in human history
The tools now increasingly exist for recursive self improvement of models & agents
We are likely in very early lift off & exponential
Largely unnoticed outside of tech
2016
Student: What programming language should I learn?
Teacher: Python is a great place to start.
2026
Student: What programming language should I learn?
Teacher: Markdown is all you need.
@DynamicWebPaige Codex doesn’t really look like a traditional IDE. Its UI is much more prompt-centric. But tbh, it’s already replacing VS Code for me in most of my workflows.
With tools like @OpenAI Codex, we’re becoming truly idea-bound (and compute-bound 😀)
So many ideas I never had the time, energy, or foundation to explore. Now @ChatGPTapp helps me think through them, and Codex helps me build. Exciting times 🚀
@ChatGPTapp is the PhD advisor I never had: patient, thoughtful, and always ready to gently guide me in the right direction while actually listening to my ideas
We're excited to announce the launch of Phi-3, a groundbreaking family of small language models that outperform larger models on a range of benchmarks. Learn how these small language models trained on high-quality data are doing more with less: https://t.co/dFfyktuEUL
Phi-3 Technical Report
Microsoft presents a new 3.8B parameter language model called phi-3-mini.
It's trained on 3.3 trillion tokens and is reported to rival Mixtral 8x7B and GPT-3.5. Has a default context length of 4K but also includes a version that is extended to 128K (phi-mini-128K).
Combines heavily filtered web data and synthetic data to train the 3.8B models.
It also reports results on 7B and 14B models trained on 4.8T tokens (phi-3-small and phi-3-medium).
phi-3-mini achieves 69% on MMLU while phi-3-small and phi-3-medium achieve 75% and 78% on MMLU.
The authors claim that because of the limited size of this model, it has less capacity to store "factual knowledge" making it weaker for certain tasks. This is something that can be resolved using an external search engine.
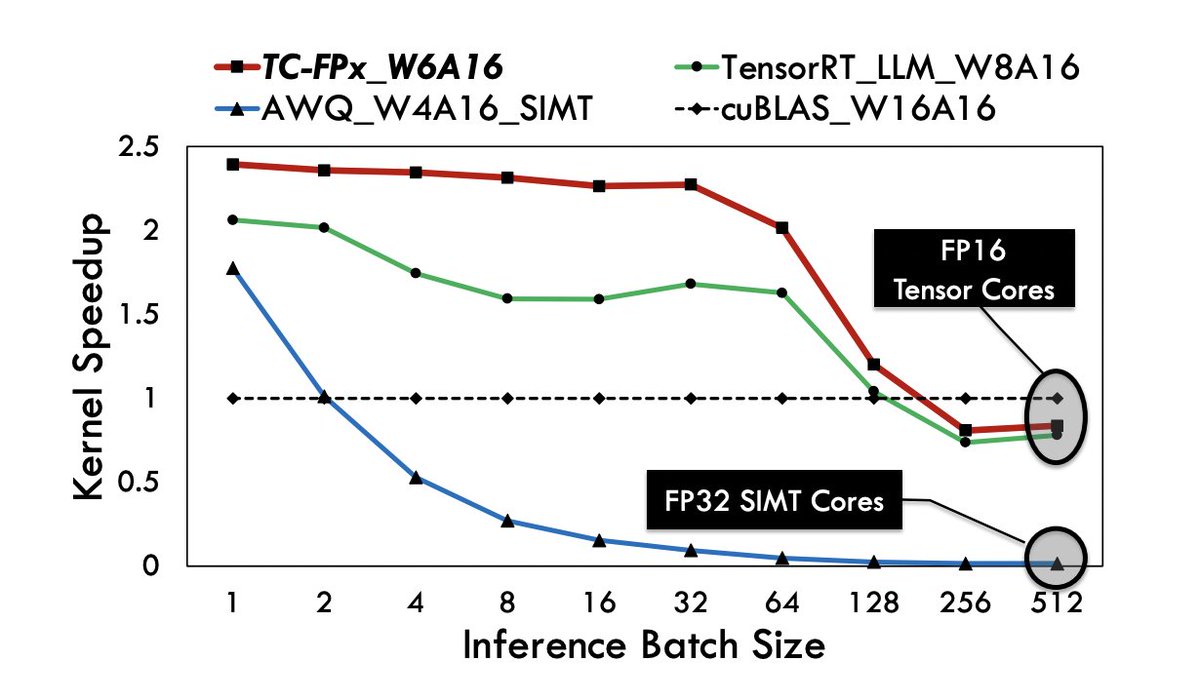
#DeepSpeed joins forces with @Sydney_Uni to unveil an exciting tech #FP6. Just supply your FP16 models, and we deliver:
🚀 1.5x performance boost for #LLMs serving on #GPUs
🚀 Innovative (4+2)-bit system design
🚀 Quality-preserving quantization
link: https://t.co/m6vcmXaWxb
Microsoft presents FP6-LLM
Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design
paper page: https://t.co/nVfNqjBmCV
Six-bit quantization (FP6) can effectively reduce the size of large language models (LLMs) and preserve the model quality consistently across varied applications. However, existing systems do not provide Tensor Core support for FP6 quantization and struggle to achieve practical performance improvements during LLM inference. It is challenging to support FP6 quantization on GPUs due to (1) unfriendly memory access of model weights with irregular bit-width and (2) high runtime overhead of weight de-quantization. To address these problems, we propose TC-FPx, the first full-stack GPU kernel design scheme with unified Tensor Core support of float-point weights for various quantization bit-width. We integrate TC-FPx kernel into an existing inference system, providing new end-to-end support (called FP6-LLM) for quantized LLM inference, where better trade-offs between inference cost and model quality are achieved. Experiments show that FP6-LLM enables the inference of LLaMA-70b using only a single GPU, achieving 1.69x-2.65x higher normalized inference throughput than the FP16 baseline.