If you're a technical person longing to understand the conceptual foundations of modern AI (manifold learning), this talk is for you! (I'll be giving it 😁)
Title: The Magical World of Autoencoders
https://t.co/SkTNtupiZ7
1/ We have been training RNNs wrong for decades.
Backpropagation through time (BPTT) forces sequential updates, creating unstable O(T) gradient paths.
What if we could train highly expressive, non-linear RNNs with flat, parallelized O(1) gradients?
It is now possible. 🧵
I'm fairly convinced there's some universal language manifold (= a surface formed by meaning vectors) that both humans and LLMs operate on. But we don't train LLMs to explicitly represent this manifold. We rather train them to approximate it, and to move along it by building curves on it.
And those curves are reasoning in geometric terms, like a reasoning trace is a curve on a low-dimensional manifold embedded in a very high-dimensional space.
The Linear Representation Hypothesis (https://t.co/2p3HZEGhX0) touches this, but I wonder if there's more recent work that takes the manifold idea further?
Would love to see takes from people with serious differential geometry backgrounds on this!
I found out the other day that any compression tool can be contorted to do language modeling. Turns out gzip can generate text that somewhat *resembles* Shakespeare. Short write up linked below
1/
What if you could train a model on totally benign-looking Wikipedia articles, but secretly force its internal weights to encode a fully functional QR code?
This is now possible. We can program neural network weights using natural words.
🧵
Did Anthropic get more gains out of model scaling than other labs thought was possible? It reminds me of an interesting recent paper, which showed that deep layers in open LLMs are not doing much, and that this can be fixed by scaling the LayerNorm output.
https://t.co/1Ddzqteu9z
David Sacks on How Anthropic is Ironically Running Surveillance on Their Latest Models
“This is the company that said that it was against government surveillance. They are now retaining for 30 days every prompt and every output you send to one of these Mythos class models.”
My talk at MIT, on "Agentic AI systems: from scruffy to neat", is now available. I cover 3 examples of agentic systems - Bayesian linguistic forecaster, autoharness, and code world models - which combine LLMs, code and planners in different ways. Links below.
I’ve had a number of conversations with folks inside and outside government about the current situation with Anthropic, and here is what I believe to be true:
— As we know, Anthropic publicly released its Mythos class models earlier this week under the commercial name Fable.
— Fable is Mythos with guardrails. But if those guardrails fail, then you’ve exposed Mythos and its advanced cyber capabilities to people who shouldn’t have them. (Keep in mind that Anthropic itself widely promoted the idea that Mythos was a cyberweapon and needed to be regulated as such. They asked for government regulation of Mythos and championed the guardrails on Fable. If there is a vulnerability — big or small — it is Anthropic’s responsibility to patch.)
— A highly credible trusted partner of both Anthropic and the USG who was testing Fable came forward with a jailbreak of those guardrails. The Admin asked Dario to fix the jailbreak or de-deploy the model. Dario refused.
— In their blog post, Anthropic defended its decision by saying the jailbreak isn’t serious. That is not what the trusted partner and the USG believe; nor is that kind of minimizing language consistent with Anthropic’s brand as the AI safety company. It’s difficult to fathom how they could claim a jailbreak allowing operability of a cyber weapon could be defined as not “serious.”
— In the past, Anthropic has always said that safety must be top priority and taken super seriously. In this case, Anthropic prioritized the continued offering of the consumer model over safety.
— In reaction, the Admin issued the export control. The Admin did this reluctantly. It’s been very surprised that Anthropic hasn’t wanted to cooperate with a reasonable safety request (ie fixing the jailbreak issue). Anthropic’s reaction is very much at odds with their branding and ethos as a safe AI research community.
— The Admin’s hope now is that Anthropic remediates the safety issue, the export control is lifted, and Fable goes back into general release. The Admin wants all of this to happen as soon as possible. It is frankly bewildered that Anthropic hasn’t wanted to comply with safety requests that it previously said were its highest priority.
— Those trying to misdirect and tie this action to the prior DoW/Anthropic issues are wrong. The Admin values Anthropic’s technical capabilities and feels that this issue, while serious, should be easily resolved. The ball is in Anthropic’s court.
1/
Why does the Muon optimizer train LLMs 2x faster than Adam?
It isn't because Muon finds "better" directions of steep descent.
It's because Adam constantly runs head-first into massive second-order curvature penalties, paying a steep "curvature tax."
Let's dive in. 🧵
sometimes , it really does take a decade for me to understand a paper and appreciate its insight and foresight. <Discovering Causal Signals in Images> is one such paper. wow ... david, @robertnishihara , @soumithchintala , @bschoelkopf & @LeonBottou really did see the future.
Claude Code fully dissected!
Researchers from UCL reverse-engineered the leaked Claude source. What they found changes how you should think about agent design.
Only 1.6% of the codebase is AI decision logic.
The other 98.4% is operational infrastructure. Permission gates, tool routing, context compaction, recovery logic, session persistence. The model reasons. The harness does everything else.
This is the opposite of what most agent frameworks do today.
LangGraph routes model outputs through explicit state machines. Devin bolts heavy planners onto operational scaffolding. Claude Code gives the model maximum decision latitude inside a rich deterministic harness, and invests all its engineering effort in that harness.
The core loop is a simple while-true. Call model, run tools, repeat.
But the systems around that loop are where the real design lives:
A permission system with 7 modes and an ML classifier. Users approve 93% of prompts anyway, so the architecture compensates with automated layers instead of adding more warnings.
A 5-layer context compaction pipeline. Each layer runs only when cheaper ones fail. Budget reduction, snip, microcompact, context collapse, auto-compact.
Four extension mechanisms ordered by context cost. Hooks (zero), skills (low), plugins (medium), MCP (high). Each answers a different integration problem.
Subagents return only summary text to the parent. Their full transcripts live in sidechain files. Agent teams still cost roughly 7x the tokens of a standard session.
Resume does not restore session-scoped permissions. Trust is re-established every session. That friction is the point.
The bet behind all of this is simple. As frontier models converge on raw coding ability, the quality of the harness becomes the differentiator, not the model.
Paper: Dive into Claude Code (arXiv:2604.14228)
We've shared an article on Agent Harness and what every big company is building.
Read it below.
Singapore had its shot at a AI model. In early 2023 a local company had 5,000 GPUs, highest in Asia ex China and a top tier team assembled in Singapore.
And the rarest thing of all: timing. This was right before the large-model explosion.
Then that company stock crashed 90%.
SEA’s Forrest Li pivoted hard to profitability for Shopee, the moonshot got cut, and the team thinned out. Some of the best researchers now sits at Tencent Hunyuan.
Singapore's biggest tech company had the compute, the talent, and the moonshot moment. Draw parallels with Chartered Semiconductor story.
As believers of open research, we are disappointed to see Anthropic silently degrading Fable 5 for AI development
"Any topic related to building pretraining pipelines, distributed training infrastructure, or ML accelerator design... may have limited effectiveness through Claude via methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning."
Not only do they get to decide what you use LLMs for in research, but this also enables them to silently intervene in your research without you knowing.
This sets a dangerous precedent. If a model refuses openly, users can understand the boundary. If a model falls back to another model, users can still evaluate the difference. But if a model silently modifies or weakens its own answers while still pretending to help, researchers lose the ability to know whether a failed result came from their own idea, their implementation, or an invisible intervention by the model provider.
That is not safety. Safety policies should be transparent, auditable, and user-visible.
On top of that, the people most harmed by this are not the largest labs with massive teams and proprietary infrastructure. It is the independent researchers, academic groups, startups, and open-source builders who rely on public tools to compete, innovate, and pioneer AI for everyone else.
Gradient descent on neural networks frequently drives the sharpest Hessian eigenvalue to exactly 2/learning_rate. This is the Edge of Stability. For five years, ML theory has failed to explain why this happens globally from any initialization. Until now. 🧵
A light show honoring Antoni Gaudí has just lit up Sagrada Família.
It felt like the tallest church in the world, for a moment, let its impossible beauty be seen by its creator.
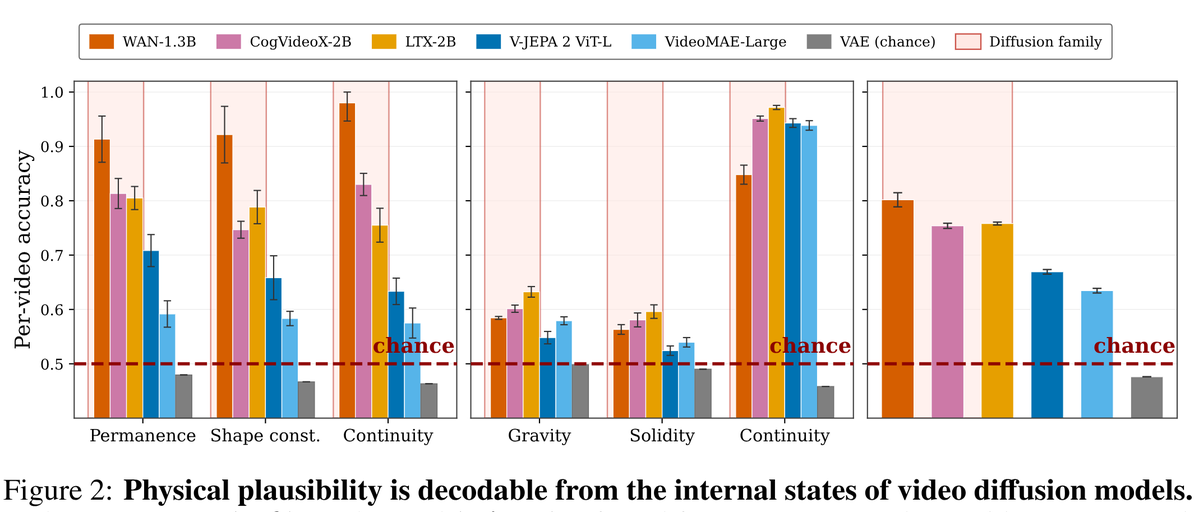
You may have recently heard claims that video generation models are "dumb" about physics, and only "world models" (V-JEPA, specifically) have a valid internal model of physics.
This turns out to be false. In a recent paper, researchers show that a LINEAR probe of diffusion videogen models predict various "physics" very well, significantly better than V-JEPA or VideoMAE (and plain VAE just sucks).
This is noteworthy, because a *linear* probe being this accurate shows that the model has a pretty explicit internal representation of the physics!