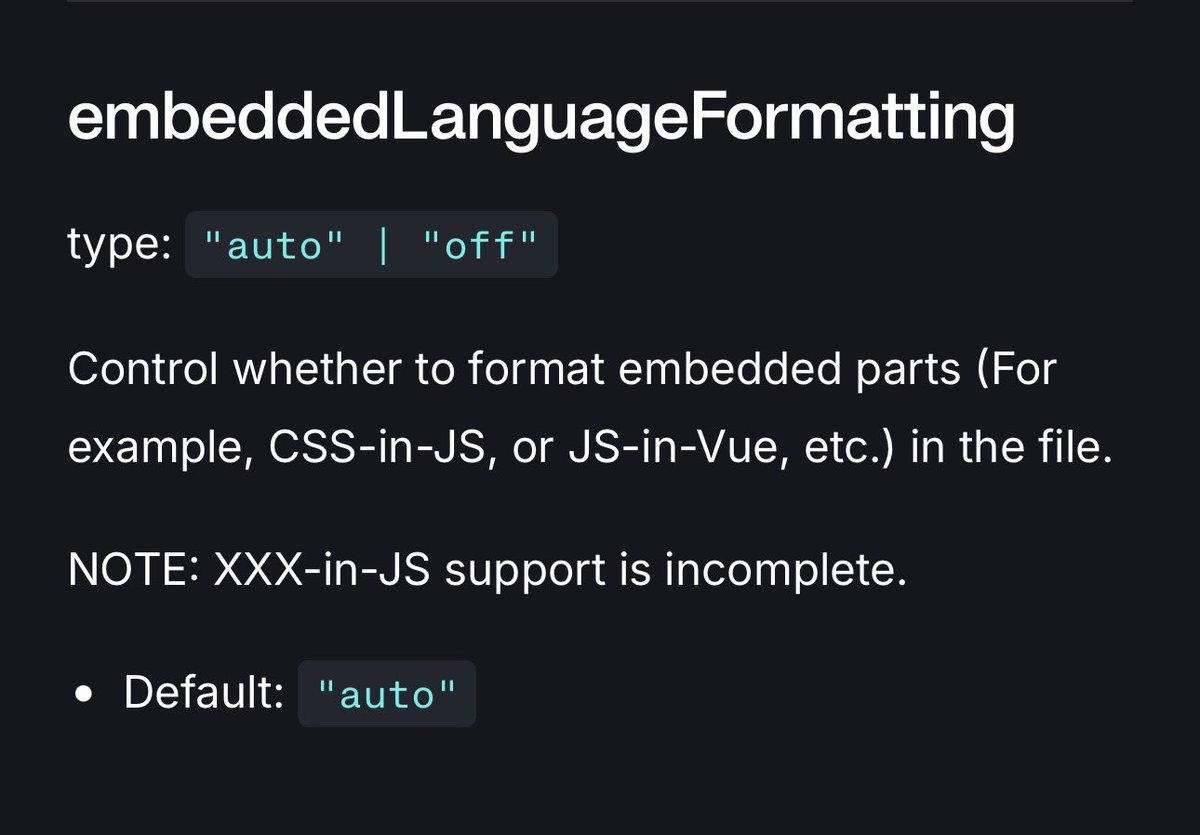
@soniox_ai
quick product question from a language-learning app using your TTS:
For dialogue exercises (Speaker A / Speaker B, different voices), we currently: • call /tts once per line • concatenate WAVs + add inter-line pauses • derive startTimeMs / endTimeMs manually
Is multi-speaker dialogue generation (or segment-level timestamps) on the Soniox roadmap? Would love to simplify our pipeline if so.
Should I have taken the time to properly learn WAV/audio processing here, or is this a “ship it and move on” moment?
I’m using @soniox_ai TTS for Romanian dialogue audio. It gives me 1 WAV per line, but my app needs 1 combined track + per-line timestamps for syncing text in the player/editor.
So I ended up with code that parses WAV headers, extracts PCM, stitches clips together, inserts pauses, and calculates timings.
I’ll be honest: I don’t fully understand all of it, but i get the gist of it.
L engineering move to not go deeper, or reasonable abstraction to move the project forward?
@hugorcd@aisdk Something preventing me from diving into nuxt these days is a project builder compare to @tan_stack / @amanvarshney01 's better-t-stack. Templates give parts of what you want but mostly what you dont want. Maybe something like this exist that I'm unaware of?
@tannerlinsley any goals right now to implement backend frameworks into the builder that work well with tanstack start? @elysiaJS@honojs come to mind. Just curious your thoughts on this?