ESMFold2 is blazing fast and has state of the art accuracy across benchmarks for structure prediction, especially for the challenging problem of predicting protein interactions, including the interaction of antibodies with their targets.
Scaling laws are powering AI. It’s time to scale biology.
Today we’re launching the Virtual Biology Initiative to generate the data to unlock scaling laws in biology and build accurate predictive models of the cell.
Digital representations of proteins are already expanding our understanding of life at the molecular level, and accelerating the design of molecules and medicines. Accurate digital representations of the cell could reveal the mechanisms that are responsible for disease, and show how to reverse them.
The protein data bank, and worldwide repositories of protein sequence biodiversity were created through decades of work by the scientific community. The advances in artificial intelligence for proteins would not have been possible without them.
The cell is orders of magnitude more complex, and we will need to create the data in just a few years rather than decades.
This will require a coordinated global effort. We're partnering with Broad, Wellcome Sanger, Arc, Allen, Human Cell Atlas, Human Protein Atlas, NVIDIA, and Renaissance Philanthropy.
Biohub is contributing to this effort as both a funder and a builder. We are developing microscopy to observe millions of cells in living organisms, and cryo-ET to resolve the cell in atomic detail. We're building instruments that expand the range of modalities and parameters that can be simultaneously measured. We’re developing molecular, cellular, and tissue engineering to create models of disease and design interventions.
The data we generate will be available to the worldwide scientific community.
We’re also committing $100M over the next five years to support work beyond Biohub.
We invite other scientific teams and funders to join.
Link: https://t.co/93Nw1QT5iZ
Excited to announce our latest work! We present ARSENAL, a short-context DNA language model specifically designed to learn important sequence features in noncoding regulatory DNA.
Why is such a model important? Read on to find out!
https://t.co/3FyTSxxe5K
@amanpatel100 is a fantastic CS grad student graduating ~March 2026, interested in AIxBio industry positions. Has deep expertise in DNA/bio language models, sequence-to-function models, popgen/evolution. Please touch base with him (link in next message) if u have positions 1/
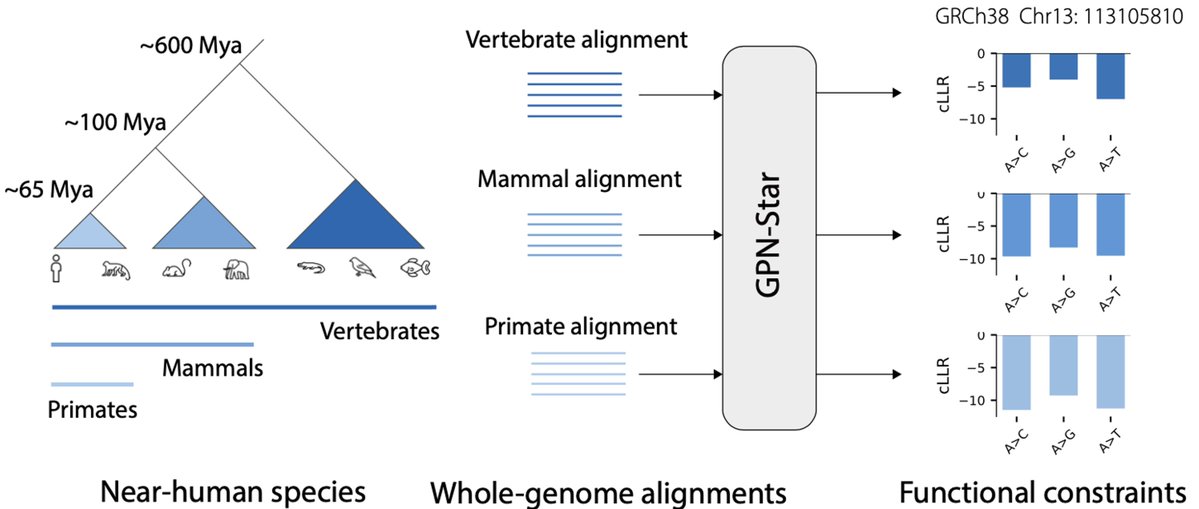
We are excited to share GPN-Star, a cost-effective, biologically grounded genomic language modeling framework that achieves state-of-the-art performance across a wide range of variant effect prediction tasks relevant to human genetics.
https://t.co/FTm3byYp67
(1/n)
Thanks to @riyavsinha in my lab, @igvteam browser will natively support dynseq (dynamic sequence tracks) in an upcoming release. These tracks are very useful to directly visualize base-resolution scores (e.g. contribution scores from ML models, conservation etc). 1/
Our work on "Evaluating the representational power of pre-trained DNA language models for regulatory genomics" led by @AmberZqt with help from @NiraliSomia & @stevenyuyy is finally published in Genome Biology! Check it out!
https://t.co/AFBC9Qu4x3
This a really exciting leap forward for genomic sequence to activity gene regulation models. It is a genuine improvement over pretty much all SOTA models spanning a wide range of regulatory, transcriptional and post-transcriptional processes. 1/
Today was a big day for the lab. We had two back to back thesis defenses and the defenders defended with great science and character.
Congrats to DR. @kellycochra & DR. @soumyakundu_ on this momentous achievement.
Brilliant scientists with brilliant futures ahead. 🎉🎉🎉
Delighted to share our latest work deciphering the landscape of chromatin accessibility and modeling the DNA sequence syntax rules underlying gene regulation during human development! https://t.co/zIUjPy6ZLz. Read on for more 🧵 [1/16]
(1/10) Excited to announce our latest work! @arpi_ta_s, @AustinWang14, and I will be presenting DART-Eval, a rigorous suite of evals for DNA Language Models on transcriptional regulatory DNA at #NeurIPS2024. Check it out! https://t.co/YDe4RMCrhQ