🧬🔮 Single cell foundation models have been a recent hot topic in bio-ML! A few of the recent methods and some thoughts 🧬🔮
1) Geneformer
2) scGPT
3) scFoundation
4) Exceiver
Alex on why AI drug discovery companies need to generate novel data to succeed:
"AI models based on the research that's available is a lot of garbage in and garbage out."
"A lot of the recorded literature is actually incorrect. There's been tons of studies that show if you go try to replicate the experiments that are in the literature, you don't even get the same results."
"The AI companies that I believe are gonna be most set up for success are the companies with a novel way to generate science tokens that don't exist in the public domain."
There's a broader pattern here we're also finding success with @transcriptabio: provide structured data as context to elicit prior bio knowledge from an LLM.
Here, there are steps of info restructure / distill via probes but worth asking - which are useful? Are they req? 🧐
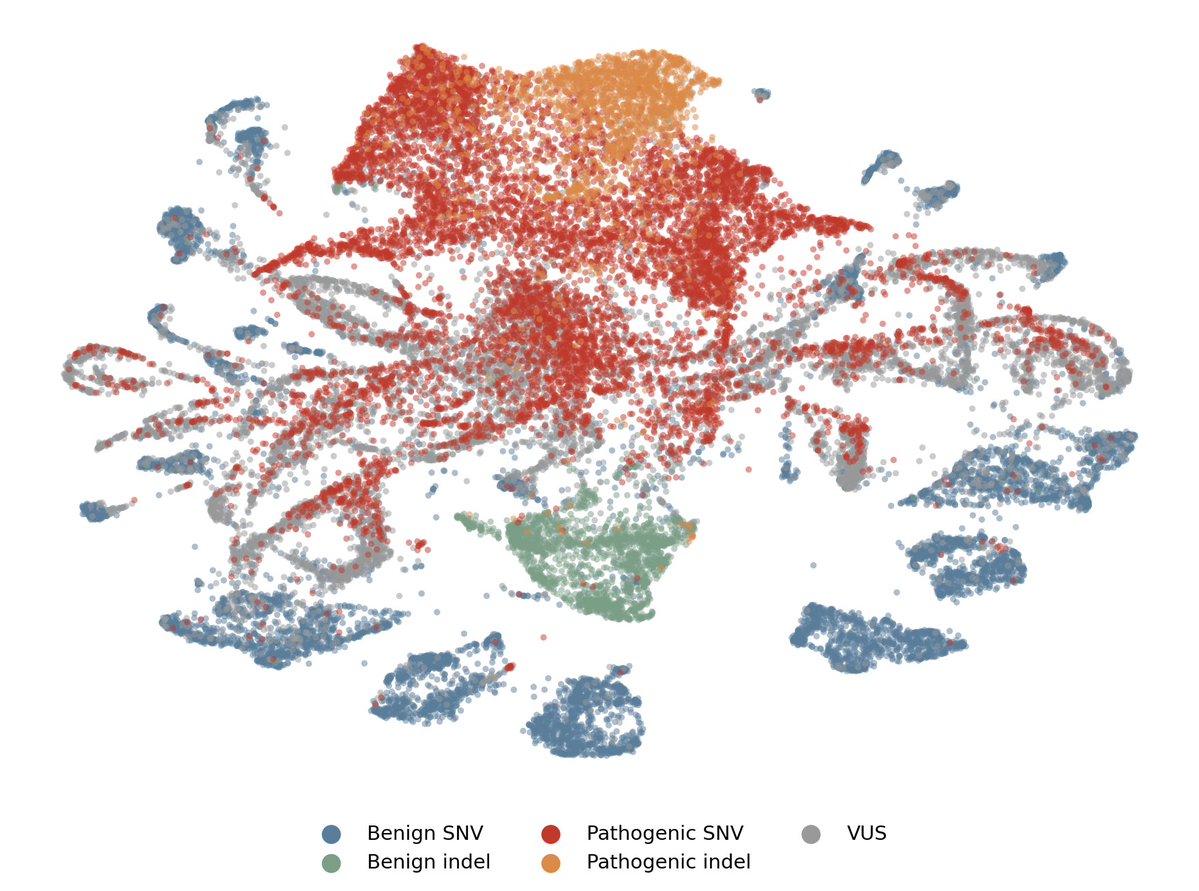
We achieved state-of-the-art performance in predicting which of 4.2 million genetic variants cause diseases by interpreting a genomics model, in a new preprint with @MayoClinic.
We're now releasing an open source database for all variants in the NIH's clinvar database. 🧵(1/8)
New Post: Quantitative Look at Biotech Platforms
Plenty has been written about bio platform strategy but no one's put numbers around it
We used a whole lotta tokens to compile clinical, partnership + financial data on the 100 most successful public platform biotechs of all time
Auto-research for ML training models is all the rage now, but underrated is: auto-research for data!
Sure, you can squeeze out a bit of model performance by optimizing hyperparameters, but code agents can do data work that has been very labour intensive and required a lot of attention to a lot details effortlessly:
> download data from many different data sources
> bring all the data sources into uniform format
> do detailed EDA: find patterns and outliers
> look at 100s of samples and take detailed notes
> make beautiful infographics rather than mpl plots
> iterate on data filtering by looking at more samples
> make a simple pipelines robust and scalable
It's now possible to write data pipelines for dozens of data sources in hours that would have taken weeks of reading many docs, debugging APIs and data formats, wrangling outliers and missing data.
A few weeks ago we gave Claude access to the CPU partition of our cluster and it iteratively refined filters to retrieve a domain subset of FineWeb. This would have taken me 2-3 days to work through while it took Claude just a few hours with almost no babysitting and with a nice logbook.
Thus the long tail of small, niche data sources becomes more accessible and can be aggregated to even larger high quality datasets for cool applications.
Data has been fuelling LLM progress more than model architecture innovations, so I am very excited about this!
"We find that intra-complex interactions are largely conserved, whereas inter-complex relationships are extensively rewired, revealing new context-dependent genetic dependencies." 👏
💡rich resource for virtual cell benchmarking to disambig contextual-modeling vs coexpr-modeling
We mapped gene interactions across different environmental conditions (GxGxE) at scale for the first time in human cells. These maps lead to the realization that many genes function in a context dependent manner which provides insight into how humans have relatively few genes but many cell types. Congratulations Ben!
Paper:
https://t.co/w5bYZUUK4n
I built Scaling Biology 🧬 — a dashboard that live-tracks the volume and growth of key biological data sources across genomics, transcriptomics, and proteomics. The project is open to community contributions, check out the repo linked in footer https://t.co/mTKv7Py4tr
1/13 Excited to share our (@anna_spiro@ChikinaLab@sara_mostafavi) latest preprint! 🧬💻
Personal Genome Prediction isn't just a downstream task—it’s the ultimate end-to-end benchmark for Variant Effect Prediction. We put the new SOTA AlphaGenome to the test and uncovered a striking "Modality Gap" between gene expression and chromatin accessibility. 📄
Link: https://t.co/Xj8wtbaAVt 🧵👇
Together with Emma Dann, we are thrilled to present a massive new Perturb-seq atlas of 22M primary CD4+ T cells, from 4 donors, across 3 timepoints – the result of a decade-long collaboration between the Marson (@MarsonLab) and Pritchard (@jkpritch) labs.
🧵👇
The recent breakthroughs from @nablabio & @chaidiscovery emphasize a split in early biotech strategy.
For the specific range of problems that antibodies address, making the binder, is becoming trivial. This forces a choice between 'fast but competitive' and 'AI intractable'. 🧵
This is a major reason I joined @transcriptabio
We've proved our platform in rare disease – an area that uniquely allows you to:
1) realize the mission of helping people, immediately
2) receive the gold-standard of clinical feedback, immediately
📄: https://t.co/P2UipZuTuN
R&D productivity for new drug approvals has steadily declined over the past 50 years. With the rise of AI tools, a common belief is that they will dramatically boost research productivity by accelerating the "search" for solutions—a sentiment echoed widely at #JPM this week. 🧵
Most current drug discovery efforts is structure-based eg. create small molecules or antibodies that best binds X. However, a drug may not drive its efficacy from its strongest binder. Taking a step away from structure-paradigm, we reason that if a CRISPR knockout of a gene mimics a drug's effects across cancer cell lines, that gene is likely the drug's target. This was done in @EytanRuppin in collaboration with @anideshpandelab and @BenDavidLab
Using this principle, we integrated drug and crispr profiles from 1000s of drugs to find their context specific targets (different cancers or when known target is not expressed but drug is yet killing cancer cells).
We call this tool DeepTarget. We show that this approach outperforms current structure based methods (AF3, RF, Chai) to find drug's target in a genome-wide search, when we had no information on what the target might be. We benchmarked in eight gold-standard drug-target pairs. It took us months to get this benchmarks (we hope this benchmark helps the field)
We present two experimentally validated cases and pls see the paper for this (link at the end).
An intriguing observation is that we had many cases where we have many small molecules targeting the same gene (eg. EGFR) and we found that small molecules with higher predicted target specificity show greater clinical advancement.
Very happy to hear your feedback. Here's the free access link: https://t.co/r6EjR58xg2
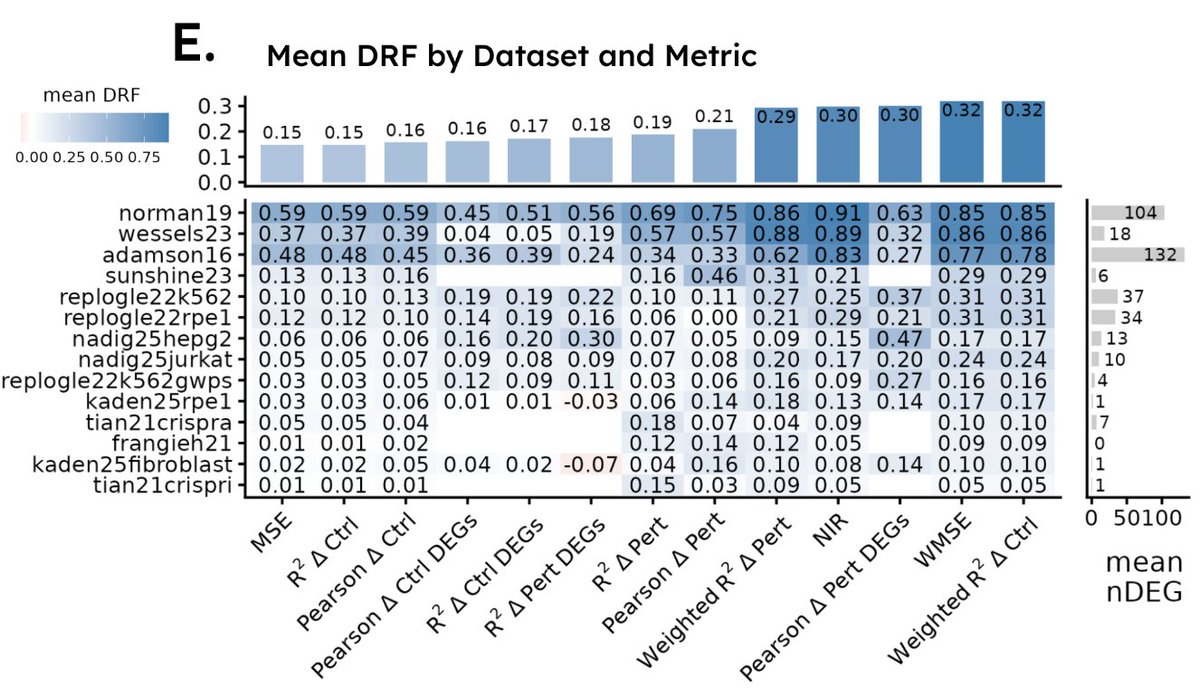
@anshulkundaje Metrics are one thing, but there are other major challenges with data. This paper designs improved metrics to highlight bio signal, but my takeaway is actually that most (perturb-seq) datasets have a very low prediction ceiling
https://t.co/ukIheaigtR
My second post on the Arc Virtual Cell Challenge.
The challenge’s Discord forums are in turmoil. Some participants have discovered a trick to get to the top of the leaderboard.
https://t.co/aRb83MyCCn
#arc_virtual_cell_challenge#foundation_models
@anshulkundaje Yeah, this task is 1/n you expect such a model to perform well on.
Creating community focus on evaluation strategies for this task is a very welcome outcome of the virtual cell challenge!
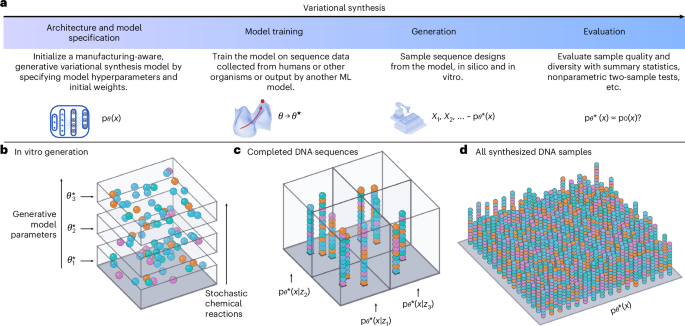
We're excited to present LeaVS, a method to scale up learning for protein function models. It is based on the co-design of wet lab experiments and in silico training.