Why do we assume an RL agent can always compute the correct action immediately? Every policy is a program and thus resource bounded. In this blog, I argue why computation should be part of decision making, illustrated with some toy examples.
🔗https://t.co/tBBRc6K0CX
After automating AI research with @SchmidhuberAI and building AI Scientists at DeepMind, now comes the real experiment: the institution itself.
Excited to co-found @inherent_labs: the recursively self-improving lab for scientific AI.
https://t.co/SQjUduaG3D
RL in Big Worlds is a workshop at @RL_Conference about ideas that enable agents to achieve goals in environments vastly more complex than themselves
This requires giving agents the ability to learn continually and use approximate value functions, models and policies effectively
@DimitrisPapail Love this work! One way to avoid training: LMs are already universal computers if you prompt them to simulate Lag systems: https://t.co/LQYeD0uvgr
My followup shows even untrained LMs can do this, suggesting programmability is key to language computers: https://t.co/YhEKzyQYwo
We organized an RL competition during the first Openmind Research Institute Winter School in Malaysia. The participants were able to implement SARSA and SAC in just 2 days onboard our Embodied MuJoCo Ant! 🎉
Great week at #NeurIPSanDiego packed, intense, and genuinely inspiring. Grateful for all the discussions and feedback. Now looking forward to some quieter days and cooking up new stuff 🚀
Thrilled to announce I'll start in 2026 as faculty in Psych & CS @UAlberta + @AmiiThinks Fellow!! 🥳 Recruiting students to develop theories of cognition in natural and artificial systems 🤖💭🧠. Find me at #NeurIPS2025 workshops (talk at @CogInterp & organising @DataOnBrainMind)
At NeurIPS and interested in continual learning? Stop by our spotlight poster this Friday @ 11am (#508).
Our work provides a computational approach to the big world hypothesis through embedded agents.
Feel free to reach out if you want to meet up while in San Diego!
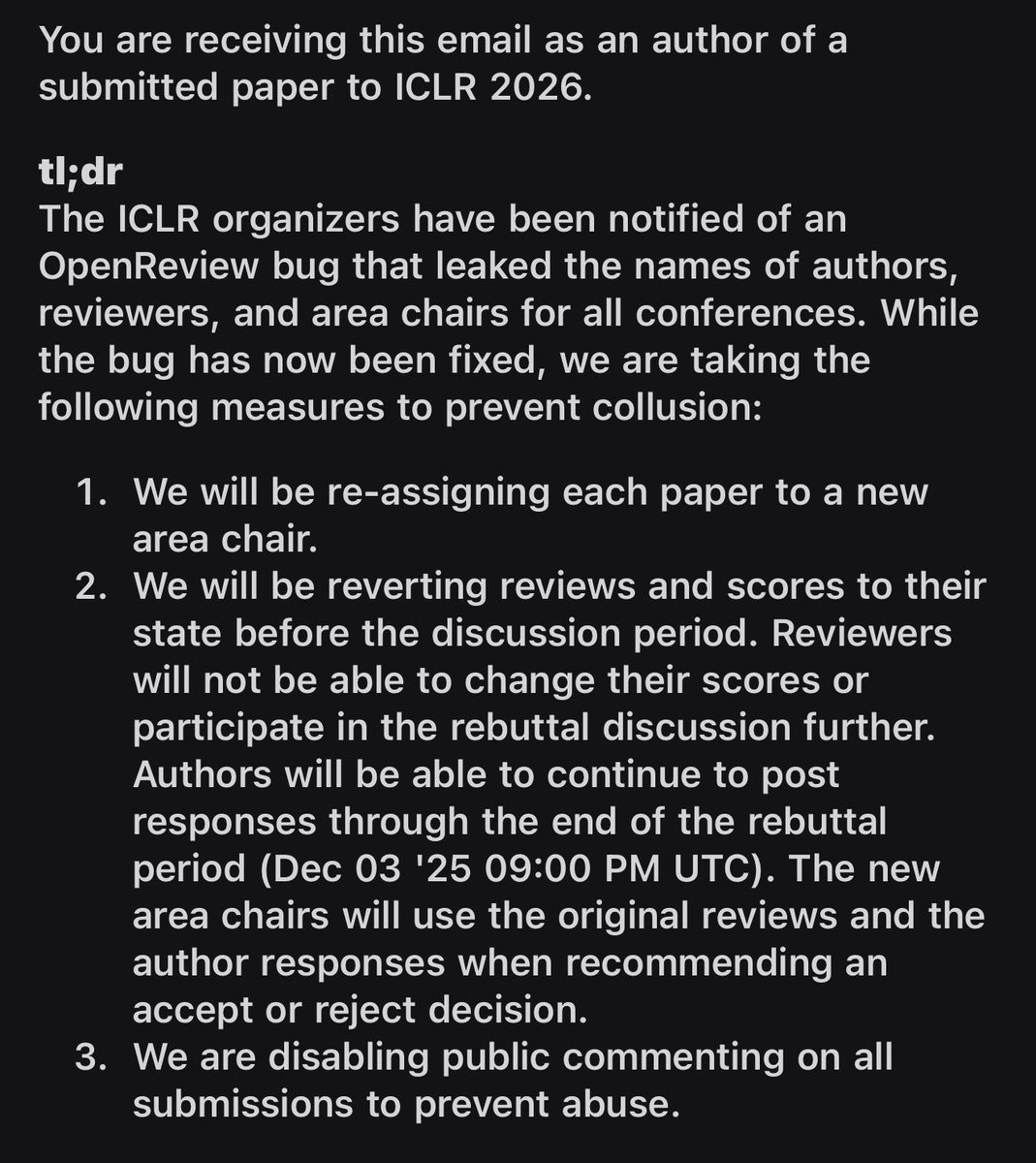
As a reviewer: I spent multiple days replying to Authors' rebuttals. I cannot overstate how eerily similar some of it felt to pointing out bugs to an LLM. I proceeded on the assumption that my critique served the scientific record; it is disheartening to hear otherwise.
Hey @iclr_conf, reverting scores is unnecessary punishment for the majority of the authors who had nothing to do with this incident and had successful rebuttals. Instead of detecting collusions on your end (you have a ton of metadata) why is this everyone’s burden to bear?
Language models can make convenient writing partners, if you know how to use them. But one disadvantage of their increased use in peer-review is a collapse in thought diversity. Instead of hearing from thousands of different minds, we get thousands of samples from a few.
@jsuarez Yeah, it's not RL. It's offline RL. Calling it supervised learning is equally misleading: the targets in offline RL provide only feedback on a chosen action. In supervised learning, the target provides full feedback. Also, interaction is needed for evaluation in offline RL.
Have people seen this prescient 2001 post by @RichardSSutton on self-verification?
"An AI system can create and maintain knowledge only to the extent that it can verify that knowledge itself".
This sentiment underpins much LLM reasoning research today.
https://t.co/gK3DOwqYm8
Thanks to everyone who joined us for another great workshop! 🥳
This year we once again asked our panelists to share a paper or book that heavily influenced their perspective 📚 check out their recommendations here! https://t.co/ZVfbTWk0lg
🚀 Excited to announce our paper "Balancing Expressivity and Robustness: Constrained Rational Activations for RL" will be an *oral* at #CoLLAs2025!
We study how trainable rational activations boost expressivity in RL but can also harm stability:
I will be presenting a poster at RLDM on Wednesday @ 4:30pm. We show that embedding an agent implicitly constrains both it and the environment. We use this constraint to characterize continual adaptation. https://t.co/3eS6qDCD2T
Feel free to reach out if you're attending RLDM!
🚨 We extended Finding the Frame's submission deadline to June 15 AoE! 🚨
✨We're looking for bold ideas that rethink the foundations of RL: goals, values, rewards, formalisms, and beyond🚀
More details: https://t.co/mNy0SGJtRu
See you @RL_Conference !
🚨 Reminder! Submissions for @RL_Conference's Finding the Frame are due May 30 (AoE)!
We're looking for bold ideas that rethink the foundations of RL: goals, values, rewards, formalisms, and beyond.
🧠Philosophy, theory, critique welcome!
🔗More details: https://t.co/mNy0SGJtRu