Agreed. Been shipping a multi-agent AI system in senior care for a year, and the “model = product” assumption is still the #1 reason enterprise AI pilots stall out.
Raw Claude is brilliant. Raw Claude dropped into a clinical workflow, no tool contracts, no evals, no scoped memory, is a liability.
What actually ships:
• Skills and domain instruction packs
• Tool design (most teams underinvest here)
• Agent routing and clear task ownership
• Verification loops (evals, not vibes)
• State and memory boundaries (brutal in multi-tenant)
The model is the engine. The system is the product.
🚨 STOP BURNING YOUR TOKENS!
If you use Claude Code, you are probably wasting 80% of your context window.
I found 10 ace tools that will completely rescue your API bill.
1. Caveman Claude
- Literally makes Claude talk like a caveman
- Slashes 75% of output tokens with zero loss in accuracy
Repo → https://t.co/eEvSOvHutG
2. RTK (Rust Token Killer)
- A blazing fast proxy that filters terminal output
- 60-90% reduction and completely dependency-free
Repo → https://t.co/lDfjbsbPD5
3. Code Review Graph
- Claude reads only what matters using a Tree-sitter graph
- An unbelievable 49x token reduction on huge monorepos
Repo → https://t.co/xGn6Pp88yX
4. Context Mode
- Sandboxes raw output into SQLite instead of your context
- A staggering 98% context reduction on logs & GitHub
Repo → https://t.co/Jut2bvBMUD
5. Claude Token Optimizer
- Brilliant setup prompts that optimize any project
- 90% token savings, taking docs from 11K to 1.3K
Repo → https://t.co/0uOFODbG7e
6. Token Optimizer
- Hunts down the invisible ghost tokens eating your context
- Fully restores and protects your context quality
Repo → https://t.co/LUOzjECXKm
7. Token Optimizer MCP
- Adds aggressive caching and compression to your MCP tools
- 95%+ token reduction through pure intelligence
Repo → https://t.co/b5Eqruo2PM
8. Claude Context
- Zilliz’s hybrid vector search MCP
- Makes your entire codebase the context for 40% less cost
Repo → https://t.co/hPG6pb0j3G
9. Claude Token Efficient
- Just drop one CLAUDE.md file into your repo
- Enforces strict terseness with zero code changes
Repo → https://t.co/fNrl6nwItF
10. Token Savior
- Navigates your code by symbols, not giant files
- 97% reduction on code navigation with persistent memory
Repo → https://t.co/lkILPhfwJh
----
[ The god-tier stack ]
Pick 2-3 based on what’s draining you:
> Massive repo? Code Review Graph + Token Savior
> Heavy terminal output? RTK
> MCP data dumps? Context Mode
> Need an instant fix? Caveman + Claude Token Efficient
Most devs are bleeding tokens.
Run `/context` in a fresh session and watch the savings roll in 👀
In the 1920s, a Stanford psychologist tracked genius children for 50 years.
Malcolm Gladwell breaks down what he discovered:
Rich families → successful. Poor families → failures.
Not average. Failures. Genius-level IQs that produced nothing.
He spent 60 minutes at Microsoft explaining why we're wrong about success:
The psychologist was named Terman. He gave IQ tests to 250,000 California schoolchildren.
He identified the top 0.1%. Kids with IQs of 140 and above.
His hypothesis: these children would become the leaders of academia, industry, and politics.
He tracked them. And tracked them. For decades.
The results split into three groups.
The top 15% achieved real prominence. The middle group had average, moderately successful professional lives.
And the bottom group? By any measure, failures.
The difference wasn't personality. Wasn't habits. Wasn't work ethic.
It was simple: the successful geniuses came from wealthy households. The failures came from poor families.
Poverty is such a powerful constraint that it can reduce a one-in-a-billion brain to a lifetime of worse than mediocrity.
There's a concept called "capitalization rate."
It asks a simple question: what percentage of people who are capable of doing something actually end up doing that thing?
In inner city Memphis, only 1 in 6 kids with athletic scholarships actually go to college.
If our capitalization rate for sports in the inner city is 16%, imagine how low it must be for everything else.
Here's something stranger.
Gladwell read the birth dates of the 2007 Czech Junior Hockey Team:
January 3rd. January 3rd. January 12th. February 8th. February 10th. February 17th. February 20th. February 24th. March 5th. March 10th. March 26th...
11 of the 20 players were born in January, February, or March.
This isn't unique to the Czechs. Every elite hockey team in the world shows the same pattern. Every elite soccer team too.
Why?
The eligibility cutoff for youth leagues is January 1st.
When you're 10 years old, a kid born in January has 10 months of maturity on a kid born in October. That's 3 or 4 inches of height. The difference between clumsy and coordinated.
So we look at a group of 10 year olds, pick the "best" ones, give them special coaching, extra practice, more games.
We think we're identifying talent. We're just identifying the oldest.
Then we give the oldest more opportunities, and 10 years later they really are the best.
Self-fulfilling prophecy.
The capitalization rate for hockey talent born in the second half of the year? Close to zero.
We're leaving half of all potential hockey players on the table because of an arbitrary date on a calendar.
Kids born in the youngest cohort of their school class are 11% less likely to go to college.
11% of human potential squandered because we organize elementary school without reference to biological maturity.
Now here's the part about math.
Asian kids dramatically outperform Western kids in mathematics. The gap is enormous and consistent across decades of testing.
Some people say it's genetic. It's not.
It's attitudinal.
When Asian kids face a math problem, they believe effort will solve it.
When Western kids face a math problem, they believe the answer depends on innate ability they either have or don't.
Here's the proof.
The international math tests include a 120-question survey. It asks about study habits, parental support, attitudes.
It's so long most kids don't finish it.
A researcher named Erling Boe decided to rank countries by what percentage of survey questions their kids completed.
Then he compared it to the ranking of countries by math performance.
The correlation was 0.98.
In the history of social science, there has never been a correlation that high.
If you want to know how good a country is at math, you don't need to ask any math questions. Just make kids sit down and focus on a task for an extended period of time.
If they can do it, they're good at math.
Why do Asian cultures have this attitude?
Gladwell's theory: rice farming.
His European ancestors in medieval England worked about 1,000 hours a year. Dawn to noon, five days a week. Winters off. Lots of holidays.
A peasant in South China or Japan in the same period worked 3,000 hours a year.
Rice farming isn't just harder than wheat farming. It's a completely different relationship with work.
There's a Chinese proverb: "A man who works dawn to dusk 360 days a year will not go hungry."
His English ancestors would have said: "A man who works 175 days a year, dawn to 11, may or may not be hungry."
If your culture does that for a thousand years, it becomes part of your makeup.
When your kids sit down to face a calculus problem, that legacy of persistence translates perfectly.
Now consider distance running.
In Kenya, there are roughly a million schoolboys between 10 and 17 running 10 to 12 miles a day.
In the United States, that number is probably 5,000.
Our capitalization rate for distance running is less than 1%.
Kenya's is probably 95%.
The difference isn't genetic. The difference is what the culture values and where it spends its attention.
Here's the most fascinating finding.
30% of American entrepreneurs have been diagnosed with a profound learning disability.
Richard Branson is dyslexic. Charles Schwab is dyslexic. John Chambers can barely read his own email.
This isn't coincidence. Their entrepreneurialism is a direct function of their disability.
How do you succeed if you can't read or write from early childhood?
You learn to delegate. You become a great oral communicator. You become a problem solver because your entire life is one big problem. You learn to lead.
80% of dyslexic entrepreneurs were captain of a high school sports team. Versus 30% of non-dyslexic entrepreneurs.
By the time they enter the real world, they've spent their whole life practicing the four skills at the core of entrepreneurial success: delegation, oral communication, problem solving, and leadership.
Ask them what role dyslexia played in their success and they don't say it was an obstacle.
They say it's the reason they succeeded.
A disadvantage that became an advantage.
Here's what Gladwell wants you to understand:
When we see differences in success, our default explanation is differences in ability.
We forget how much poverty, stupidity, and attitude constrain what people can become.
We refuse to admit that our own arbitrary rules are leaving talent on the table.
We cling to naive beliefs that our meritocracies are fair.
The capitalization argument is liberating.
It says you don't look at a struggling group and conclude they're incapable. It says problems that look genetic or innate are often just failures of exploitation.
It says we can make a profound difference in how well people turn out.
If we choose to pay attention.
This 60 minute Microsoft talk will teach you more about success than every self-help book you've ever read combined.
Bookmark this & give it an hour today, no matter what.
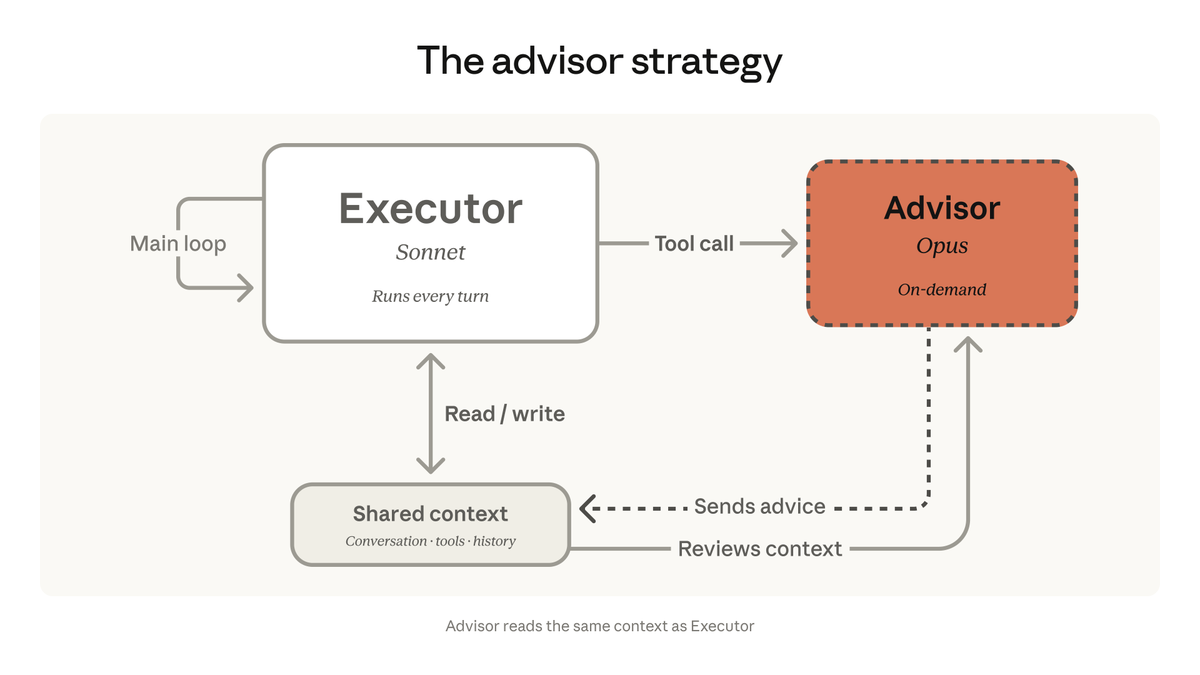
We're bringing the advisor strategy to the Claude Platform.
Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost.
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
https://t.co/NQ7IfEtYk7
let me explain the importance of this
an engineer solved a problem that’s been plaguing the Internet for 3 decades
every website you’ve ever used relies on a text layout system from the 1990s
the browser loads a font, measures text, figures out where lines break, and positions everything vertically
every step depends on the previous one… every step forces the browser to pause and recalculate
you’ve felt this problem plenty times before even if you didn’t know what caused it:
→ Slack’s scroll jumping when message heights are wrong
→ Google Docs getting slow on long documents because every keystroke recalculates everything below your cursor
→ AI chat apps getting janky when streaming because each new token can cause a line wrap that shifts the entire page
same root cause every damn time.
text measurement is locked inside the browser’s DOM… it’s slow… and there’s been no alternative… for 30 damn years
Pretext bypasses all of it:
→ pure TypeScript text measurement… no DOM… no CSS… no browser reflow
→ you give it text, a font, and a width... it returns exact line breaks, widths, and heights… using pure math
→ around 500x faster in many cases than the standard approach
→ supports every language including mixed bidirectional text, CJK, Japanese, Korean, Arabic, and emojis
→ the engine is 15 kilobytes
→ built and validated by running Claude Code and Codex against browser ground truth for weeks
the demos are wild:
→ hundreds of thousands of text boxes virtualized at 120fps with no DOM measurement
→ shrinkwrapped chat bubbles with zero wasted pixels… something CSS literally cannot do
→ responsive multi-column magazine layouts that reflow dynamically
→ variable font ASCII art
over the years, developers moved rendering to Canvas… scrolling to custom implementations… positioning to JS
but text was the one thing you couldn’t move out of the browser… it was the last piece locked inside the DOM with no alternative
now we have a solution
this was built by Cheng Lou… one of the foundational developers behind React, Facebook Messenger, and Midjourney.
he’s not just anyone… lol
if you build anything on the web, this now changes what’s literally possible
this unlocks new UI patterns, layouts, interfaces, and experiences like we’ve never seen before
go look at the demos in the quote posts
it’s open source.
npm install @chenglou/pretext
insane these are all running in a browser
the future of design is still to come
🚨 BREAKING: Pennsylvania State University just found the hidden flaw killing every AI agent memory system.
> Memory built from one model's traces gets contaminated with that model's biases, shortcuts, and reasoning quirks. Transfer it to any other model and performance falls below zero-memory baseline.
> The fix: make two models solve the same problem. Extract only what survived across both. Llama 3 8B jumps from 27.4% to 42.4%.
> Every agent memory system in production works the same way. The model solves problems. The memory stores what worked. The model retrieves those memories later and reasons better. The assumption buried inside this design: the stored knowledge is about the task, not about the model that solved it.
> Pennsylvania State University tested whether that assumption holds. They gave a 7B model's memory to a 32B model. Performance dropped from 63.8% to 50.6% on MATH500, and from 68.3% to 34.1% on HumanEval.
> Then they gave the 32B model's memory to the 7B model. Performance dropped again MATH500 fell from 52.2% to 50.6%, HumanEval from 42.7% to 34.1%. Both directions failed. Both fell below the zero-memory baseline.
> The reason is structural. A model's reasoning traces don't just capture what the correct answer required. They capture how that specific model thinks its preferred solving strategies, its heuristic shortcuts, its stylistic patterns. Memory distilled from those traces encodes the model's reasoning personality alongside the actual task knowledge. When a different model retrieves that memory, it gets handed instructions optimized for a completely different cognitive architecture. The guidance actively interferes.
> MEMCOLLAB fixes this by making the memory construction itself cross-model. Two agents a smaller and a larger model independently solve the same problem. One trajectory succeeds. One fails. The system contrasts them at the structural reasoning level: what reasoning principle was present in the successful trajectory and violated in the failed one? What error pattern appeared in the failure that the success avoided? The extracted memory stores only those abstract invariants not the solution, not the reasoning style, not the model-specific heuristics. Just the rule that held across both.
→ 7B model with 32B's memory: MATH500 drops from 52.2% to 50.6%, HumanEval drops from 42.7% to 34.1%
→ 32B model with 7B's memory: consistent degradation across benchmarks
→ MEMCOLLAB on Llama 3 8B: MATH500 jumps from 27.4% to 42.4%, average across four benchmarks from 41.7% to 53.9%
→ MEMCOLLAB on Qwen 7B: MATH500 from 52.2% to 67.0%, HumanEval from 42.7% to 74.4%
→ Inference efficiency: average reasoning turns drop from 3.3 to 1.5 on HumanEval, 3.1 to 1.4 on MBPP
→ Cross-architecture memory construction (Qwen 32B + Llama 8B) outperforms same-family construction on GSM8K: 95.2% vs 93.6%
The efficiency finding is the one that gets overlooked. MEMCOLLAB doesn't just improve accuracy it makes agents reach correct answers in fewer steps. HumanEval reasoning turns cut from 3.3 to 1.5. MBPP from 3.1 to 1.4. The contrastive memory isn't adding more guidance. It's stripping out the noise that was making agents explore dead ends repeatedly. By encoding what not to do as explicitly as what to do, the memory prunes the search space before the agent even starts.
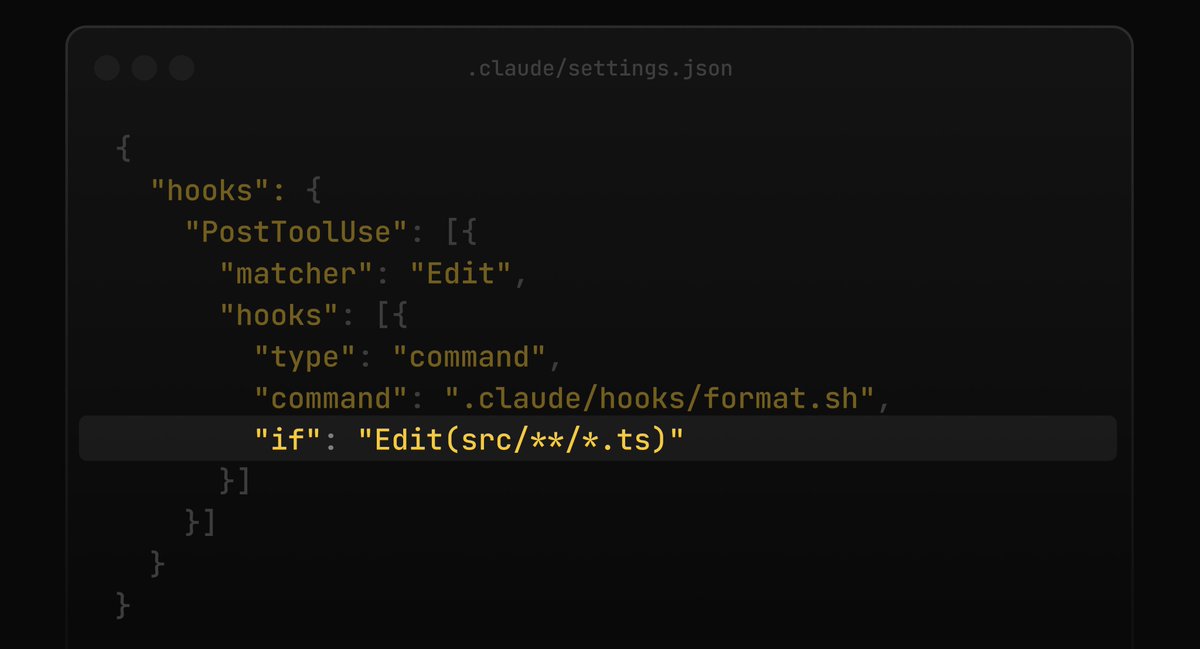
Claude Code now supports an `if` field in hooks
It uses permission rule syntax to filter when a hook runs, which is useful when you want a hook on some bash commands but not every single one!



















![DataChaz's tweet photo. 🚨 STOP BURNING YOUR TOKENS!
If you use Claude Code, you are probably wasting 80% of your context window.
I found 10 ace tools that will completely rescue your API bill.
1. Caveman Claude
- Literally makes Claude talk like a caveman
- Slashes 75% of output tokens with zero loss in accuracy
Repo → https://t.co/eEvSOvHutG
2. RTK (Rust Token Killer)
- A blazing fast proxy that filters terminal output
- 60-90% reduction and completely dependency-free
Repo → https://t.co/lDfjbsbPD5
3. Code Review Graph
- Claude reads only what matters using a Tree-sitter graph
- An unbelievable 49x token reduction on huge monorepos
Repo → https://t.co/xGn6Pp88yX
4. Context Mode
- Sandboxes raw output into SQLite instead of your context
- A staggering 98% context reduction on logs & GitHub
Repo → https://t.co/Jut2bvBMUD
5. Claude Token Optimizer
- Brilliant setup prompts that optimize any project
- 90% token savings, taking docs from 11K to 1.3K
Repo → https://t.co/0uOFODbG7e
6. Token Optimizer
- Hunts down the invisible ghost tokens eating your context
- Fully restores and protects your context quality
Repo → https://t.co/LUOzjECXKm
7. Token Optimizer MCP
- Adds aggressive caching and compression to your MCP tools
- 95%+ token reduction through pure intelligence
Repo → https://t.co/b5Eqruo2PM
8. Claude Context
- Zilliz’s hybrid vector search MCP
- Makes your entire codebase the context for 40% less cost
Repo → https://t.co/hPG6pb0j3G
9. Claude Token Efficient
- Just drop one CLAUDE.md file into your repo
- Enforces strict terseness with zero code changes
Repo → https://t.co/fNrl6nwItF
10. Token Savior
- Navigates your code by symbols, not giant files
- 97% reduction on code navigation with persistent memory
Repo → https://t.co/lkILPhfwJh
----
[ The god-tier stack ]
Pick 2-3 based on what’s draining you:
> Massive repo? Code Review Graph + Token Savior
> Heavy terminal output? RTK
> MCP data dumps? Context Mode
> Need an instant fix? Caveman + Claude Token Efficient
Most devs are bleeding tokens.
Run `/context` in a fresh session and watch the savings roll in 👀](https://pbs.twimg.com/media/HGQWA_7WIAAS7uW.jpg)