Introducing cara-3, the fastest real-time avatar model on the market.
Cara model delivers unmatched realism with sub-180ms response times, setting a new industry standard.
70% of users prefer video over voice.
Every pixel is generated in real time, unlocking natural eye movement, micro-expressions, and emotional subtlety so each conversation feels real.
Comment "CARA" for 500 free credits.
Open source Jarvis that runs on a single GPU
Today we're releasing the vui stack. A local voice agent that you can chat with in real time, with tools and can run claude to do more complex tasks.
Inside this stack is the new vui nano model, a 300M TTS model that can render audio in reply to what you've said and supports a variety of non speech sounds.
vui nano speaks with you, not at you.
The stack can run on as little as 6GB of vram.
Voice cloning supported with prompts of up to 5 minutes. The longer the better.
A voice for your openclaw with our v1/realtime endpoint.
I have developed this on my own so would love to get the communities feedback and help improving it.
Please retweet this so that everyone knows they can have their own private Jarvis
Anam is now integrated with Stream’s Vision Agents 🤙
Stream gives you the realtime multimodal agent framework: calls, state, orchestration, audio/video pipeline. Anam now gives the agent a live avatar in the call.
This setup opens the door for "scene switching". The avatar starts on a neutral background, then changes based on the conversation:
* ask for a recipe → kitchen
* ask about weather → studio
* next user turn → back to neutral
It’s a relatively small thing technically: intercept the Anam video frames, chroma-key the green screen, and swap in a background based on tool calls / transcript callbacks. But it changes the feel a lot. The agent isn’t just talking over video, its environment can react too.
Thanks to the Stream team for leading on the integration!
docs: https://t.co/sOkjkeYmvL
cc @visionagents_ai@neevash@Anam__ai
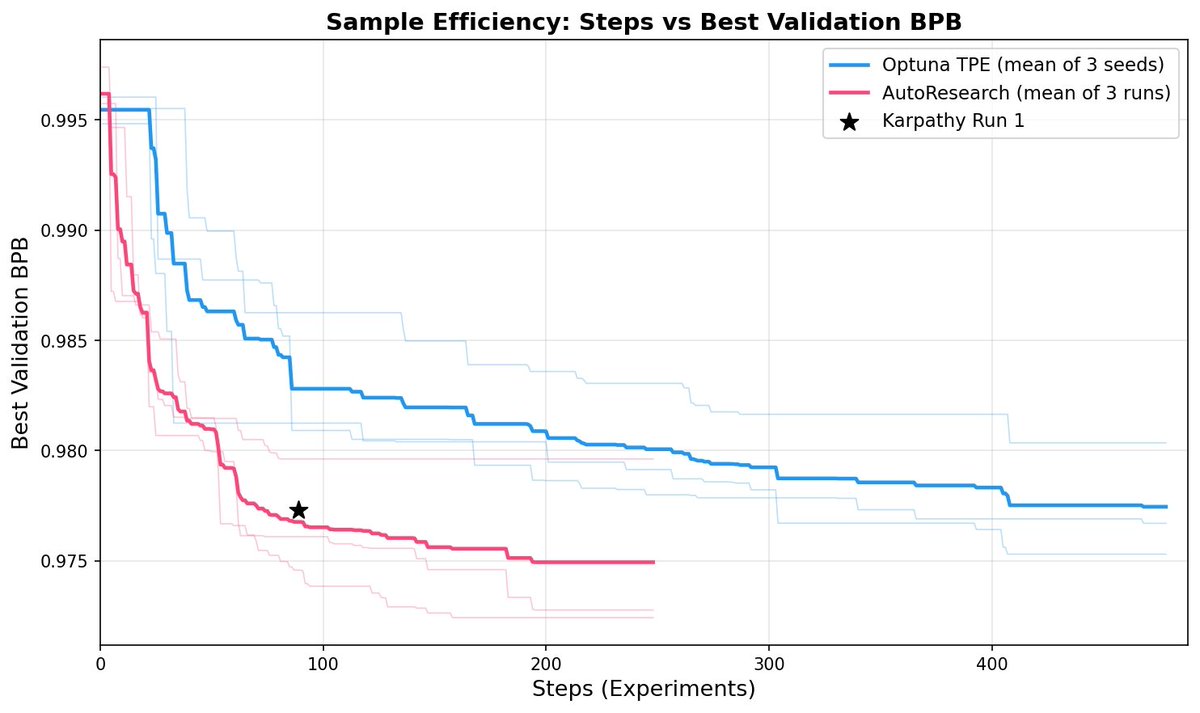
Is autoresearch really better than classic hyperparameter tuning?
We did experiments comparing Optuna & autoresearch.
Autoresearch converges faster, is more cost-efficient, and even generalizes better: 🧵(1/6)
Huge fans @lennysan and @bcherny at Anam.
Enjoyed Boris's recent episode on Lenny's Podcast on the future of coding with AI so much we put together a demo of adding an Anam face to Claude Code.
~15% of users hit unstable connections during interactive avatar sessions. Most never told us. The session just quietly got worse.
We shipped adaptive bitrate. Every Anam session now adjusts to network conditions in real time.
This is table-stakes infrastructure for real-time platforms like Agora and LiveKit. Now it runs on every session.
The difference: conversations that used to stutter or freeze now stay smooth. Sessions run longer. Users don't bounce.
Anam is part of the relaunched AI Startup Pack by Fin.
We're in good company, alongside @ElevenLabs, @Cloudflare, @incident_io, @Attio, and more.
Build with interactive avatars that respond in real time, look realistic, and deploy via API. No upfront cost for 7 months.
Our pipecat contribution just got merged. Anam is now listed as an official community video integration in the pipecat ecosystem.
In case you don't know, pipecat is Daily's open-source framework for building real-time voice agents. 10.5k GitHub stars, used by NVIDIA, Mercor, Descript.
We built a video service that takes TTS audio from the pipeline, streams it to Anam over WebRTC, and returns a synchronized interactive avatar face in real time. The avatar speaks, reacts, handles interrupts natively.