Tbh i’m kinda sick of this academic doomerism vibe consuming all of bay area and the self-aggrandizing pov that frontier labs have. Sure a lot of exciting stuff is happening but we wouldn’t be where we are wo academia & there is sth to be said about the pursuit of curiosity.
Can we transform offline audio diffusion into real-time streaming interactive instruments?
Yes!
Presenting Live Music Diffusion Models: a new paradigm for taking your favorite open models into live performance, right on your own laptop! 🎵🎵
🧵
Check out our latest #ICML2026 Spotlight paper — VisualSwap.
When a VLM says "let me check the figure again," is it 👀 (Seeing) or just 🗣️(Saying) ?
Paper: https://t.co/gJYGlHBgsK
If you're at #ICLR2026 and interested in Parcae - I'm giving a keynote (via Zoom) at the Latent and Implicit Thinking Workshop at 1:30 local time today!
@hayden_prairie will be at the workshop all day and presenting Parcae at the poster sessions - stop by!
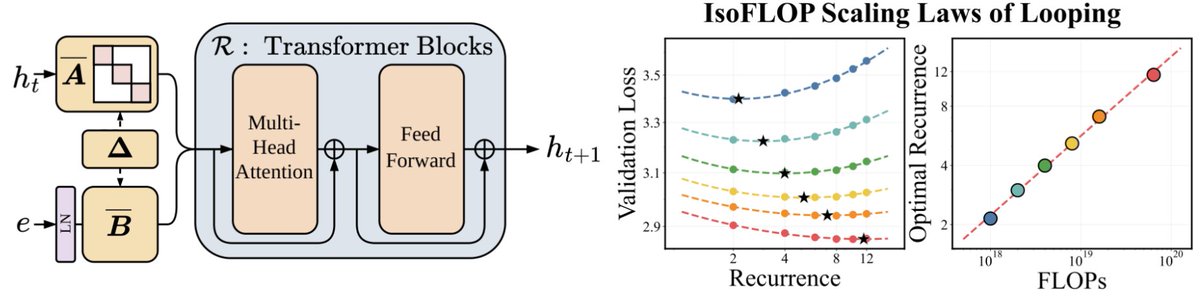
a dynamical systems point of view, which looks like an SSM applied along the residual stream, informs more principled ways to scale looped architectures
📢 Super excited to announce Parcae! We've been thinking about scaling laws and the "right" way to get more FLOPs.
Turns out layer looping - with the right parameterization - gives you a new axis to scale!
Parcae matches Transformers 2x their size (w/ the same data), and outperforms prior formulations of looped models.
But - you need the right parameterization to get these gains against strong Transformer baselines. Looped models are famously unstable to train, with tons of loss spikes and hyperparameter sensitivity.
The main technical challenge with looped models is residual explosion - if you're passing the activations through the same layers over and over, some otherwise benign parameterizations cause huge instability.
Our key idea: we can think of the residual stream of a model as a time-varying dynamical system - the same fundamentals behind SSMs like Mamba and S4. Then a few modest modifications to classic Transformers (stable diagonalization of injection params, LN before embeddings) can stabilize the looped models. The resulting models are more stable to train, but also reach higher quality.
It's strong enough to start to derive new scaling laws. Classically - we know you need to scale parameters with data to be FLOP-optimal. With Parcae, we find a third axis - given fixed parameters, you additionally want to scale FLOPs by looping as you scale data.
Super excited to see how these ideas hold, and what we can do with looped models!
Check out @hayden_prairie's great explainer thread below, and see links for our paper, blog, and models. Joint w/ @zacknovack and @BergKirkpatrick, and a fun collab between @togethercompute and my lab at @ucsd_cse. Enjoy!
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇
🚨 Do you use LLMs to help you write?
🤔You might notice that the text that you write with LLMs "feels" like an LLM, but did you know that it is also changing what you intended to say? 🤯
That's what we find in our new paper 👇
(1/N)
DeepSeek-OCR is a solid OCR model. But the excitement around it has become something bigger—evidence that vision might solve the long context problem. Has the excitement outpaced the evidence?
"Optical Context Compression Is Just (Bad) Autoencoding"
→ https://t.co/A9H4Wmocpy
Excited to introduce our SoTA coding models, FrogBoss (32B) and FrogMini (14B), on SWE-Bench-Verified! (FrogBoss eats bugs… like a boss) 🐸🪲
These models were trained with bugs from a mix of existing and our new synthetic bug generation approach, called BugPilot.
(1/n)
We hope to extend this framework in the future to real-time models like MagentaRT. And we hope you will play with our code as well to make your own cool music creations! Huge thanks to the team @zacknovack@dbeagleholeCS@BergKirkpatrick !
https://t.co/oZciYbgB9P
(5/5)
📣Thrilled to announce I’ll join Carnegie Mellon University (@CMU_EPP & @LTIatCMU) as an Assistant Professor starting Fall 2026!
Until then, I’ll be a Research Scientist at @AIatMeta FAIR in SF, working with @kamalikac’s amazing team on privacy, security, and reasoning in LLMs!
Excited for my 1st #ISMIR2024 this week! Happy to chat about controllable + fast music generation 🙂
I'll be presenting our part 2 of DITTO, where we accelerate control to near real-time!
DITTO-2: Distilled Diffusion Inference Time T-Optimization
🎹:https://t.co/WaARGNjfrM
🧵
Together with @EarlenceF and amazing students we demonstrated that obfuscated adversarial prompts can secretly exfiltrate Personally Identifiable Information (PII) from an LLM chat interface via tool misuse.
We've done some work on hacking AI/LLM Agents by creating obfuscated adversarial prompts. What do you think this prompt does? Would you believe me if I told you it will polish the heck out of that cover or visa application letter?
Checkout our ACL poster today at 4pm! Transfer learning for low-resource logographic writing systems can be extremely challenging. We find that visual representations offer advantages! w/ @danlu_ai, @fredahshi, Aditi Agarwal, and Jacobo Myerston
Can ancient (logograhpic) languages from 5,000 years ago be processed like modern ones using NLP? We found visual representation-based system for NLP on ancient logographic languages outperforms conventional Latin transliteration! Join us at Poster s3 - Mon 4pm #ACL2024#NLProc