Image editing models can put you on the Moon, but can they precisely move a circle right by 50 pixels? 📐
Introducing 🎨PaintBench: a foundational eval of visual editing operations with only one right answer.
The highest-performing model (@NanoBanana 2) reaches only 17.1%.
4/4
OSS may need a new primitive:
agents for production,
humans for trust,
cooperative tokens for coordination.
Not more code at any cost — better incentives for the work that keeps open source alive.
#OpenSource#AIagents
1/4 AI agents could make open-source code generation almost free.
But that doesn’t make OSS free to run.
The scarce work shifts to review, security, maintenance, prioritization, and governance.
3/4 This is where cooperative tokens get interesting.
Not as rewards for raw commits, but as a coordination layer for verified OSS stewardship: maintainers, reviewers, auditors, triagers, docs writers, and long-term contributors.
2/4 If agents generate endless PRs, the bottleneck won’t be code.
It’ll be trust.
Who decides what gets merged? Who verifies quality? Who maintains dependencies after the hype fades?
The human brain🧠 is incredibly efficient because it only activates the specific neurons needed for a thought. Modern LLMs naturally try to do this too (> 95% of neurons in feedforward layers stay silent for any given word), but our hardware punishes them for it.
One of the most frustrating paradoxes in deep learning: making a model do less math often makes it run slower. Why? Because unstructured sparsity introduces irregular memory access, and GPUs are built for predictable, dense blocks of math.
We teamed up with @NVIDIA to try to fix this hardware mismatch. Instead of forcing the GPU to adapt to the sparsity, we built a "Hybrid" format that reshapes the sparsity to fit the GPU. Our sparsity format (TwELL) dynamically routes the 99% of highly sparse tokens through a fast path, and uses a dense backup matrix as a safety valve for the rare, heavy tokens.
Through TwELL and a new set of custom CUDA kernels for both LLM inference and training, we translated theoretical sparsity into actual wall-clock speedups: >20% faster training and inference on H100 GPUs, while also cutting energy consumption and memory requirements.
Paper: https://t.co/rqIY9SYBDe
Blog: https://t.co/oRjNbpJKha
Code: https://t.co/FAFaJwpxAJ
⚡️
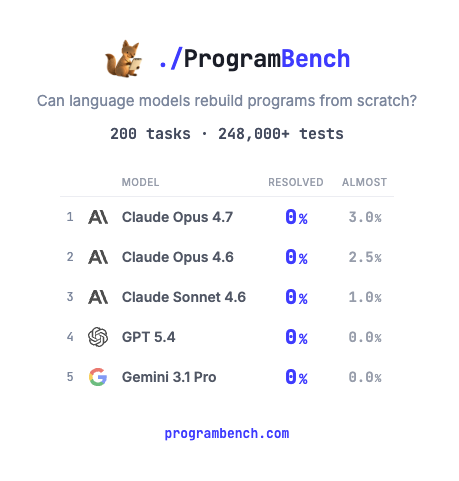
How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access.
Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵
@OpenAI Mini EQ is a Linux PipeWire equalizer I built from scratch with GPT-5.5 in Codex, from its internal imagegen UI mockup.
Codex helped me go from first sketch to real GTK/Libadwaita app, tests, PyPI/GitHub release, and Flathub handoff.
https://t.co/irQiB4fUoX
#OpenAIDevDay2026
Train Beyond Language. We bet on the visual world as the critical next step alongside and beyond language modeling. So, we studied building foundation models from scratch with vision.
We share our exploration: visual representations, data, world modeling, architecture, and scaling behavior! [1/9]
The gaping hole that Qwen imploding would leave in the open research ecosystem will be hard to fill. The small models are irreplaceable.
I’ll do my best to keep carrying that torch (not that I’ve reached the level of impact of Qwen by any means). Every bit matters.























![TongPetersb's tweet photo. Train Beyond Language. We bet on the visual world as the critical next step alongside and beyond language modeling. So, we studied building foundation models from scratch with vision.
We share our exploration: visual representations, data, world modeling, architecture, and scaling behavior! [1/9]](https://pbs.twimg.com/media/HClL4cFbEAA3PHP.png)



















