Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇
Codex has become a core part of how we do data science @OpenAI.
Today we’re launching a new Data Science plugin, built by data scientists for data scientists.
It helps with everything from exploring raw data and diagnosing metric changes to building dashboards, writing reports, and getting to stakeholder-ready insights faster.
The feedback has been strong:
• 100% of users said it speeds up the path from raw data to insight.
• 100% said it helps them take on more work than they otherwise could.
The best description I’ve heard is that it’s a force multiplier: getting us from 0→80% quickly, helping us make progress across multiple projects at once, and improving the quality of the final output.
Excited to share it with everyone.
https://t.co/Ou5jhCEjMi
Many developers have suspected for months that GPT-5.5 outperforms Claude Sonnet for coding. But SWE-Bench reported near-parity, and it made people question what they’d been seeing in practice.
DeepSWE aligns more closely with that day-to-day experience: GPT-5.5 scores 70% versus Claude Sonnet at 32%. That difference is substantial.
DeepSWE focuses on what tends to matter in real workflows: whether an agent can take a short behavioral prompt, locate the correct area of the codebase, and implement the change cleanly - without needing you to enumerate files, modules, and functions. SWE-Bench often fails to capture that, due to dataset contamination and weaker verification.
https://t.co/C3s80xfDkk
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
[Tip de R] · [Paquete 📦] · FakeDataR: Generá datasets sintéticos que cuidan la privacidad, espejando la estructura de tus datos reales.
¿Necesitás compartir un dataset para pedir ayuda, desarrollar un modelo o testear tu código, pero te preocupa la privacidad de los datos originales? ¡Olvidate de editar a mano y arriesgarte a exponer información sensible! El paquete FakeDataR te permite crear copias sintéticas de tus datasets que imitan la estructura, tipos de datos y niveles de factores, pero sin la información sensible. Es la solución perfecta para trabajar de forma segura y eficiente.
✔️ Generá datasets sintéticos que mantienen la estructura (esquema, tipos, niveles de factores, rangos y valores faltantes) de tus datos originales, ¡pero con contenido "falso"!
✔️ Prepará bundles de datos sintéticos con esquemas JSON y guías, listos para usar directamente con Large Language Models (LLMs), agilizando tus workflows de IA.
✔️ Construí datos falsos directamente desde tablas de bases de datos SQL sin necesidad de leer las filas reales, protegiendo la privacidad desde el origen.
✔️ Tené el control para enmascarar o eliminar campos sensibles, asegurándote de que solo compartís lo que es seguro.
💡 Tip
Usá FakeDataR para crear entornos de desarrollo y pruebas seguros. Podés compartir estos datasets sintéticos con colaboradores o LLMs sin riesgo, ya que todo el proceso ocurre en tu máquina, ¡sin subir tus datos reales a la nube!
🔗 https://t.co/o42kSUSh0G
✍️ Zobaer Khan
#RStats #RStatsES #Rtips #DataScience
It's hard to beat the stock Linux kernel that Linus and gang already went to great lengths optimizing. Omarchy just ships with that, and it seems to hold up pretty well! https://t.co/k1Q8MtnwlQ
You can now use your ChatGPT subscription in the Zed agent, with the same usage and rate limits you benefit from in Codex directly. We're grateful that @openaidevs continues to support subscription-based access for third-party tools, even as others move toward usage-based billing.
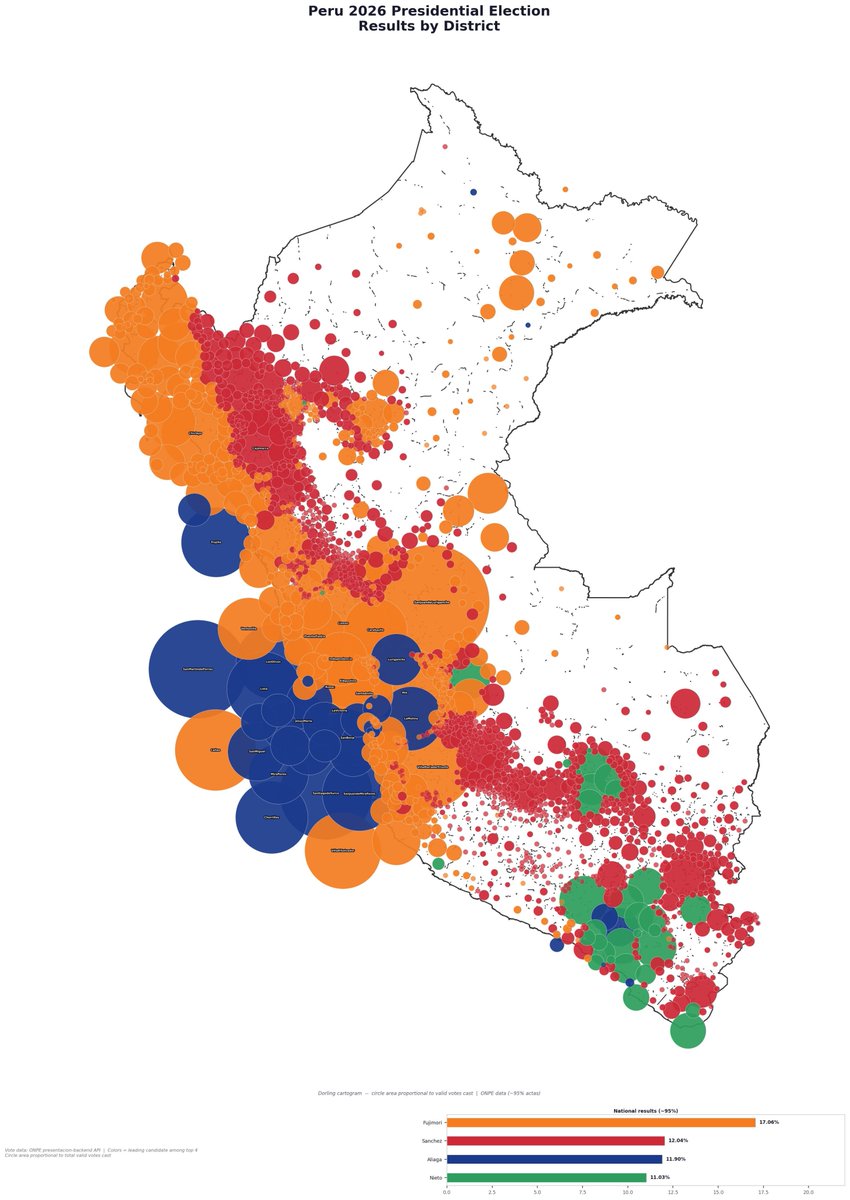
Los votos de Sanchez se ven como la cordillera de los Andes al plotear cada mesa de votacion a nivel nacional(+un valle al centro y el Monte Olimpo en Cajamarca).
Pronto sale dashboard! Seria bacan agregarle fronteras distritales,absolutos ademas de %, etc. Esto es un adelanto🙂.
¡Nueva actualización de Codex!
La semana pasada, justo cuando terminé de grabar el vídeo del martes, el equipo lanzó un update con un montón de novedades que no podía dejar fuera.
Aquí tienes el vídeo con todas ellas.
Capítulos:
00:00 Por qué este vídeo es un adendo al anterior
00:23 Onboarding adaptado al tipo de tarea
01:06 Nuevo panel visual persistente
01:49 Mejores previews para slides y documentos
02:33 Forks para explorar caminos paralelos
03:26 Documentos y hojas de cálculo dentro de Codex
04:10 Navegador interno con tamaños de dispositivo
04:59 Side chat para preguntar sin interrumpir
06:08 Plugin Codex Security
07:44 Computer Use más rápido
09:40 Pop-up always-on-top con Google Drive
11:06 Nuevas opciones de dictado por voz
12:23 Hacia un Codex más adaptado a cada usuario
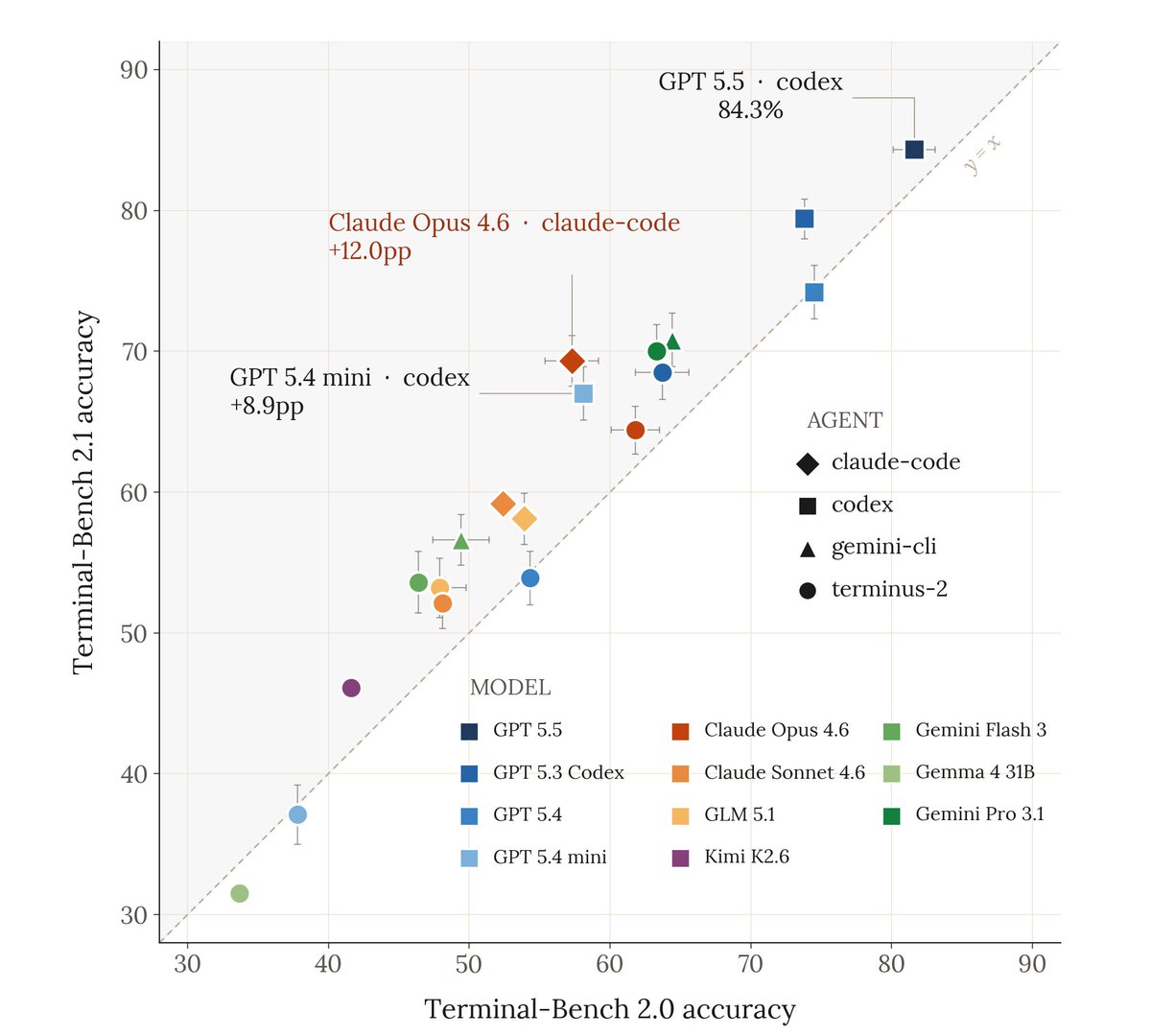
Very excited to release Terminal-Bench 2.1!
Coding agents are among the most economically consequential deployments of LLMs to date. As agents improve, benchmark reliability matters more.
We audited TB2.0 and found and corrected issues in 28/89 tasks. 30% of the benchmark!
But the rankings survived, absolute scores moved up to 12pp!
I love how open the Codex app is, you can run any model you want, even local.
These are the only configs you need to use the app with Gemma 4 via Ollama.
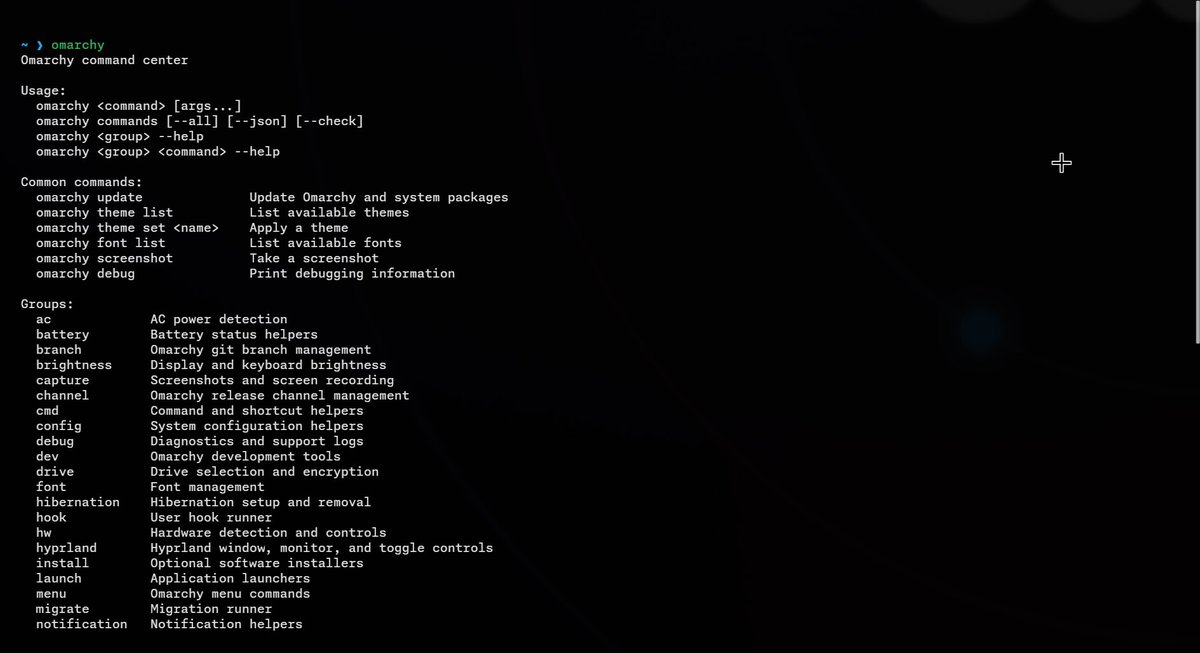
The new Omarchy CLI collapses 230+ commands into one easy to use, self-documenting, AI-friendly CLI.
The usage details and groupings for each command are parsed on-the-fly in <100ms from their individual files providing zero potential for usage drift.
On 10yr+ old hardware, that same worst case scenario is ~200ms. 🙂
Big Update🤩: #paperclip now includes full papers from all of arXiv, PubMed Central and 150 million abstracts!🖇️
You can give your LLM all that knowledge in one line—all optimally indexed for AI agents. Much more thorough and ~100x faster than web search, and free.
Both OpenAI and Anthropic just released official prompting guides.
Both say the same thing.
Your old prompts don’t work anymore.
But for opposite reasons.
Claude Opus 4.7 stopped guessing what you meant. It does exactly what you type. Nothing more, nothing less.
Vague instructions that worked on 4.6? They now produce narrow, literal, sometimes worse results.
Not because the model got dumber. Because it stopped compensating for sloppy thinking.
GPT-5.5 went the other direction. OpenAI’s guide literally says: “Don’t carry over instructions from older prompt stacks.”
Legacy prompts over-specify the process because older models needed hand-holding. GPT-5.5 doesn’t. That extra detail now creates noise and produces mechanical output.
Claude got more literal.
GPT got more autonomous. Both now punish the same thing: prompts written without clear thinking behind them.
One developer on Reddit captured it perfectly after analyzing hundreds of community posts. The complaints tracked almost perfectly with prompt specificity.
Precise prompts got better results on 4.7. Vague prompts got worse. The model didn’t regress. The prompts did.
OpenAI’s new framework is “outcome-first prompting.” Describe what good looks like. Define success criteria. Set constraints. Then get out of the way. The model picks the path.
Anthropic’s framework is the inverse: be surgically specific about what you want, because the model won’t fill in your blanks anymore.
Two different architectures. Two different philosophies.
One identical conclusion: the person writing the prompt is now the bottleneck, not the model.
Boris Cherny, the engineer who built Claude Code, posted on launch day that even he needed a few days to adjust. That post got 936 likes.
Meanwhile, Anthropic increased rate limits for all subscribers because the new tokenizer uses up to 35% more tokens on the same input.
The model is more expensive to run lazily. Cheaper to run precisely.
The models are converging in capability. The gap between good and bad output is no longer about which model you pick.
It’s about the 2 minutes of structured thinking you do before you type anything.
That thinking system is the skill. The prompt is just what it produces.
Este cuadro, elaborado por el economista César Martinelli, me parece la mejor representación gráfica de la distribución de los votos de los cuatro primeros candidatos.
Muestra, en tamaño proporcional a la población, el más votado de estos cuatro candidatos en cada distrito.
1/2
LEVEL UP: GIT AVANZADO 👾
Es hora de enfrentarte a los verdaderos jefes del control de versiones 🧌⚔️
📆 29 de abril | 🕠 13:00 | 📍 Aula 2 FDI
👨🏫 Con Diego Caballero Ruiz
⚠️⚠️ IMPORTANTE: Para esta segunda parte es imprescindible traer descargado e instalado Git o Git Bash.






































![estacion_erre's tweet photo. [Tip de R] · [Paquete 📦] · FakeDataR: Generá datasets sintéticos que cuidan la privacidad, espejando la estructura de tus datos reales.
¿Necesitás compartir un dataset para pedir ayuda, desarrollar un modelo o testear tu código, pero te preocupa la privacidad de los datos originales? ¡Olvidate de editar a mano y arriesgarte a exponer información sensible! El paquete FakeDataR te permite crear copias sintéticas de tus datasets que imitan la estructura, tipos de datos y niveles de factores, pero sin la información sensible. Es la solución perfecta para trabajar de forma segura y eficiente.
✔️ Generá datasets sintéticos que mantienen la estructura (esquema, tipos, niveles de factores, rangos y valores faltantes) de tus datos originales, ¡pero con contenido "falso"!
✔️ Prepará bundles de datos sintéticos con esquemas JSON y guías, listos para usar directamente con Large Language Models (LLMs), agilizando tus workflows de IA.
✔️ Construí datos falsos directamente desde tablas de bases de datos SQL sin necesidad de leer las filas reales, protegiendo la privacidad desde el origen.
✔️ Tené el control para enmascarar o eliminar campos sensibles, asegurándote de que solo compartís lo que es seguro.
💡 Tip
Usá FakeDataR para crear entornos de desarrollo y pruebas seguros. Podés compartir estos datasets sintéticos con colaboradores o LLMs sin riesgo, ya que todo el proceso ocurre en tu máquina, ¡sin subir tus datos reales a la nube!
🔗 https://t.co/o42kSUSh0G
✍️ Zobaer Khan
#RStats #RStatsES #Rtips #DataScience](https://pbs.twimg.com/media/HIwulaVXAAAKK_i.jpg)