If models can think for 100,000 tokens, why do they still lose the plot?
Come join us for this AI4Science on alphaXiv talk: Long-Horizon Reasoning in LLMs.
In this session, Sumeet Motwani (@sumeetrm) and Charles London (@CharlieLondon02) will share recent work on both training and evaluating models that can reason over much longer chains of thought.
Their LongCoT benchmark tests whether models can handle long chains of dependent reasoning across different fields. Each step is solvable on its own, but the full problem requires planning, state tracking, backtracking, and avoiding compounding errors. Even the best models still score below 10%.
They will also discuss h1, which trains long-horizon reasoning by chaining short problems into longer dependency graphs, then using RL with outcome-only rewards and a gradually harder curriculum.
So if longer context windows are not enough, what does it actually take to make models reason reliably over long scientific and technical workflows?
Whether you’re working on frontier LLMs, AI4Science, reasoning, or just curious about what current models still cannot do, you should definitely check this talk out!
🗓 Friday May 15th 2026 · 11 AM PT
🎙 Featuring Sumeet Motwani and Charles London
💬 Casual Talk + Open Discussion
New mini experiment + blogpost + trajectories!
tldr; we boost performance of RLM(GPT-5.2) to double the best performing number (38.7% --> 65.6%) on LongCoT-mini without any training! An example of the mismanaged geniuses hypothesis (MGH) we (@zli11010, @lateinteraction) proposed earlier this month.
The LongCoT benchmark showed that frontier LMs and RLMs struggled to solve difficult compositional reasoning tasks. The paper generally attributes this to the RLMs inability to perform task decomposition, but we argue this is more our fault in how we prompt them; this capability is fully available to GPT-5.2 with an RLM harness!
Building on @raw_works's insightful blogpost and @sumeetrm / @CharlieLondon02 et al.'s incredibly useful benchmark, where they originally found RLMs to be incapable of solving the MATH and CS splits altogether. We did not train anything since the release of the initial benchmark.
To be fully transparent, these results are not meant to be added to their leaderboard either; benchmarks measure isolated capabilities, and we focus on showing (through different, rather specific prompting) that the capabilities required to solve these tasks are available to the models without additional training! It also has implications about how we would go about training these systems. Full blog below, it's a nice read :)
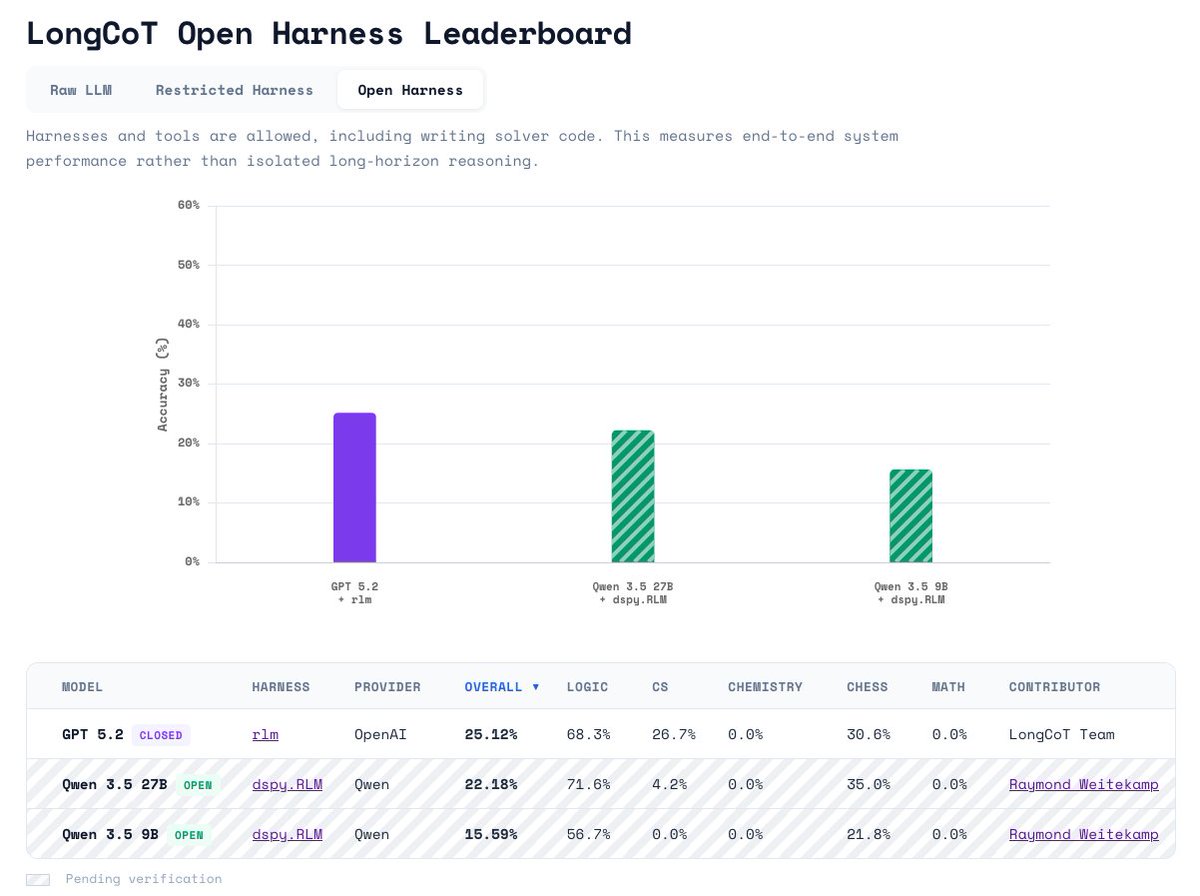
LongCoT is adding two new leaderboards! Due to the interest in agents (particularly RLMs), we’re adding a “Restricted Harness” and an “Open Harness” leaderboard.
GPT 5.2 RLM from our paper is SOTA on “Open Harness” at 25.12%. We expect tool-use SOTA to exceed this very soon!
On “Open Harness”, we allow all tool-use and code execution. On “Restricted Harness”, models may manage context, call subagents, etc, but may not write specific solver code (e.g. writing a BlocksWorld or Sudoku solver). We’re particularly excited about this leaderboard, as it allows agents to do their own context management, while sticking to LongCoT’s goal of testing models’ intrinsic reasoning capabilities.
LLMs will supposedly solve climate change and cure cancer, but in fact they can't even do multi-turn reasoning tasks effectively (SOTA models are < 10% on this benchmark).
Interestingly, this work directly compares how much extra performance you get when you add an agentic harness (figure 7): a lot for simple optimization problems, 0% for math and chemistry.
How can we test the "intrinsic" long-horizon reasoning capability of a model?
We made a neat template-based problem construction, where each subproblem is easy, but their composition primarily makes any problem hard.
Also avoids test saturation by scalable problem difficulty!
We already do RLM evals on LongCoT (although our benchmark is intended for just models, not scaffolds). Your results in the main post are different from what you have in your comments and are with LongCoT-mini (https://t.co/V6X8Dyr9kX).
We're very excited about RLMs as a direction and are interested in seeing performance go up on our explicit horizon domains (Math/Chemistry/Computer Science).
Proud to release LongCoT, a hard benchmark for long-horizon reasoning capabilities - measuring reasoning over hundreds of thousands of tokens. 🥳
Project led by my student @sumeetrm in collaboration with many others; excited about kicking off Oxford Witt Lab's collaboration with Ruben Glatt @Livermore_Lab
We’re releasing LongCoT, an incredibly hard benchmark to measure long-horizon reasoning capabilities over tens to hundreds of thousands of tokens.
LongCoT consists of 2.5K questions across chemistry, math, chess, logic, and computer science. Frontier models score less than 10%🧵
Training multi-agent teams is hard.
#AgentFlow comes to the rescue. We introduce Flow-GRPO, an efficient method to train multi-agent teams. Improves planning and tool use.
Selected as an #ICLR2026 Oral (top 1%)🚀
New paper: Detecting Multi-Agent Collusion Through Multi-Agent Interpretability
LLM agents can secretly collude, even inventing steganographic signals that text monitors can't catch. We show you can detect this from their activations.
w/@casdewitt
🧵 (1/n)
While we cannot always detect steganography directly, sometimes the effects of sharing information secretly can be observed relative to the subsequent behaviour of the agents - an important decision-theoretic approach to steganography detection in CoT settings pioneered by @usmananwar391@j_piskorz_
✨New AI Safety work on Steganography and LLM monitoring✨
We propose ‘steganographic gap’: the first principled metric for detecting and quantifying encoded reasoning in LLMs, which can reveal hard-to-detect forms of steganography, e.g., paraphrasing-resistant steganography.
The Red Team at @AISecurityInst is hiring! We work with frontier AI companies to red team their misuse safeguards, control measures, and alignment techniques. As the stakes rise, we need much stronger red teaming and many more talented researchers working within gov 🧵
🚀 I am recruiting MSc, undergraduate, and CDT/PhD students to join https://t.co/NO3KT0xJvl at Oxford.
Projects span autonomous agents, multi-agent security, interpretability, and evaluation science - ambitious, publication-oriented research at the frontier of AI capability & safety.
Details: https://t.co/usFRtbzUQu
📩 [email protected]
🤩🤩Congratulations to @philiptorr & @casdewitt both have been awarded 2025 Schmidt Sciences AI2050 Research Fellowships. Read more here: https://t.co/Sm1WzOEk5E & here https://t.co/pT1G3KSn2S
1. Introduction to ARIA by jenny read
2. Why are we here? by yours truly
3. Security Primitives: New Advances & State of the Art by @iamnotnicola
4. Open Challenges in Multi-Agent Security: Towards Secure Systems of Interacting AI Agents by @casdewitt
5. Embodied AI: What’s happening and how fast are things progressing? by @rowstron
6. Hardness in Silicon by @0xquintus
7. Challenges in Securing Ultra-Large-Scale Cyber Physical Infrastructures by Awais Rashid
8. Verification in Physical Systems Enable Autonomous Engineering by Eder Medina
9. Trust Robots, Everywhere by @engineerEdith
10. Consumable Quantum Data by Dar Gilboa
11. Cryptographic Sensing by Yuval Ishai
12. Mathematical Formalization of Cognition as an Attack Surface by @babagley
13. Cryptographically-Verifiable Sustainability x AI: A Powerful Future Tool for Our Planet? by Jessica Man
Huge congrats, Tim @frtimlive - joining David Silver's RL team at DeepMind is epic. Looking back fondly at our ICLR spotlight on Illusory Attacks. Onward! 🚀🥳
I recently joined @GoogleDeepMind in London.
Excited to be part of David Silver's RL team to work on Gemini, Reinforcement Learning and Agents.
It’s been amazing speaking with so many fascinating people in the first weeks and learning from them!
Emerging from presenting MALT: Improving reasoning with multi-agent LLM training @COLM2025 to share the next work on reasoning: this time, showing that long-horizon reasoning can be significantky improved by curriculum training on chained tasks. Fantastic efforts led by @sumeetrm Alesia Ivanova @CharlieLondon02
🚨How do we improve long-horizon reasoning capabilities by scaling RL with only existing data?
Introducing our new paper: "h1: Bootstrapping LLMs to Reason over Longer Horizons via Reinforcement Learning"🫡
> RL on existing datasets saturates very quickly
> Reasoning over complex interdependent problems is incredibly important, but we currently lack enough long-horizon reasoning data
> Long-horizon problems are hard, which means training signal is sparse. We’d need a way to provide dense supervision
Our solution composes existing short-horizon data to form a synthetic curriculum that keeps growing in complexity! This allows us to scale RL on the same dataset while avoiding saturation, with curriculum acting as dense rewards.
At a small scale, we see massive in-domain long-horizon improvements, which transfer to significantly harder benchmarks. Training on composed 6th grade math problems leads to strong gains on AIME! 1/N🤿🧵
Thank you to ❇️Christian Schroeder de Witt @casdewitt (Open challenges in multi-agent security) and ❇️Nora Ammann @AmmannNora (Gradual Disempowerment) for their fantastic talks and office hours at the Cooperative AI Summer School today.