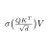Thursday 4/16
‣ Agent Builders Breakfast - Founders & Builders in SOMA, SF https://t.co/QRmSX8uREE
@miradu
‣ AI Breakfast: Build your AI workspace in one morning https://t.co/9lPtAlEwLA
@rajoshighosh
‣ Platform Engineering & AI https://t.co/N54XPaEgmO
@cbergman
‣ Voice AI Meetup: Medical Mode https://t.co/2aKaB14EXc
@ryanseams@theaievangelist
‣ Claws Out🦞 GMI ClawHub Demo Night https://t.co/5fm2cI2BJd
@nicoleegong@gmi_cloud@yuqih
‣ Voice AI builders night https://t.co/2qn7jABD79
@modal@braintrust
‣ AI Meets HumanX Social w/ Rootly AI, MongoDB, Runpod, & More! https://t.co/52HTzP6ff5
‣ Slides Down: AI Founders Party by DigitalOcean & Zendesk Apr 16 https://t.co/gr9F4vs7J3
@neffko@julianachyzhova@yfilipch
Thursday 4/16
‣ Agent Builders Breakfast - Founders & Builders in SOMA, SF https://t.co/QRmSX8uREE
@miradu
‣ AI Breakfast: Build your AI workspace in one morning https://t.co/9lPtAlEwLA
@rajoshighosh
‣ Platform Engineering & AI https://t.co/N54XPaEgmO
@cbergman
‣ Voice AI Meetup: Medical Mode https://t.co/2aKaB14EXc
@ryanseams@theaievangelist
‣ Claws Out🦞 GMI ClawHub Demo Night https://t.co/5fm2cI2BJd
@nicoleegong@gmi_cloud@yuqih
‣ Voice AI builders night https://t.co/2qn7jABD79
@modal@braintrust
‣ AI Meets HumanX Social w/ Rootly AI, MongoDB, Runpod, & More! https://t.co/52HTzP6ff5
‣ Slides Down: AI Founders Party by DigitalOcean & Zendesk Apr 16 https://t.co/gr9F4vs7J3
@neffko@julianachyzhova@yfilipch
💓@AndrewYNg Note to self: look here before next CFP submission or helping others. Ask the model to summarize best advice per conference CFP rules and topic submitter wants to talk about...
Releasing a new "Agentic Reviewer" for research papers. I started coding this as a weekend project, and @jyx_su made it much better.
I was inspired by a student who had a paper rejected 6 times over 3 years. Their feedback loop -- waiting ~6 months for feedback each time -- was painfully slow. We wanted to see if an agentic workflow can help researchers iterate faster.
When we trained the system on ICLR 2025 reviews and measured Spearman correlation (higher is better) on the test set:
- Correlation between two human reviewers: 0.41
- Correlation between AI and a human reviewer: 0.42
This suggests agentic reviewing is approaching human-level performance.
The agent grounds its feedback by searching arXiv, so it works best in fields like AI where research is freely published there. It’s an experimental tool, but I hope it helps you with your research.
Check it out here: https://t.co/n7ctnDilJJ
Don't🍷about #OOM running out of memory!
@huggingface is making it easier to run huge #TransformerandDiffuser models on consumer GPUs w quantization, tensor parallelism, offloading. Hear from @stevhliu how to fit these models on your setup. https://t.co/FJXgzA0FxD #HuggingFace
Thankfully @cbergman's article can help you identify key convos with an AI hack to perform semantic clustering simply by prompting LLMs!
https://t.co/J0z9FLuhq7
GPT-4.5 is ready!
good news: it is the first model that feels like talking to a thoughtful person to me. i have had several moments where i've sat back in my chair and been astonished at getting actually good advice from an AI.
bad news: it is a giant, expensive model. we really wanted to launch it to plus and pro at the same time, but we've been growing a lot and are out of GPUs. we will add tens of thousands of GPUs next week and roll it out to the plus tier then. (hundreds of thousands coming soon, and i'm pretty sure y'all will use every one we can rack up.)
this isn't how we want to operate, but it's hard to perfectly predict growth surges that lead to GPU shortages.
a heads up: this isn’t a reasoning model and won’t crush benchmarks. it’s a different kind of intelligence and there’s a magic to it i haven’t felt before. really excited for people to try it!
🚀 Day 5 of #OpenSourceWeek: 3FS, Thruster for All DeepSeek Data Access
Fire-Flyer File System (3FS) - a parallel file system that utilizes the full bandwidth of modern SSDs and RDMA networks.
⚡ 6.6 TiB/s aggregate read throughput in a 180-node cluster
⚡ 3.66 TiB/min throughput on GraySort benchmark in a 25-node cluster
⚡ 40+ GiB/s peak throughput per client node for KVCache lookup
🧬 Disaggregated architecture with strong consistency semantics
✅ Training data preprocessing, dataset loading, checkpoint saving/reloading, embedding vector search & KVCache lookups for inference in V3/R1
📥 3FS → https://t.co/JRZ2eYk1aK
⛲ Smallpond - data processing framework on 3FS → https://t.co/BoUA6YNjZK
@TDataScience TL;DR my blog is about how to go from (data science + code) → (AI prompts + LLMs) for the same results—just faster and with less effort!
Here is the @TDataScience archive link: https://t.co/ElOXBy2kym
I just published a blog in #DataScienceCollective, the new free open version of @TDataScience. Here, I look at 9 different discords and prompt #LLMs to do #Clustering on user messages.
https://t.co/qovzCo8grF
Seems devil is in the details for accuracy/latency tradeoff decisions. #w8a8fp: 1. Weights quantized using usual symmetric fp8 method. 2. Activations quantized without pre-calibration i.e. symmetric quantization parameters calculated on-the-fly during model inference.
🤔hmm, but this paper shows w8a8-fp (symmetric weight and dynamic per-token activation quantization in fp8) is "essentially lossless" in accuracy. https://t.co/Tfh2MZ9bQc
Interesting! The most common inference quantization int8/fp8 is not necessarily the best. bf16 #quantization is a way better accuracy/latency tradeoff.
Interesting! The most common inference quantization int8/fp8 is not necessarily the best. bf16 #quantization is a way better accuracy/latency tradeoff.
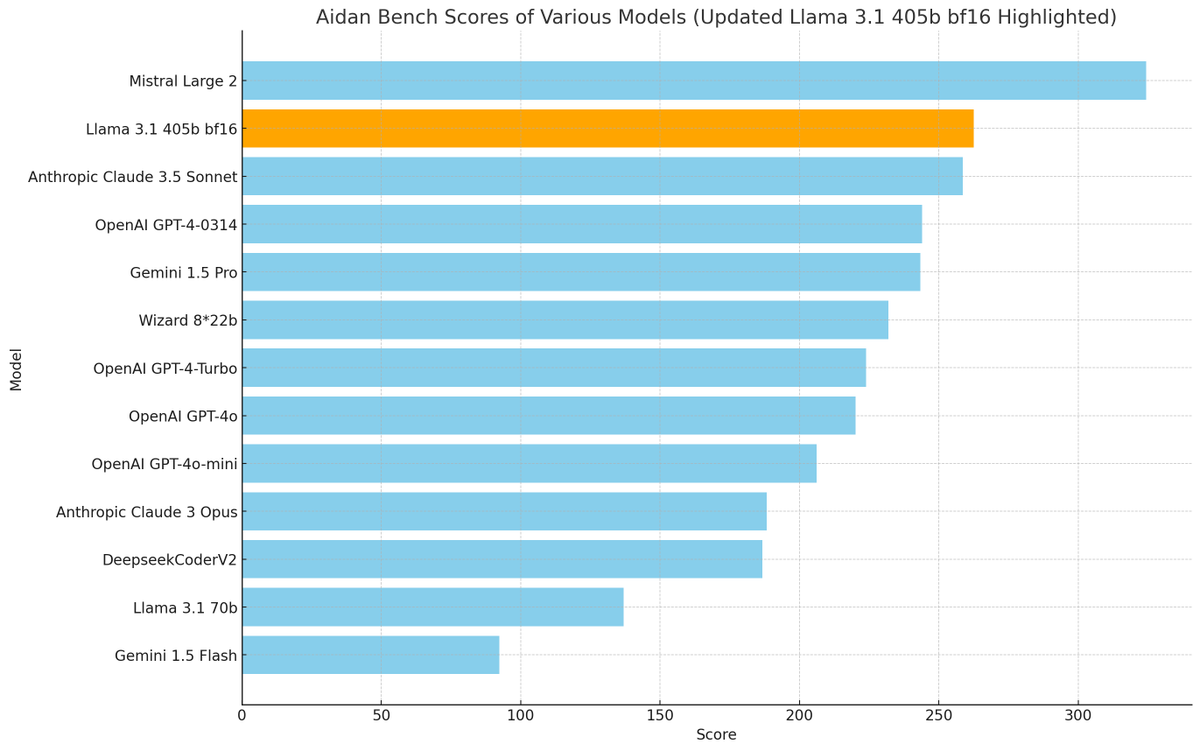
aidan bench update:
i ran llama 3.1 405b at bf16 (shoutout to @hyperbolic_labs) and we got a *way* better score.
405b fp8 is around gpt-4o-mini-level
405b bf16 beats claude-3.5-sonnet
give me bf16 or give me death
Self-care life hack: if you feel a bit down/tired, paste the url of your website/linkedin/bio in Google's NotebookLM to get 8 min of realistically sounding deep congratulations for your life and achievements from a duo of podcast experts 😂
CUDA MODE hackathon today!
Here's @karpathy on the 🏖️ origin story of llm.c, and what it hints at for the fast, simple, llm-compiled future of custom software.
Interesting take-down how to do LoRA properly, quickly, with less memory, on all layers @danielhanchen's tweet and blog https://t.co/p5WVg9isXF !
> For continued pretraining, I advise people to train on all layers (inc gate) + lm_head, embed_tokens, use RS LoRA, use rank>=256
My take on "LoRA Learns Less and Forgets Less"
1) "MLP/All" did not include gate_proj. QKVO, up & down trained but not gate (pg 3 footnote)
2) Why does LoRA perform well on math and not code? lm_head & embed_tokens wasn't trained, so domain shifts not modelled. Also reason why "LoRA Forgets Less". Use "modules_to_save" in HF PEFT or "lm_head", "embed_tokens" in @UnslothAI
3) Code rank=256 used α=32 (too small!) (pg 18), but Maths α=2*r=512. RS LoRA paper showed α/sqrt(r) needed for larger ranks. & common practice is 2*r. So also why Code did worse than Maths
4) Extrapolating Maths vs fft looks good. Small datasets LoRA>fft, but I theorize that's because of reason 2
5) LoftQ & PiSSA paper init LoRA from SVD(W) => papers show comparable perf of LoRA
6) LoRA+ paper shows B matrix needs larger lr. DoRA (mentioned in paper) learns these scalars.
TLDR: Code worse since α=32 is too small. No embed_tokens, lm_head (or layernorms), not even gate_proj? Better init & lr scaling can help
For continued pretraining, I advise people to train on all layers (inc gate) + lm_head, embed_tokens, use RS LoRA, use rank>=256
LoRA paper: https://t.co/CzRpid0CUp
RS LoRA paper: https://t.co/fg21UYqH58
LoRA+ paper: https://t.co/tgJjFdgSiG
PiSSA paper: https://t.co/VBr22c1grv
DoRA paper: https://t.co/YQApPi2MJk
🌟Join our expert panel at The AI Conference 2024 to explore advanced RAG (Retrieval-Augmented Generation) techniques.
Learn how integrating information retrieval with generative models is revolutionizing AI, making it more contextually rich and useful in real-world applications.
Don’t miss out—register now to be part of the future of AI!
https://t.co/JrDLmuSTcV
#developers #TAIC2024 #data #programmers #software #innovators #techindustry #engineer #scientists #theaiconference
Monday Meetup is right around the corner! 🗣 Join us in SF on August 5 for exciting talks:
🔢 Using Ray Data for Multimodal Embedding Inference with @cbergman
📐 A Different Angle: Retrieval Optimized Embedding Models @marqo_ai
🛠 Building the Future of Neural Search: How to Train State-of-the-Art Embeddings with @mixedbreadai
🔗 Save your spot: https://t.co/3oOeYosewo
#Meetup #AI #RAG #SFevents