Introducing Multi-Head LatentMoE 🚀
Turns out, making NVIDIA's LatentMoE [1] multi-head further unlocks O(1), balanced, and deterministic communication.
Our insight: Head Parallel; Move routing from before all-to-all to after. Token duplication happens locally. Always uniform, always deterministic.
It works orthogonally to EP as a new dimension of parallelism. For example, use HP for intra-cluster all-to-all as a highway, then use EP locally.
We propose FlashAttention-like routing and expert computation, both exact, IO-aware, and constant memory. This is to handle the increased number of sub-tokens.
Results:
- We replicate LatentMoE and confirm it is indeed faster than MoE, with matching model performance. (See Design Principle IV in [1])
- Up to 1.61x faster training than MoE+EP with identical model performance.
- Higher model performance while still 1.11x faster with doubled granularity.
📄 Paper: https://t.co/re5ludi0mB
💻 Code: https://t.co/8pHdtN3Z4i
[1] Elango et al., "LatentMoE: Toward Optimal Accuracy per FLOP and Parameter in Mixture of Experts", 2026. https://t.co/cNmJ8tchTF
https://t.co/Lhvj3dimz9
Training an RNN in parallel by RNN cell to predict a compressed state that predicts future outputs given past inputs. But as this state is distilled from time-parallel models its structure could be similar to that.
Synthetic Data Playbook update!
TLDR: Most diversity scores don't predict synthetic-data quality. G-Vendi is the exception.
I added four diversity metrics across 83 synthetic-pretraining experiments: Vendi Score, mean intra-set cosine similarity, and near-duplicate rate (all on bge-base-en-v1.5 sentence embeddings), plus G-Vendi from the Prismatic Synthesis paper. The selling point if any of them works: rank a candidate rephrasing recipe from 1000 generated samples, instead of generating millions of tokens and training a student model end-to-end.
The three semantic metrics fall apart on aggregate downstream performance. Vendi correlates negatively (ρ = −0.21), mean cosine similarity positively (ρ = +0.23, but that's just −Vendi by construction), near-duplicate rate essentially zero. None of them is a usable overall predictor.
G-Vendi flips the script. Instead of asking "do these samples look different?", it asks "would training on each of them push the model's weights in different directions?". You backprop the cross-entropy loss through a frozen proxy LLM (I used Qwen3-0.6B), sketch the resulting gradient, L2-normalise and then take the Vendi Score in that feature space. Across the same 83 experiments, G-Vendi correlates positively with the macro score (ρ = +0.26) and is the single best predictor for reasoning of any metric I tested (ρ = +0.38), beating every quality classifier and semantic-diversity variant.
But none of this displaces DCLM-difference. Even G-Vendi explains only ~7% of variance on the macro score, while DCLM-difference (output minus input quality score) still wins overall (ρ = +0.61). Diversity metrics complement quality classifiers, they don't replace them. The shortcut around training-and-evaluating still doesn't exist.
Sometimes system instructions need to be updated during the course of a conversation or session.
But editing the top-level system prompt field invalidates the prompt cache for everything that follows.
We put a lot of work into calibrating thinking effort for Opus 4.8.
As you're trying out the model, if you do run into any examples of it still over/under thinking, please flag it to us!
Most researchers agree that autoregression is best when memory bandwidth is cheap and diffusion is best when FLOPS are cheap. They also admit the future of compute is all FLOPS because memory scaling is hard and scaling FLOPS is easy. So why not go all in on diffusion????
Language Models Need Sleep
"Transformer-based large language models are increasingly used for long-horizon tasks; however, their attention mechanism scales poorly with context length. To handle this, we study a sleep-like consolidation mechanism in which a model periodically converts recent context into persistent fast weights before clearing its key-value cache."
"increasing sleep duration N for our models improves performance, with the largest gains on examples that require deeper reasoning."
Why does deep learning generalize? What does weight decay really do? Can algorithmic information theory address these questions?
In my latest preprint, I give a proof that the minimum neural weight norm matches the minimum program length (aka Kolmogorov Complexity), up to a logarithmic factor. In other words, the neural network with the smallest possible weight norm (that fits the data) must encode the shortest program (that fits the data).
The result only holds for fixed-precision neural nets: infinite precision nets can store infinite information with finite (small) weights.
https://t.co/eMZIGQDf2f
Random Q:
Anyone know what happened to @magicailabs , who supposedly cracked the "100 Million context windows" and got investments by Nat & Daniel, Nvidia etc?
Last blog nearly 2 years ago, no announcements since then, no demo of the ultra long context windows... silence?
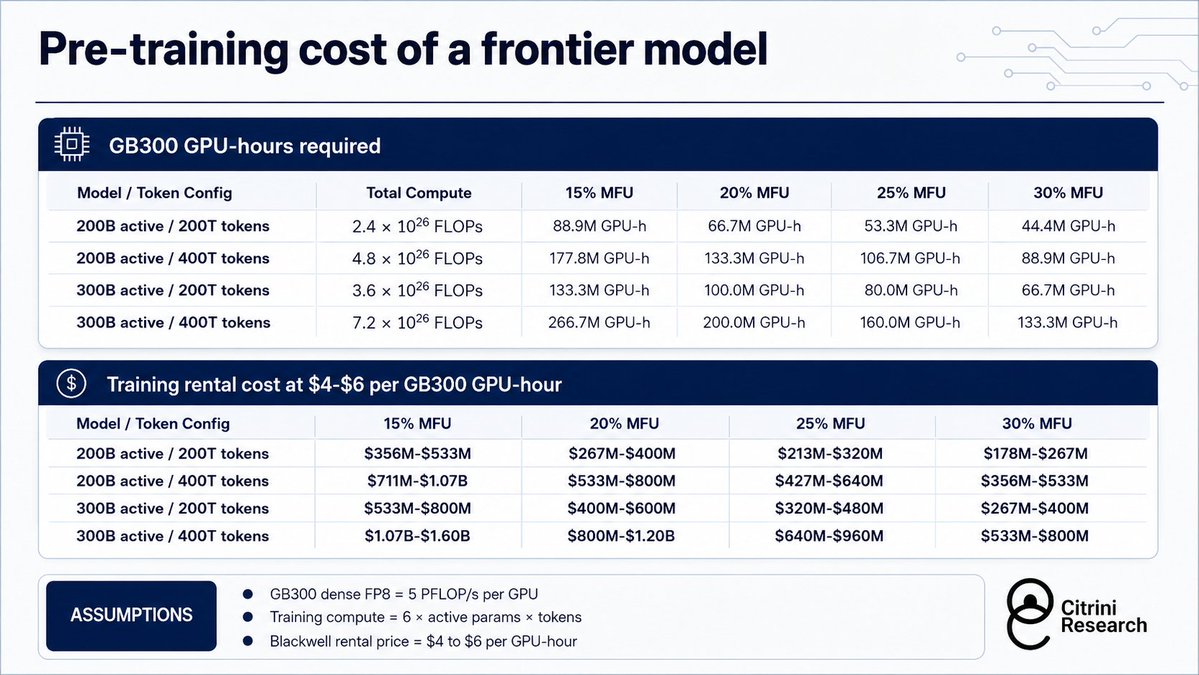
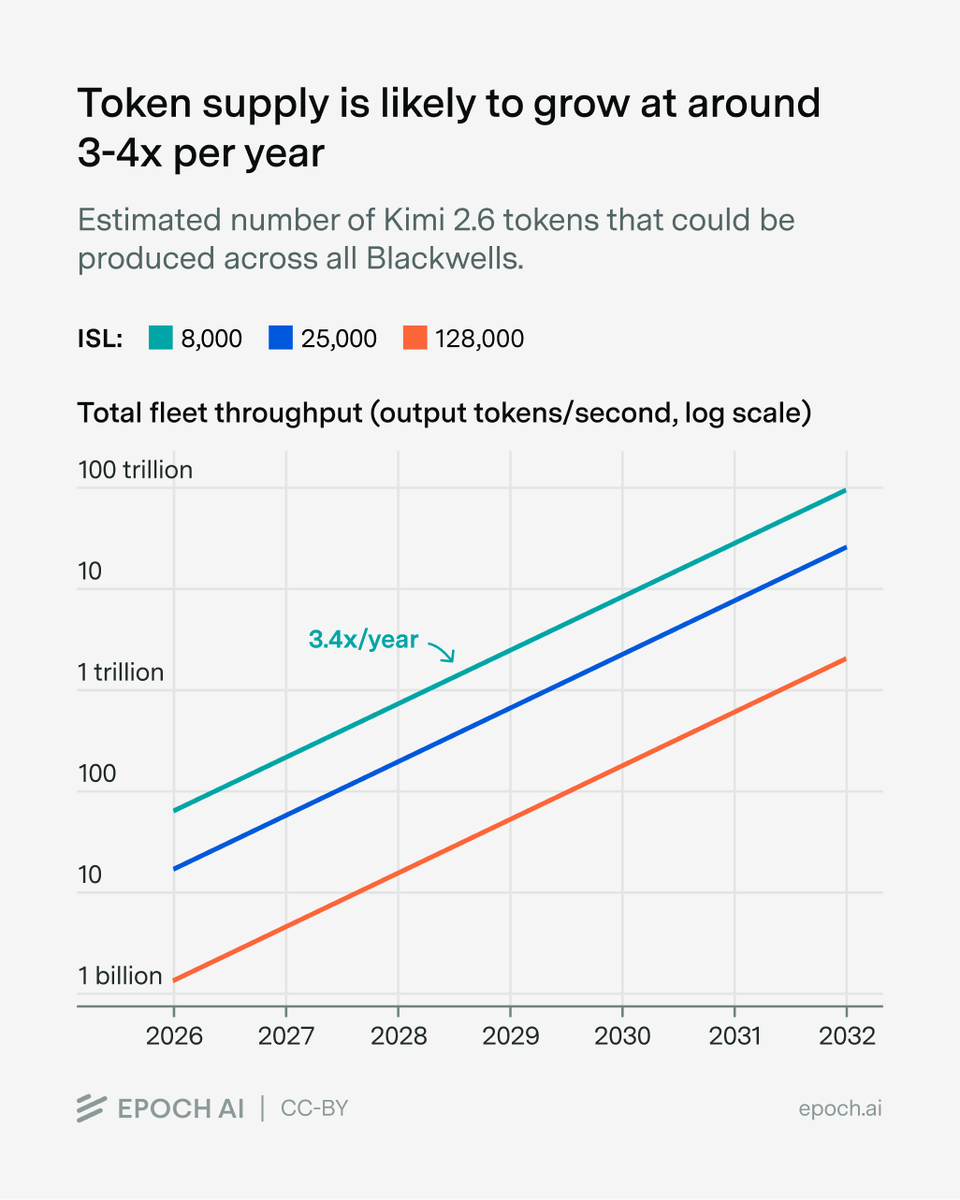
Are we nearing a compute crunch?
In our latest Gradient Update, @luke__emberson and @Jsevillamol estimate how many tokens all the Blackwell chips on Earth could serve, and compare this to total token demand. Direct comparisons are difficult, but it appears demand is growing much faster than supply.
We now know that with an appropriate harness both Mythos and GPT-5.5 can reproduce what our internal model did in one-shot for the unit distance problem. Clearly there is an insane overhang of capabilities with this generation of models, and no ceiling in sight for what scientific advances they can bring. You can go and try to discover new things with 5.5 right now!
A large MoE model may be wasting half its expert compute on tokens that barely need expert help.
In this paper 50% of expert computation removed, with almost no loss in accuracy.
This makes already-trained MoE models like Qwen3 and GLM stop calling half their experts when a token is too easy to need them.
Zero-Expert Self-Distillation Adaptation (ZEDA), a low-cost framework that transforms post-trained static MoE models into efficient dynamic ones.
Shows that many MoE tokens do not need real experts, only permission to skip them.
That sounds like a small routing trick, but it changes the economics of deployed language models.
Standard MoE models already avoid using every parameter, yet they still spend the same expert budget on every token.
ZEDA adds a strange new option to the router: experts that output exactly nothing.
When the model routes a token to one of these zero experts, it is not making the model dumber; it is admitting that this token does not need another expensive transformation.
The clever part is not the dummy expert, but the adaptation method.
Instead of retraining the model from scratch, the original MoE becomes a frozen teacher, while the new dynamic version learns when it can safely skip work.
Across Qwen3-30B-A3B and GLM-4.7-Flash, the result is roughly half the expert computation removed, with only marginal average accuracy loss and about 20% real inference speedup.
The deeper finding is: compute use did not simply track task difficulty.
The model spent more expert budget where uncertainty or teacher-student disagreement rose, while structured code and math fragments often needed less.
That makes ZEDA feel less like pruning and more like attention to computational doubt.
----
Paper Link – arxiv. org/abs/2605.18643
Paper Title: "Post-Trained MoE Can Skip Half Experts via Self-Distillation"
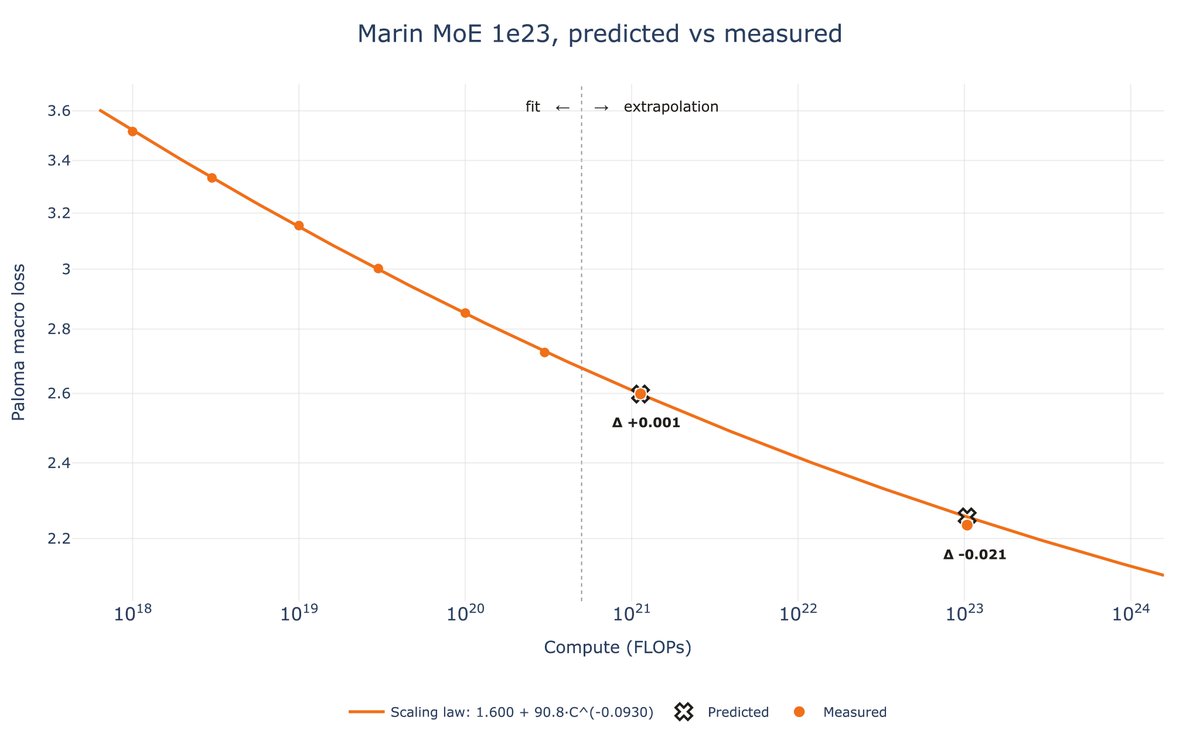
Not only do we want to train a good model, we want to know it'll be good before we even start training.
About a month ago, the Marin team launched a 129B (16B active) 1e23 FLOPs MoE run and preregistered a loss of 2.252. The run finished this past week and landed at 2.234.
https://t.co/OptaVa7jIO
I redid the multi-digit multiplication experiment, now with gpt-5.5. With medium reasoning and 7 samples each cell, it pretty much aced the test with 99.46% accuracy. The model had no tools to call and had to rely on its reasoning. Can it go further? (1/4)
After some mathematical rewrite, turns out all of transformer is a series of gemm + epilogue. Given a few optimized primitives, LLMs (and novice humans) can write speed-of-light kernels for all transformer ops!
SITUATION ANALYSIS: Alongside the proof of the counterexample, OpenAI released a companion paper in which leading mathematicians from several fields share a human-verified version.
But the paper also includes the personal reflections of the mathematicians, and these range from general meditations on the role of AI in moving the field of mathematics forward to more specific thoughts on aspects of the counterexample and its significance.
We think these are just as interesting as the headline story, and have highlighted several below. The full paper, linked below, is worth reading.
Thomas Bloom (.@thomasfbloom)
"On examining the construction, it becomes more clear how people had missed this before – it requires the confluence of several different unlikely events: that a good mathematician is:
(1) spending significant time in thinking about the unit distance conjecture in the first place;
(2) seriously trying to disprove it, despite the oft-repeated belief of Erdős that it is true;
(3) believes that there is mileage in generalising the original construction to other number fields, and so is willing to expend significant time in exploring such constructions; and
(4) sufficiently familiar with the relevant parts of class field theory to recognise that the appropriately phrased question about infinite towers of number fields with appropriate parameters can be solved using existing theory."
W T Gowers (.@wtgowers)
After reflecting on methods for estimating the difficulty of mathematics problems that AI models are able to solve or assist with, and concluding that this particular counterexample was relatively low difficulty:
"My current bet is that progress in AI mathematics is *not* about to reach a plateau, and that we will soon see AI solutions to many problems that we will find hard to explain away as easier than expected with hindsight."
Melanie Matchett Wood (Professor of Mathematics at Harvard University)
"I believe if the level and type of human expertise that is represented on this note had been assembled to find a counterexample to this conjecture a month ago, and those people put in similar amounts of time working on it than they did to reading and thinking about Chat GPT’s solution, the mathematicians would have found a counterexample."
"We can all be reminded by this development of how frequently interesting and powerful things happen mathematically when one applies ideas from one field to another, and think about how AI can help us find more cross-field applications."
MoEs are everywhere, but the design space is confusing: total vs active experts? expert size? shared experts? routing? token dropping?
We train >2000 MoE LMs 🫠 to investigate and bring you:
📄🔪🍰 Slicing and Dicing MoEs
Tl;dr: it's all about expert size and count
[1/9]































![ccui42's tweet photo. Introducing Multi-Head LatentMoE 🚀
Turns out, making NVIDIA's LatentMoE [1] multi-head further unlocks O(1), balanced, and deterministic communication.
Our insight: Head Parallel; Move routing from before all-to-all to after. Token duplication happens locally. Always uniform, always deterministic.
It works orthogonally to EP as a new dimension of parallelism. For example, use HP for intra-cluster all-to-all as a highway, then use EP locally.
We propose FlashAttention-like routing and expert computation, both exact, IO-aware, and constant memory. This is to handle the increased number of sub-tokens.
Results:
- We replicate LatentMoE and confirm it is indeed faster than MoE, with matching model performance. (See Design Principle IV in [1])
- Up to 1.61x faster training than MoE+EP with identical model performance.
- Higher model performance while still 1.11x faster with doubled granularity.
📄 Paper: https://t.co/re5ludi0mB
💻 Code: https://t.co/8pHdtN3Z4i
[1] Elango et al., "LatentMoE: Toward Optimal Accuracy per FLOP and Parameter in Mixture of Experts", 2026. https://t.co/cNmJ8tchTF](https://pbs.twimg.com/media/HAnJgGoacAMXAB_.jpg)







![margs_li's tweet photo. MoEs are everywhere, but the design space is confusing: total vs active experts? expert size? shared experts? routing? token dropping?
We train >2000 MoE LMs 🫠 to investigate and bring you:
📄🔪🍰 Slicing and Dicing MoEs
Tl;dr: it's all about expert size and count
[1/9] https://t.co/zROgT2TAE3](https://pbs.twimg.com/media/HImkC_WaoAE8OeK.png)




















