Assistant Professor with the Electronic Engineering Faculty of the University of Brasília @ Gama. Signal/Image Processing & Compression; BCI/ML; Biomedical Eng.
Why KV cache is one of the main reasons LLMs are fast?
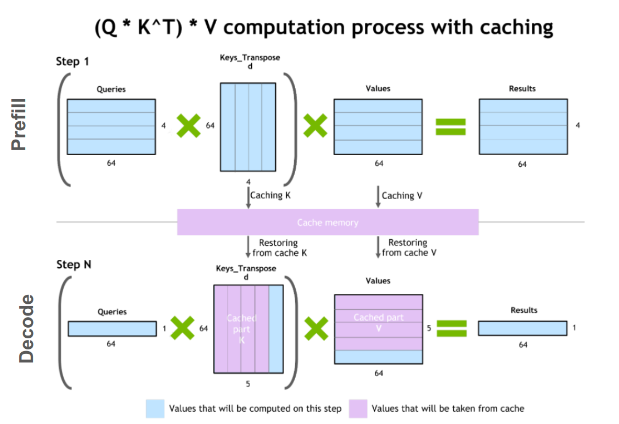
KV cache is what connects attention mechanism with generation stage of autoregressive models.
These models generate text token by token, but each new token still attends to all previous ones.
→ To optimize decode phase, models store previously computed key and value vectors in a KV cache.
→ During generation, they only compute new Q/K/V states for the latest token and attend over cached past representations.
Without KV cache, the model would recompute keys and values for the entire sequence at every step (like token 501 recomputes tokens 1–500), that's very slow.
▪️ But the tradeoff of KV cache is memory, because it grows with sequence length, batch size, layers, and attention heads.
That’s why so much research today targets KV efficiency and memory optimization. For example:
- Upgrading attention mechanism, since it influences how KV cache is formed. Use more advanced attention like CompactAttention, MHA, MLA, etc. based on your needs.
- Improve memory management. System needs to identify what to store long-term or keep local, when to summarize, and when to trim.
You can learn more about KV cache + attention here: https://t.co/YlRyxCM9Tj
And how they fit into the full LLM inference pipeline here: https://t.co/tKjX8Wvdkp
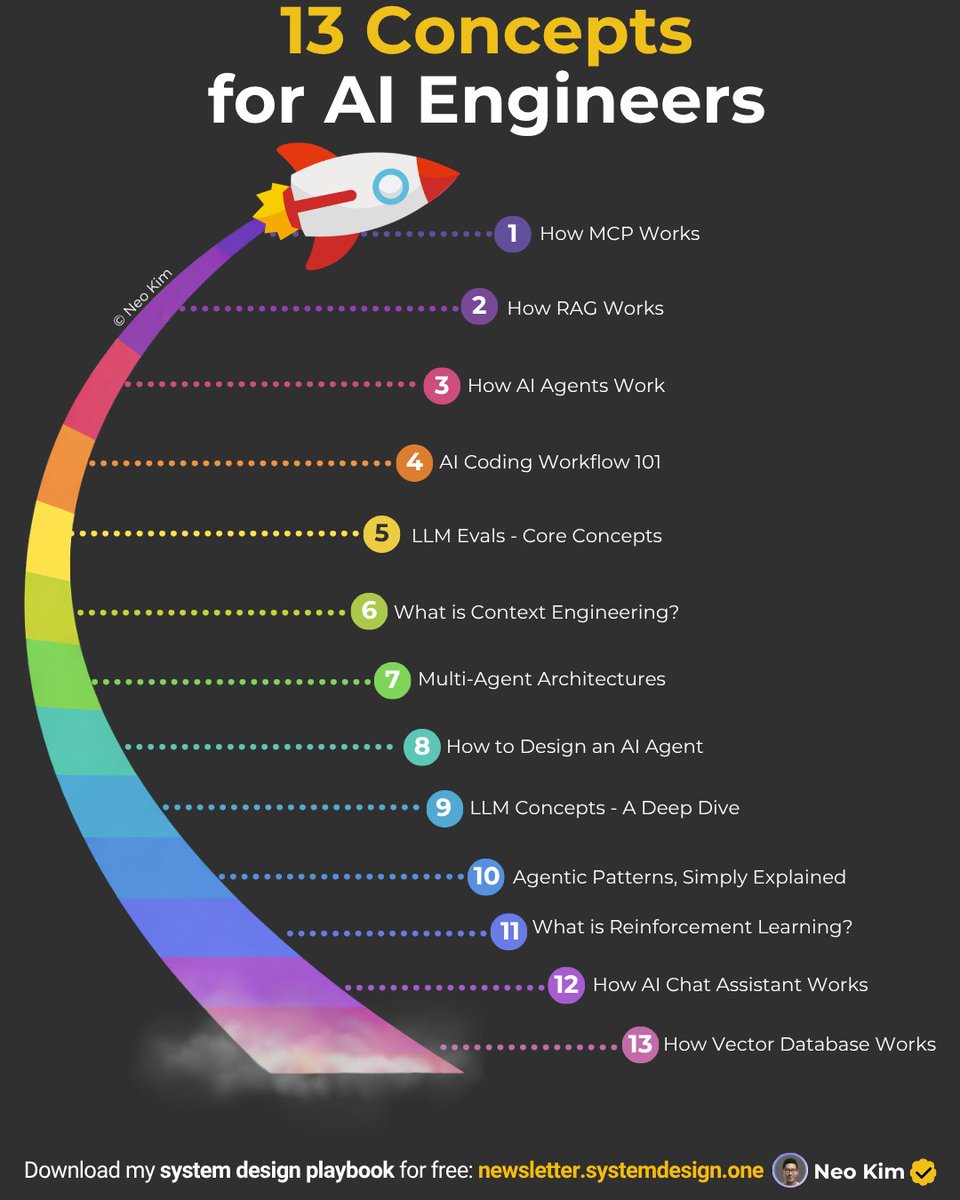
If you're serious about AI engineering (in 2026), then learn these 13 concepts:
1 How Vector Database Works
→ https://t.co/FVxan8xHH3
2 How RAG Works
→ https://t.co/cGmunPTUlb
3 Design Personal Chat Assistant
→ https://t.co/nNWq3onTnW
4 LLM Concepts - A Deep Dive
→ https://t.co/5lCKxq2g4N
5 How to Design an AI Agent
→ https://t.co/JvnPd9773A
6 What is Reinforcement Learning
→ https://t.co/AVpl9j1oit
7 LLM Evals 101
→ https://t.co/nv3Ol8W53p
8 Context Engineering 101
→ https://t.co/OMkiZhkODL
9 AI Coding Workflow 101
→ https://t.co/paIf9ksIU9
10 Agentic Patterns, Simply Explained
→ https://t.co/8YdBBWvTj1
11 How AI Agents Work
→ https://t.co/tk3zkCjRvg
12 Multi-Agent Architectures, Clearly Explained
→ https://t.co/rS5QQS7Jln
13 How MCP Works
→ https://t.co/wgf8gHnnkn
What else should make this list?
===
👋 PS - Want my System Design Playbook (for Free)?
Join my newsletter with 200K+ software engineers now:
→ https://t.co/ByOFTtOihX
===
💾 Save now & repost to help others learn AI engineering.
👤 Follow @systemdesignone + turn on notifications.
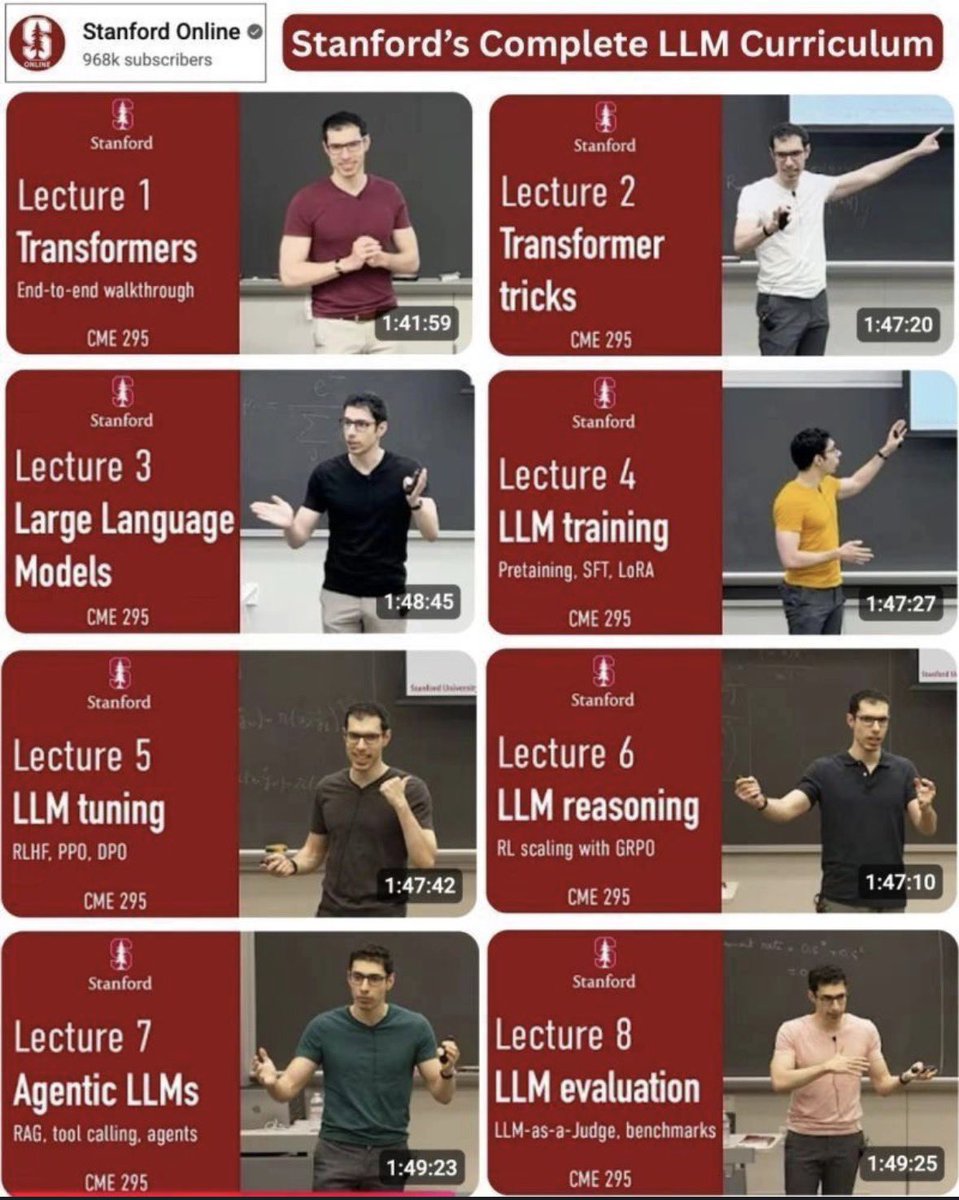
Stanford’s 2025 LLM course has 9 lectures covering all you need to start from scratch: architecture, training, fine tuning, reasoning, evaluation, and current trends.
https://t.co/NVBxGR6V3I
Stop wasting hours trying to learn AI. 📘📚
I have already done it for you.
With one list. Zero confusion. And no fluff
📹 Videos:
1. LLM Introduction: https://t.co/YkuDFVmW9e
2. LLMs from Scratch: https://t.co/u3kSz5SGuJ
3. Agentic AI Overview (Stanford): https://t.co/W6rzVHGSgC
4. Building and Evaluating Agents: https://t.co/sEl8vVax3F
5. Building Effective Agents: https://t.co/c7fD4aWFYO
6. Building Agents with MCP: https://t.co/GlMdR6htgA
7. Building an Agent from Scratch: https://t.co/kUQ9jPuI0R
8. Philo Agents: https://t.co/8JHvqw0DKn
🗂️ Repos
1. GenAI Agents: https://t.co/cyHPvOAjlK
2. Microsoft's AI Agents for Beginners: https://t.co/zFJAN74JQe
3. Prompt Engineering Guide: https://t.co/liUshX2XsP
4. Hands-On Large Language Models: https://t.co/TXFhbiboZY
5. AI Agents for Beginners: https://t.co/zFJAN74JQe
6. GenAI Agentshttps://lnkd.in/dEt72MEy
7. Made with ML: https://t.co/lkXP6itwK0
8. Hands-On AI Engineering:https://t.co/zB8EEctE4Y
9. Awesome Generative AI Guide: https://t.co/lF7CuIQHRw
10. Designing Machine Learning Systems: https://t.co/XlYUZYOoVi
11. Machine Learning for Beginners from Microsoft: https://t.co/hF5UzZoMJB
12. LLM Course: https://t.co/4tLAwy8fOQ
🗺️ Guides
1. Google's Agent Whitepaper: https://t.co/0OEKVLgF34
2. Google's Agent Companion: https://t.co/r0Dxe4VvDO
3. Building Effective Agents by Anthropic: https://t.co/I0ZyuwiOS3.
4. Claude Code Best Agentic Coding practices: https://t.co/HIBC2TwwAP
5. OpenAI's Practical Guide to Building Agents: https://t.co/1I8n0wnjHQ
📚Books:
1. Understanding Deep Learning: https://t.co/XEzhyAcWbq
2. Building an LLM from Scratch: https://t.co/4sZmBnHPEg
3. The LLM Engineering Handbook: https://t.co/IkAYNFkVNI
4. AI Agents: The Definitive Guide - Nicole Koenigstein: https://t.co/KsFnET47hx
5. Building Applications with AI Agents - Michael Albada: https://t.co/lJhMLtsLql
6. AI Agents with MCP - Kyle Stratis: https://t.co/C2lhD8uTDL
7. AI Engineering: https://t.co/34EyUiIVMv
📜 Papers
1. ReAct: https://t.co/kfQ8tWysne
2. Generative Agents: https://t.co/wbfqXq8KZK.
3. Toolformer: https://t.co/OQ7m49YWls
4. Chain-of-Thought Prompting: https://t.co/XeNgLQdTIL.
🧑🏫 Courses:
1. HuggingFace's Agent Course: https://t.co/tUZyPEGhni
2. MCP with Anthropic: https://t.co/wx1DAIWis0
3. Building Vector Databases with Pinecone: https://t.co/8XsQzDstTB
4. Vector Databases from Embeddings to Apps: https://t.co/9n6DvZGTMN
5. Agent Memory: https://t.co/OxFAaM0fp7
Repost for your network ♻️
Ollama is a powerful open source tool that lets you run LLMs right in your local environment.
Local LLMs give you more control, privacy, and customization options than those run in the cloud.
This course teaches you how Ollama works by building three projects.
https://t.co/sHFpSh0Wzb
I'm Boris and I created Claude Code. Lots of people have asked how I use Claude Code, so I wanted to show off my setup a bit.
My setup might be surprisingly vanilla! Claude Code works great out of the box, so I personally don't customize it much. There is no one correct way to use Claude Code: we intentionally build it in a way that you can use it, customize it, and hack it however you like. Each person on the Claude Code team uses it very differently.
So, here goes.
Vision Transformers have completely changed the field of computer vision.
But where did they come from? What came before? Why are they so important?
In this course, you'll learn all about the history of Deep Learning vision architectures from early ones like LaNet & AlexNet all the way to ViT.
https://t.co/dKDe2In1dD
At MIT, I learned about RNNs in my NLP class with Prof. Michael Collins. He built a model from my keystrokes to predict who I was. To me, it felt like a magic box. Years later, when I had to teach RNNs, I forced myself to go inside the box. ⬇️ Download: https://t.co/pD5gFhOrpr
First, with a tiny example on paper by hand ✍️.
Then, a slightly larger one in Excel.
That’s when it finally clicked:
👉 The weights are reused (weight matrices on the left side)
👉 The hidden states are passed down (H's)
When I built it by hand and saw everything visually, it clicked, just math you can actually trace.
Now I try to give others the same “aha!” moment I had.
⬇️ Download Excel: https://t.co/pD5gFhOrpr
Code generation gets smarter when models can explore multiple solutions and learn from their mistakes with Tree-structured reasoning
This paper introduces a framework called Outcome-Refining Process Supervision (ORPS) that helps LLMs write better code by treating outcome refinement as a supervised process, using execution signals and tree-structured exploration.
-----
🤖 Original Problem:
LLMs struggle with complex programming tasks requiring deep algorithmic reasoning. Current approaches using process supervision need expensive training data and suffer from unreliable evaluation.
-----
🔧 Solution in this Paper:
→ ORPS treats outcome refinement itself as the process to supervise, combining theoretical understanding with practical implementation.
→ Uses tree-structured exploration instead of linear Chain-of-Thought, maintaining multiple solution paths simultaneously.
→ Leverages concrete execution signals to ground the supervision without needing specially trained reward models.
→ Implements self-critic mechanism where model acts as both programmer and critic, providing detailed analysis before making judgments.
-----
💡 Key Insights:
→ Providing sufficient reasoning space is more crucial than model size for complex programming
→ Combining execution feedback with self-critique creates more reliable verification than traditional reward models
→ Tree-structured exploration enables discovery of fundamentally different algorithmic strategies
-----
📊 Results:
→ Achieved 26.9% average increase in correctness across 3 datasets and 5 models
→ Reduced running time by 42.2% on average
→ Even smaller models like Qwen-7B achieved 80% Pass@1 when given sufficient reasoning space
MASSIVE Dataset just released. Common Corpus provides 2 trillion tokens of clean, permissibly licensed data across 30+ languages for training LLMs.
First fully-documented training dataset that doesn't rely on copyrighted or web-scraped content.
🔍 What is Common Corpus
- 2 trillion tokens of permissibly licensed multilingual content
- Tackles the assumption that LLM training requires copyrighted data
- All data sources are documented with provenance information
- Compliant with EU AI Act regulations
📚 Main collections in Common Corpus?
- OpenCulture: 927B tokens of public domain books, newspapers, Wikisource
- OpenGovernment: 388B tokens of financial/legal documents
- OpenSource: 335B tokens of high-quality GitHub code
- OpenScience: 222B tokens of academic content
- OpenWeb: 132B tokens from Wikipedia, YouTube Commons, Stack Exchange
🌍 Diversity of the language coverage
- English: 808B tokens
- French: 266B tokens
- German: 112B tokens
- Spanish: 46B tokens
- 30+ languages with 1B+ tokens each
- Enables AI development beyond English-speaking regions
🛠️ Innovations while data processing?
- OCRonos-Vintage: 124M parameter model for fixing historical text errors
- Multilingual toxicity detection system
- Vision-language models for preserving PDF document structure
- ArmoRM for code quality evaluation
- Region-specific PII detection for GDPR compliance
We want to make it easier for more people to build with Llama — so today we’re releasing new quantized versions of Llama 3.2 1B & 3B that deliver up to 2-4x increases in inference speed and, on average, 56% reduction in model size, and 41% reduction in memory footprint.
Details on our new quantized Llama 3.2 on-device models ➡️
https://t.co/ea32Takvjh
While quantized models have existed in the community before, these approaches often came at a tradeoff between performance and accuracy. To solve this, we Quantization-Aware Training with LoRA adaptors as opposed to only post-processing. As a result, our new models offer a reduced memory footprint, faster on-device inference, accuracy and portability — while maintaining quality and safety for developers to deploy on resource-constrained devices.
The new models can be downloaded now from Meta and on @huggingface.
I told AI to complete a CS assignment from Stanford's Advanced Data Structures (CS166) — and it just.. did it!
It read the pdf, wrote a Binomial Heap in C++, wrote tests + makefile, ran the tests, and wrote up a final pdf!
Would've taken a student ~20hrs.
Took AI ~3mins.