A wonderfully pragmatic look at the US/China AI race. Very unrealistic & dangerous to project "the next 12 months" are an all-or-nothing bet on the future of the world.
https://t.co/3ELCPFhl9g
When Audience Asked Richard Feynman,
Do you think there will ever be a machine that will think like human beings and be more intelligent than human beings?
The Jensen Huang episode.
0:00:00 – Is Nvidia’s biggest moat its grip on scarce supply chains?
0:16:25 – Will TPUs break Nvidia’s hold on AI compute?
0:41:06 – Why doesn’t Nvidia become a hyperscaler?
0:57:36 – Should we be selling AI chips to China?
1:35:06 – Why doesn’t Nvidia make multiple different chip architectures?
Look up Dwarkesh Podcast on YouTube, Apple Podcasts, Spotify, etc. Enjoy!
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
Ten years ago, AlphaGo’s legendary match in Seoul heralded the start of the modern era in AI. Its famous ‘Move 37’ signaled to us that AI techniques were ready to tackle real-world problems in areas like science - and ideas inspired by these methods are critical to building AGI
Chess players have over 15 years of AI experience
We call them engines (like Stockfish or Leela) but it’s proper AI models under the hood.
We run them locally or in the cloud, depending on the needs and depth.
We learnt what to do when we wait for their results.
We were worried when they appeared that chess would be dead. Quite the opposite happened, chess boomed since then with many new job roles.
The overall quality of chess skills improved and more players are now strong.
AI didn’t kill our chess creativity - it improved it.
We treat AI as oracles. It’s rare to argue with engine evaluation.
But, we learnt when to follow AI recommendation and when to skip it as it requires “non-human play”.
The best approach is to use AI to find human playable ideas and drop the “computer lines”.
As a programmer and a chess player (2500 on chesscom) I remain optimistic.
Happy birthday to Ray Kurzweil '70, an innovator in speech & text recognition. He's also a leading proponent of “the singularity.”
Photo v/The Academy of Achievement
AGI is not coming.
We are nowhere near AGI. What we have today is inference, not learning.
Models get trained once on huge fixed datasets, then frozen. You ask questions, they remix patterns they already saw. Nothing updates. Nothing sticks. Talking to the model does not make it smarter. It does not learn from you. Ever.
Learning is still slow, expensive - and offline.
Look at self driving. You drive around a pothole, make a U turn, and come back. The car’s AI does not learn that you just solved that exact problem. It reacts the same way every time using sensors and rules. Do this 20 times a day and it still has zero memory that the pothole exists. It just re sees it. That is why edge cases never die. There is no local learning. No accumulation.
No 'oh yeah, I’ve seen this before'
LLMs work the same way. Tell it your name and it does not remember. The only reason it looks like memory is because scaffolding keeps shoving your name back into the prompt every time and sanitizing the output.
The model itself has no idea who you are and cannot learn from interaction. It is structurally incapable.
And the scaffolding is the worst part. It is pure duct tape. Just prompts on prompts on prompts around a frozen model. When something breaks, nobody fixes learning. They add another layer. Another rule. Another retry. Another evaluator model judging the first model.
So you end up with systems that are insanely complex but mentally shallow. Debugging is hell because behavior comes from hack interactions, not a learnable core. Tiny prompt tweaks cause wild behavior shifts. Latency goes up. Costs go up. Reliability goes down. None of this compounds into intelligence. It just hides the cracks.
Until we have real persistent learning and real memory inside the system, there is no AGI.
LLMs are not built for this. You cannot prompt your way out of it. You need a totally different architecture. Yann LeCun is right.
And even then, what architecture can actually learn online, store memory, and stay stable on today’s hardware?
Best case, maybe 5-10 yrs.
Right now it is all inference. It looks magical, but the emperor has no clothes. A lot of people see it. Almost nobody says it out loud.
"Before Transformers, RNNs were the thing. These were a big breakthrough. Suddenly, everyone started to work on improving RNNs. But the results were always these slight modifications on the same architecture, like putting the gate in a different spot, with improvements to 1.26, 1.25 bits per character on language modeling."
"After the Transformer, when we applied very deep decoder-only Transformers to the same task, we immediately got 1.1 bits per character. So all that research on RNNs suddenly seemed a waste of time".
"We're currently in the same situation where a lot of papers are taking the same architecture (Transformer) and making these endless tweaks, in a local minimum, and we might be wasting time in exactly the same way."
- Llion Jones, co-author of the Transformer on @MLStreetTalk
This is #NVIDIARubin.
Six new chips designed to deliver one incredible AI supercomputer.
Built with extreme co-design across compute, networking, and software, Rubin sets a new standard for building and deploying the world’s most advanced AI systems at the lowest possible cost.
Read More: https://t.co/ZzmSOrd4fp
#CES2026
‘The Thinking Game’ documentary has just passed 200M views on YouTube in just 4 weeks! 🤯Perfect holiday viewing if you’re interested in a behind-the-scenes look at how an AGI lab works, or what goes into making a Nobel Prize winning project like AlphaFold happen.🧬🚀
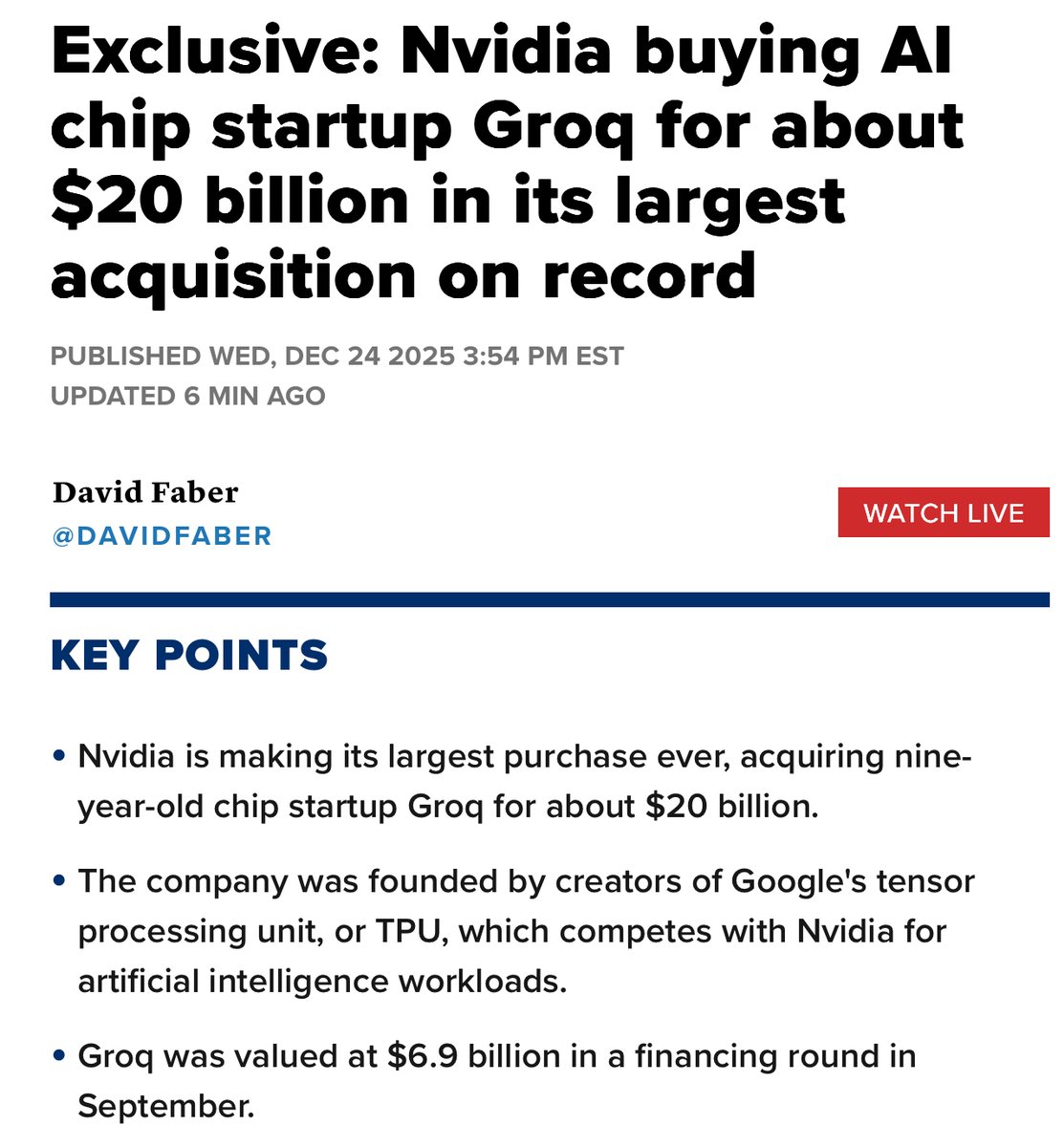
Nvidia acquiring Groq for $20B is a big deal.
Groq chips are insanely fast at inference, sometimes 10x GPUs. The trick is to put model weights in SRAM instead of HBM to trade memory capacity for speed.
Its $/token may lose to GPUs, but for long-wait inference on models like GPT-5.2 Pro, speed matters.
If I were Sam Altman, I’d buy it. $20B is cheap.
Jensen made the right call.
Yann is just plain incorrect here, he’s confusing general intelligence with universal intelligence.
Brains are the most exquisite and complex phenomena we know of in the universe (so far), and they are in fact extremely general.
Obviously one can’t circumvent the no free lunch theorem so in a practical and finite system there always has to be some degree of specialisation around the target distribution that is being learnt.
But the point about generality is that in theory, in the Turing Machine sense, the architecture of such a general system is capable of learning anything computable given enough time and memory (and data), and the human brain (and AI foundation models) are approximate Turing Machines.
Finally, with regards to Yann's comments about chess players, it’s amazing that humans could have invented chess in the first place (and all the other aspects of modern civilization from science to 747s!) let alone get as brilliant at it as someone like Magnus. He may not be strictly optimal (after all he has finite memory and limited time to make a decision) but it’s incredible what he and we can do with our brains given they were evolved for hunter gathering.
I doubt that anything resembling genuine AGI is within reach of current AI tools—Terrence Tao
“Perhaps this can be resolved by the realization that while cleverness and intelligence are somewhat correlated traits for humans, they are much more decoupled for AI tools (which are often optimized for cleverness), and viewing the current generation of such tools primarily as a stochastic generator of sometimes clever - and often useful - thoughts and outputs may be a more productive perspective when trying to use them to solve difficult problems.”
On the latest Radical Talks podcast: @GeoffreyHinton X @JeffDean - a friendship that defined modern AI as breakthrough theories met massive scale. Recorded at #NeurIPS2025, Radical Co-Founder @JordanJacobs10 sits down with these two icons of AI to discuss one of history’s most productive collaborations.
Reuters is reporting that China's classified EUV project has reverse engineered and successfully built a prototype EUV machine with the help of former ASML engineers.
My new blog post discusses the physical reality of computation and why this means we will not see AGI or any meaningful superintelligence: https://t.co/jsAKQ6T3gC
I’ve publicly held the same prediction since 2009: there’s a 50% chance we’ll see #AGI by 2028.
I sat down with @FryRsquared to discuss why I haven’t changed my mind, and how we need to prepare before we get there.
Catch the full conversation here: https://t.co/AenO9fbTAh