"Transformers" by Daniel Jurafsky and James H. Martin is one of the clearest and most mathematically grounded introductions to the Transformer architecture I have ever read.
Chapter 8 introduces the Transformer as the standard architecture behind modern large language models. What makes this chapter particularly interesting is its step-by-step presentation of the underlying mechanisms: contextual embeddings, self-attention, query, key and value vectors, scaled dot-product attention, multi-head attention, residual streams, feedforward layers, layer normalization, masking, and the parallel matrix formulation of attention.
In particular, the treatment of attention as a weighted sum of contextual representations is especially valuable. The chapter first develops an intuitive, simplified view of attention and then gradually derives the full formulation using the Q, K, and V matrices. This approach makes it easier to understand what is actually happening inside the architecture from an algebraic and matrix-based perspective, rather than simply viewing the usual block diagrams.
I think it is an excellent resource for anyone interested in understanding how Transformers work from linguistic, mathematical, and computational perspectives.
https://t.co/3fitdPy6Fv
"Graph Theory" by Reinhard Diestel is one of the most complete introductions to modern graph theory. It begins with the fundamentals of graphs, paths, trees, and connectivity, and progressively develops more advanced topics including planar graphs, colouring, flows, Ramsey theory, random graphs, and graph minors.
The writing is rigorous and mathematically precise, yet surprisingly clear and enjoyable to read. Although the book is written from a pure mathematics perspective, many of the ideas it develops also underpin important areas of computer science, from database systems and network analysis to combinatorial optimisation.
I think it is an excellent resource for anyone who wants to build a solid understanding of graph theory and keep a reliable reference close at hand.
❗️UPDATE: As @naivebayesian kindly pointed out, please refer to the author’s website.
A free preview of the book is available here: https://t.co/P5DWtuyYDY
For the standard edition, the book should be purchased through the official page:
https://t.co/ViOr3Tr7Vw
This is NOT a sponsored post, just a correction that I believe is fair and important in order to properly recognise the author’s work.
I originally found the PDF link through Google and, I admit, I did not verify the source carefully enough. I will also try to contact the website hosting the PDF linked in my original post to ask whether its publication there was intentional or an error.
In the meantime, please refer only to the official links above and give the proper credit and recognition to the author. Thank you.
Nassim Taleb on a bet most people would take: 70% chance to win $1, 30% chance to lose $1 - should you bet?
His answer: in most cases no. Not because of risk aversion. Because it's a bad strategy in multi-period reality
Same Kelly Criterion math that powers Shannon's information theory - there's a sweet spot, and most behavioral finance papers ignore it
Bet too much and the law of large numbers ruins you. Bet too little and you leave returns on the table
this is what every quant learns before they touch capital
This is the rarest piece of HFT content on the internet - Robert Almgren walking through a real execution trade tick by tick
He's the co-founder of Quantitative Brokers and the man who wrote the Almgren-Chriss model - the standard execution algorithm used at Goldman, Citadel, Two Sigma
In this lecture he shows a live order from May 14 2018, every fill, every limit, every market reaction across 2 minutes and 40 seconds
The article above is that exact same thinking applied to Polymarket - measure your edge in bits before you place a single trade
Bookmark it & give it a watch tonight ↓
Jane Street's Head of Tech just open-sourced the code that generates $13B in profits
24 years inside a tier-1 fund to build this code
He spent 24 years learning what this 50-min video shows
bookmark - it will change the way you see trading systems
They quoted him $18,000. He opened Claude instead.
Same result. One afternoon. $20/month.
The gap between knowing how to use Claude and not knowing is worth $18,000.
This article below fixes that.
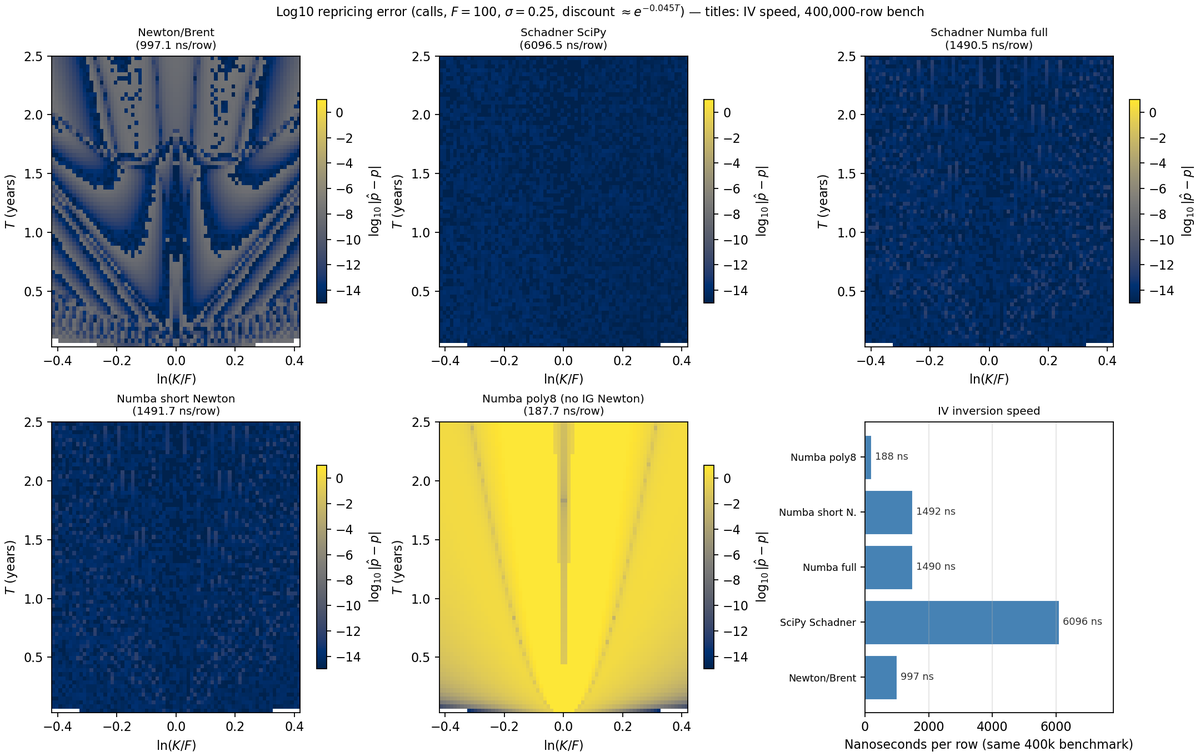
If you can live with a single basis point (0.01%) of volatility error, 188 ns per option on CPU is achievable.
Just use a polynomial approximation of the "expensive" inverse gaussian function.
With an 8th order polynomial, so 8 floating point coefficiences, this becomes a single operation on CPUs equiped with AVX512.
This is Python+Numba, obviously inline assembly intrinsincs would be even faster.
I used a movement sheet as a reference image to animate the dance using Seedance 2.0 + GPT image 2.0
GPT Image 2.0 prompt: [STYLE]
Monochrome grayscale illustration, 3D-rendered character, clean instructional reference sheet, white background, comic-style cell grid layout, technical diagram aesthetic.
[LAYOUT]
4×4 grid layout with a total of 16 panels. Each panel is separated by thin black border lines. Cells are numbered from 1 to 16, with consistent panel sizes.
[CHARACTER]
image1 (the same character appears consistently in all panels)
[PANEL STRUCTURE – per cell]
Top-left: bold number badge + English title text
Center: full-body character pose illustration
Bottom-left: English description text (3–4 lines)
Overlay: directional arrows indicating movement
[ARROWS / MOTION INDICATORS]
Curved arrows, straight arrows, and circular rotation indicators placed around the character to show motion flow and direction.
[RENDERING STYLE]
Highly detailed 3D sculpted style, soft studio lighting, subtle shadows, no color, grayscale shading, clean linework, game concept art quality.
[NEGATIVE]
No background scenery, no color tones, no additional characters, no complex background.
the AI to 3D pipeline in 2026:
- generate concept art (GPT image, nano banana)
- image to 3D mesh (hunyuan3D, tripo, meshy)
- cleanup + rig (meshyai, tripo, blender)
- auto-animate (mixamo)
start to game-ready character in one afternoon.
now do it with a capybara. $600 in prizes.
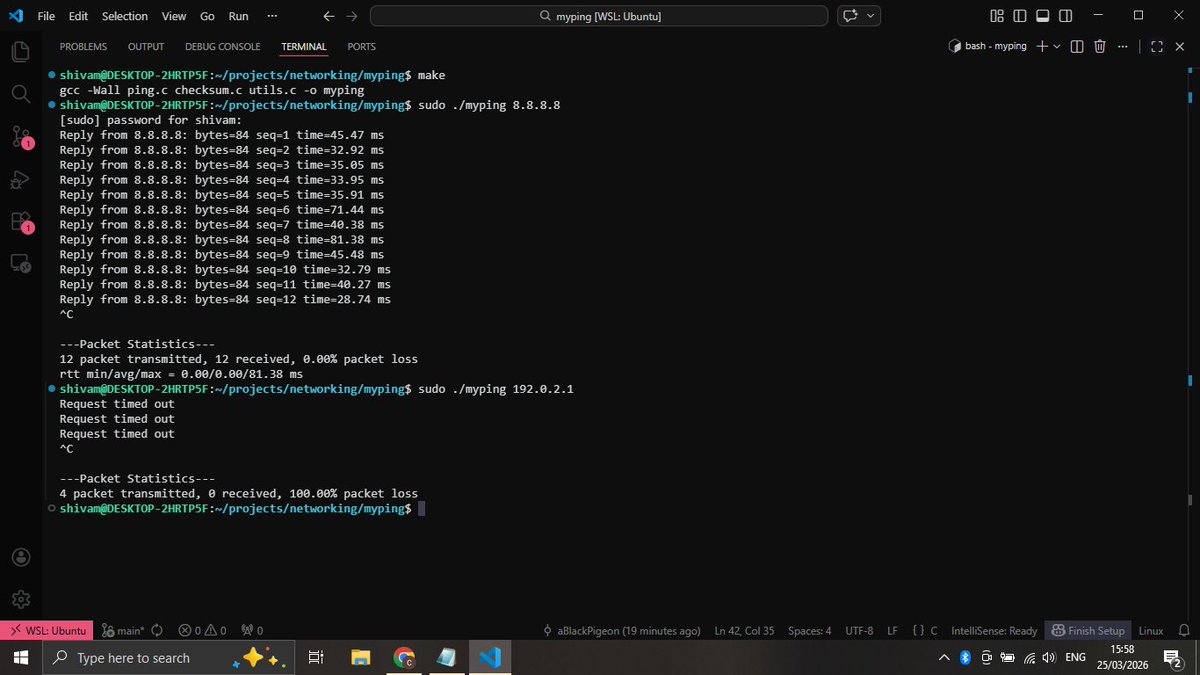
Asked GPT 5.4 Pro to make a 6 DOF robot gripper in https://t.co/QGpnVcxMaQ. Incredible progress, while still some mistakes (this is first attempt, no feedback)
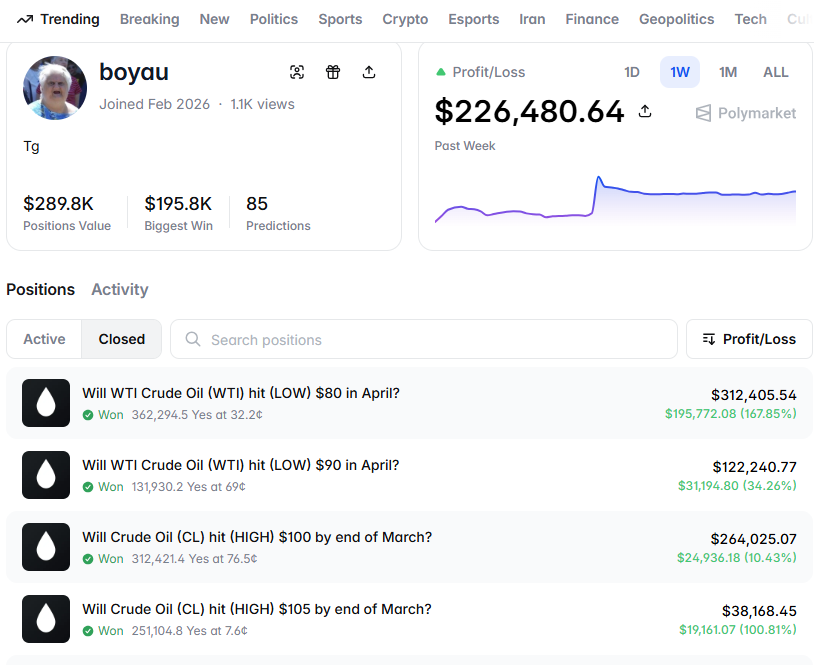
Ex-CERN QUANT applied quantum mechanics to the oil market on Polymarket
He trades exclusively oil and made $226K in a week
His Harmonic Oscillators model sees structure in the chaos:
â†|n⟩ = √(n+1)|n+1⟩ -- growth
â|n⟩ = √n|n-1⟩ -- decline
Eₙ = ℏω(n + ½) -- energy level
N̂|n⟩ = n|n⟩ -- particle number
Price discretization:
n(t) = ⌊(Rₜ - R_min)/ΔR · (N_L - 1)⌋
Rₜ = Σ r̃_τ/σ
Market events:
âₜ† = 1_{Δnₜ>0} · |Δnₜ| → buy
âₜ = 1_{Δnₜ<0} · |Δnₜ| → sell
Result:
probability density of the next move:
P(n,t) = 1/W · Σ δₙ,ₙτ
Oil volatility for everyone is risk, for him it's a signal
Check his profile: https://t.co/hUpKw1AalI
Claude can actually do CAD now in @Onshape
Here it worked for an hour and built a 4-part monitor arm, starting only from a sketch and description. The trick was to give it the tools to look at its own work.
Introducing: Jarvis Onshape MCP
Someone just built a Claude Code for electronics.
It's called Blueprint. Type what you want to build and it generates wiring diagrams, bills of materials, and step-by-step assembly guides for your Arduino or Raspberry Pi project.
100% Free.
Someone just built a desktop app that that generates 3D models from images and runs 100% locally.
It's called Modly. It runs entirely on your GPU, no cloud, no API bills. Just drop an image and get a 3D mesh.
100% Open Source.
My friend got laid off from a hedge fund last November
He was making $2.1M/year running their quant desk
Instead of applying to another fund - he took their entire strategy framework and rebuilt it on Polymarket
1300$ → 187,564$ in 3 weeks
Total cost: $200/month for Claude, $50/month VPS
He said: "The models I built for the fund work better on Polymarket, because on Wall Street you compete against other quants. On Polymarket you compete against guys who bet based on Twitter polls"
He rebuilt a 4-factor model in one weekend
Same math his fund ran on $800M AUM:
Momentum scoring: track 400+ markets, buy when a contract moves 10¢+ with rising volume
Mean reversion: when a contract overshoots 15¢+ in under 2 hours - fade it
Volatility regime detection: hidden Markov model classifies low-vol vs high-vol every hour. Switches strategy automatically
Correlation breakdown: 200+ market pairs monitored. When two normally correlated contracts decorrelate - one is wrong. Trade the lagging one.
All 4 run simultaneously
COPY HIM: https://t.co/K1eTdrTtpY
Portfolio optimizer combines the scores
Fractional Kelly sizing, max 5% per market, 15 concurrent positions
His fund's flagship returned 19% last year on $800M
His bot returned 144,000% in 3 weeks on $1300
He doesn't need to work anymore



































![oggii_0's tweet photo. I used a movement sheet as a reference image to animate the dance using Seedance 2.0 + GPT image 2.0
GPT Image 2.0 prompt: [STYLE]
Monochrome grayscale illustration, 3D-rendered character, clean instructional reference sheet, white background, comic-style cell grid layout, technical diagram aesthetic.
[LAYOUT]
4×4 grid layout with a total of 16 panels. Each panel is separated by thin black border lines. Cells are numbered from 1 to 16, with consistent panel sizes.
[CHARACTER]
image1 (the same character appears consistently in all panels)
[PANEL STRUCTURE – per cell]
Top-left: bold number badge + English title text
Center: full-body character pose illustration
Bottom-left: English description text (3–4 lines)
Overlay: directional arrows indicating movement
[ARROWS / MOTION INDICATORS]
Curved arrows, straight arrows, and circular rotation indicators placed around the character to show motion flow and direction.
[RENDERING STYLE]
Highly detailed 3D sculpted style, soft studio lighting, subtle shadows, no color, grayscale shading, clean linework, game concept art quality.
[NEGATIVE]
No background scenery, no color tones, no additional characters, no complex background.](https://pbs.twimg.com/media/HGzSvcnboAA_bjD.jpg)