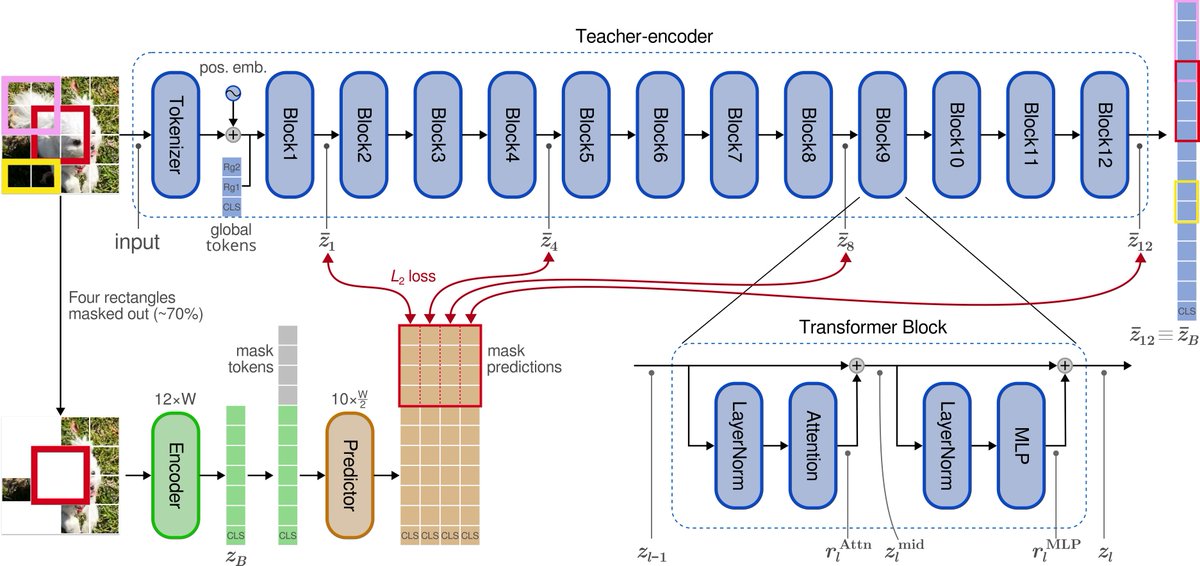
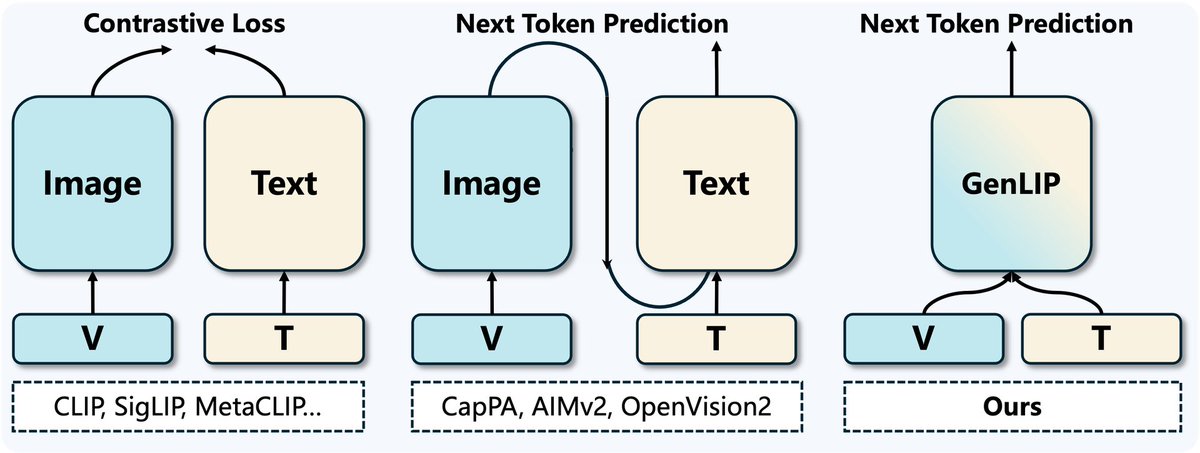
ByteDance released GenLIP: Let ViT Speak
A minimalist generative pretraining framework that trains Vision Transformers to predict language tokens directly from visual tokens using a single autoregressive objective, outperforming baselines with only 8B training samples.
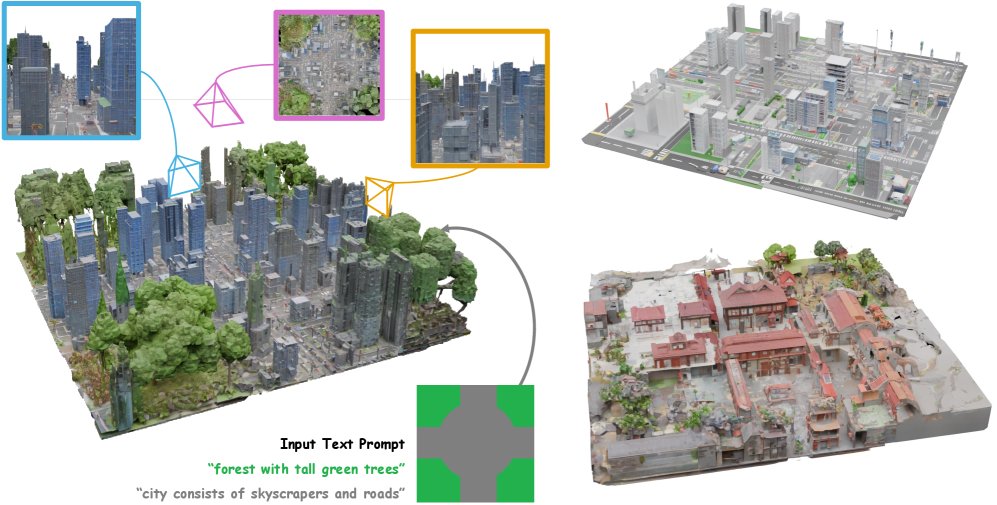
Map2World
Generate 3D worlds from any segment map and text.
This framework ensures global-scale consistency across expansive environments, while a detail enhancer network preserves fine-grained details without compromising scene coherence.
🌩️Introducing FlashQLA: high-performance linear attention kernels on TileLang.
⚡ 2-3× fwd, 2× bwd speedup.
💻 Purpose-built for agentic on your personal devices.
1. Gate-driven auto intra-card CP.
2. Hardware-friendly reformulation.
3. TileLang fused warp-specialized kernels.
Can LLMs generate diverse outputs for open-ended questions? Is it helpful if we ensemble outputs from multiple models? We study 18 LLMs on 4 datasets and find that no single model is best at generating diverse outputs 👇/ 🧵
It's time to systematically teach VLMs to see with synthetic images!
We built VisionFoundry, a simple but intuitive framework that generates synthetic image datasets from only a task name.
10k synthetic data → over +10% improvement on visual perception benchmarks 👀
Engineering PhDs (D.Eng) in China are getting wholesaled out now. Company employees take three months of classes per year and walk away with the degree straight from national policy.
The state no longer trusts universities to drive real tech progress. Tang boss built Zhipu AI and still didnt get academician status. They think enterprises do it better while unis just pump out low quality papers.
Unis are told to focus on talent cultivation and hand R&D to companies so freshmen might as well go straight to internships to learn by doing.
Yet good company labs still pump out papers and undergrads get thrown into research groups. Young profs chase papers and titles old ones chase grants and cash. Nobody gets judged on actual teaching.
Undergrad research only exists because everyone knows these profs wont teach so students chase the cutting edge themselves. Leadership wisdom at its finest write piles of equations no reviewer understands and keep managing upwards.
@ChujieZheng Where is my dear Qwen-Image 2.0???????????????????I heard from your staff that the model will be opened after lunar Chinese New Year, BUT WE ONLY SEE LIN'S LEAVE AFTER THE FESTIVAL!!!!
NEC held a welcoming ceremony for 800 newly-hired employees today. The check-in process was completed using the company's facial recognition technology.
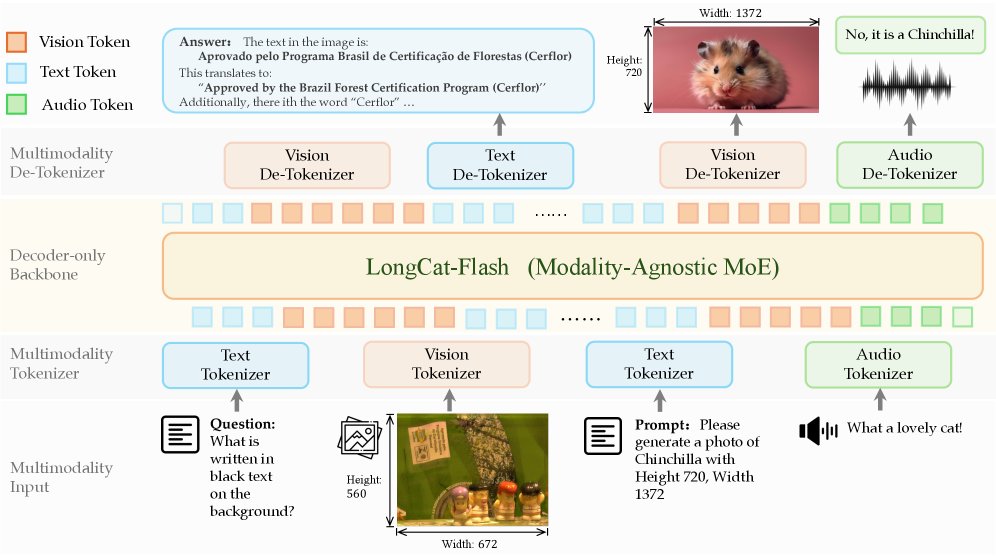
LongCat-Next
An open-source native multimodal model that lexicalizes vision, audio, and text into discrete tokens, enabling a pure autoregressive approach to understanding and generation.
The biggest reduction in KV cache memory comes not from quantization or MLA, but from latent compaction, along the sequence dimension.
More strong results coming soon with Attention Matching.
"Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?"
Self-distillation can make LLMs look smarter by producing shorter, more confident reasoning traces, but in math it often takes out the model's uncertainty and self-correction signals.
This can potentially badly hurt out-of-domain reasoning, so this paper suggests that better reasoning is not just about compression, but preserving useful "doubt".
New paper: "Self-Distillation of Hidden Layers for Self-Supervised Representation Learning"
We introduce Bootleg — a simple twist on I-JEPA/MAE that dramatically improves self-supervised representations.
The idea: MAE predicts pixels (stable but low-level). I-JEPA predicts final-layer embeddings (high-level but unstable). Bootleg bridges the two by predicting representations from multiple hidden layers of the teacher network — early, middle, and late — simultaneously.
Why it works: early layers provide stimulus-driven grounding that prevents collapse; deep layers provide semantic targets; and the information bottleneck of compressing all abstraction levels through masked patches forces the encoder to build richer representations.
The method is quite simple on top of I-JEPA: extract targets from evenly-spaced blocks, z-score and concatenate, widen the predictor's final layer. That's it.
Frozen probe results (no fine-tuning):
ImageNet-1K: 76.7% with ViT-B (+10pp over both I-JEPA and MAE)
iNaturalist-21: 58.3% with ViT-B (+17pp over I-JEPA, +15pp over MAE)
ADE20K segmentation: 30.9% mIoU with ViT-B (+11pp over I-JEPA, +6pp over MAE)
Cityscapes segmentation: 35.9% mIoU with ViT-B (+11pp over I-JEPA, +5pp over MAE)
Gains hold across ViT-S, ViT-B, and ViT-L.
Single-view, batch-size independent — no augmentation stack, no multi-crop, no contrastive loss, no large compute requirements.
Our study is just on images, but this change can be readily deployed to MAE and JEPA models across all domains.
https://t.co/PXJlRV4I6w
Beautiful paper, MetaClaw
Shows how a deployed LLM agent can keep learning on the job without stopping service.
The current problem is that most agents in production stay frozen, so they keep making the same mistakes as user needs shift and new kinds of tasks appear.
The paper’s fix is to split improvement into 2 loops: a fast loop that turns failures into reusable written skills right away, and a slow loop that later updates the model itself.
That split matters because the new skills help immediately with no downtime, while the slower training runs only when the user is away, using idle time like sleep, inactivity, or meetings.
The authors tested this on a 934-question benchmark built as 44 simulated workdays and on a separate automated research pipeline that has 23 stages.
They found that skills alone raised accuracy by up to 32% relative, and the full setup lifted Kimi-K2.5 from 21.4% to 40.6% while also improving robustness on the research pipeline by 18.3%.
What makes the paper matter is the pattern behind the gains: production agents can adapt fast now and learn deeper later, so they improve from real use instead of staying frozen.
"Foveated Diffusion: Efficient Spatially Adaptive Image and Video Generation"
This paper introduces the logic of human vision to diffusion models, where you generate full detail only when the viewer is looking, and becomes low detail in the periphery.
With this setup, you can get up to 2x faster image generation and 4x faster video generation with little perceptual drop!
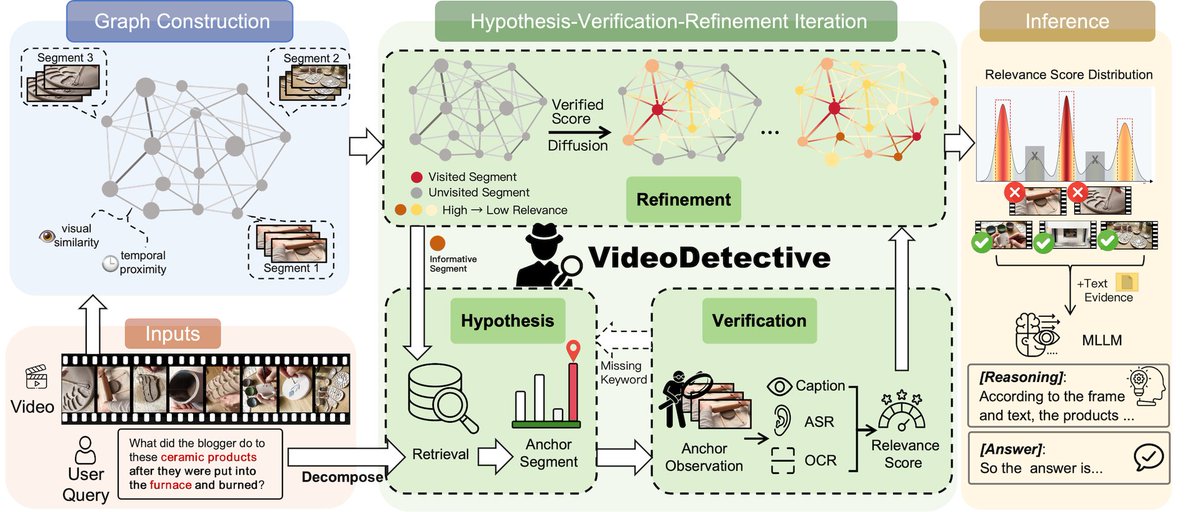
VideoDetective
See Less but Know More. A plug-and-play framework for long video understanding that hunts clues by integrating extrinsic query relevance with intrinsic video structure via spatio-temporal affinity graphs.
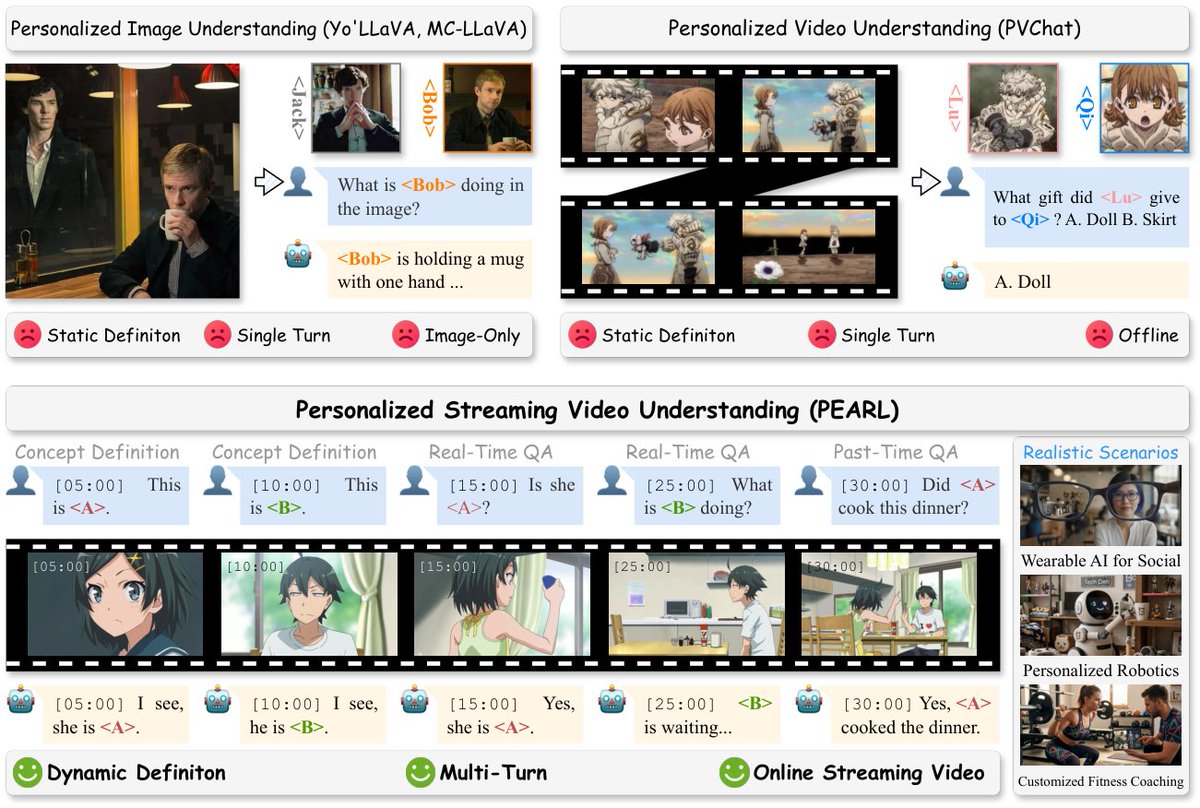
PEARL
A plug-and-play training-free framework for Personalized Streaming Video Understanding. Enables real-time recognition of user-defined concepts in continuous video streams with precise timestamp localization.