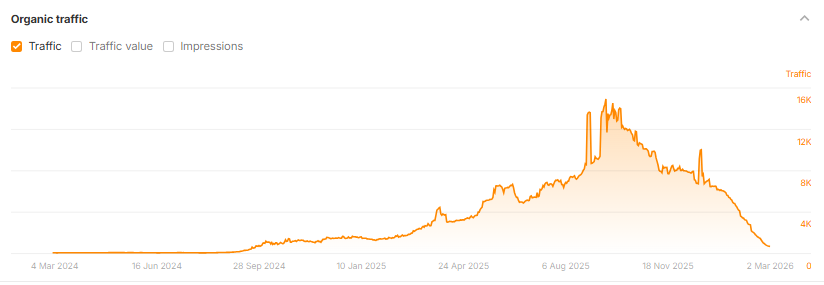
Very informative slide via Google's Danny Sullivan explaining the difference between "Commodity" vs "Non-Commodity" content
Google prefers the later
IMO, lots of evidence this is spot-on, not where Google is going in the future, but where it already is now
via @ChouinardJC
The LEAD search engineer at Google just dropped a brand new blog post that confirms something most SEOs have never even heard of...
Googlebot only fetches the first 2MB of your pages HTML = Everything after that cutoff doesn't exist to Google!!!
Not fetched, not rendered, not indexed.
And the Web Rendering Service is completely STATELESS - Meaning it clears local storage and session data between every request, so if your content depends on cookies or session state to render, Google can't see it.
External CSS and JS files are fetched SEPARATELY with their own 2MB limit per file, and PDFs get a 64mb limit.
So the structure and order of your code literally matters! And is why some CMSs are so much better out the box than others... Make sure you put your meta tags, title, canonicals, and structured data as HIGH as possible in the document. If they're below the 2MB cutoff, Google doesn't know they exist.
Most OnPage SEO guides never take any of this into account, but most OnPage is surface-level.
The real edge is understanding the infrastructure your content passes through before Google even evaluates it.
Google has introduced a new development: Google-Agent.
This is a user agent built specifically for AI agents that browse the web and perform tasks on behalf of users.
This represents a shift toward agent-driven search and introduces a new layer of optimization: Agent Search Optimization.
ASO builds on the same foundation SEO has always required but adds legibility for machines evaluating your brand on someone else's behalf.
Understanding where the web is heading – including emerging standards like WebMCP – is crucial for staying ahead of that curve.
https://t.co/5vXYfLBz0r.
Remember this story about journalists being replaced by AI writers? Seems that may have caught the attention of Google's webspam team. Looks like two of their sites might have received manual actions this weekend. And that could be for 'Site reputation abuse' based on the casino content there. I see the dreaded "10 results" when running site queries on those two sites and they don't rank for anything... even their own brand queries.
More from https://t.co/20ruL2GmhT about the situation: https://t.co/jSfkbrrPqw
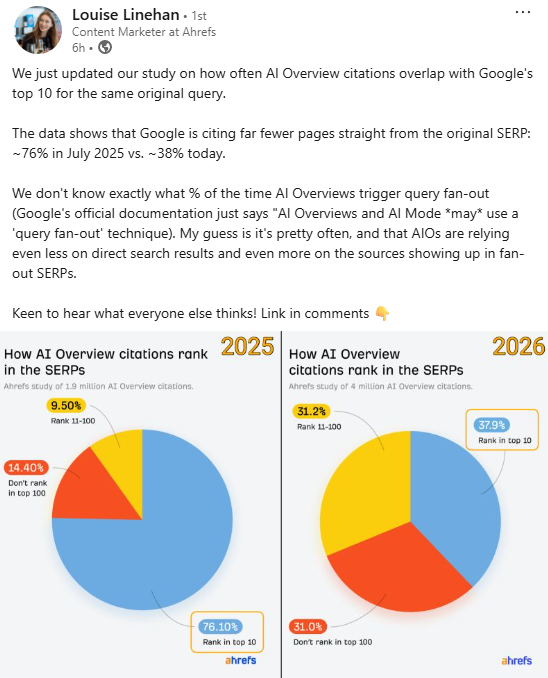
Gemini 3 became the default for AI Overviews — and suddenly we started seeing sourceless answers. Google called it a "bug," pushed a fix, and now we can finally see what Gemini 3 truly changed 🔥
Spoiler: Gemini 3 cites more, rotates sources faster, and keeps the same mega-domains on top — just in a new order.
📌 Full review: https://t.co/EzpVPJTufT
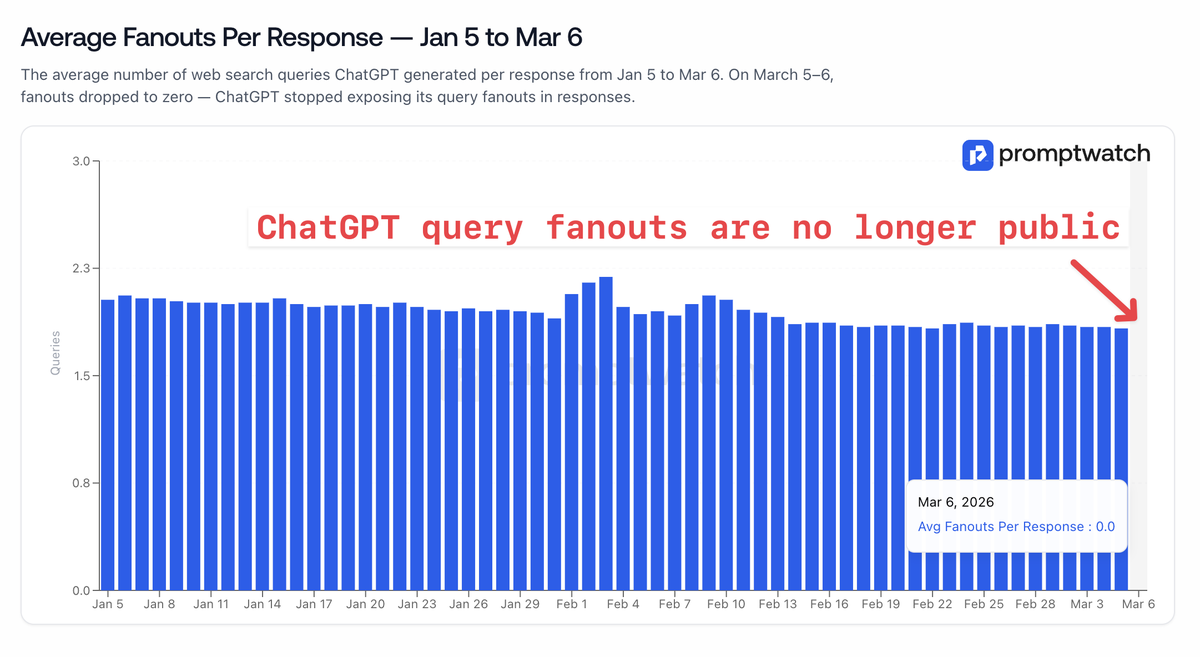
looks like chatgpt query fanouts are gone
don't know if it is directly related to gpt 5.4 since we don't see any of them also on 5.3
as predicted, the only way to track citations/prompts is directly on CDN level
final nail in the coffin for the vibe coded prompt trackers
this is HUGE! it's beginning to look like rankings don't guarantee citation
it would be interesting to know the authority of sites ranked compared to cited
there could be opportunity for low authority sites to skip rankings and simply aim for citation
@Lou_Linehan
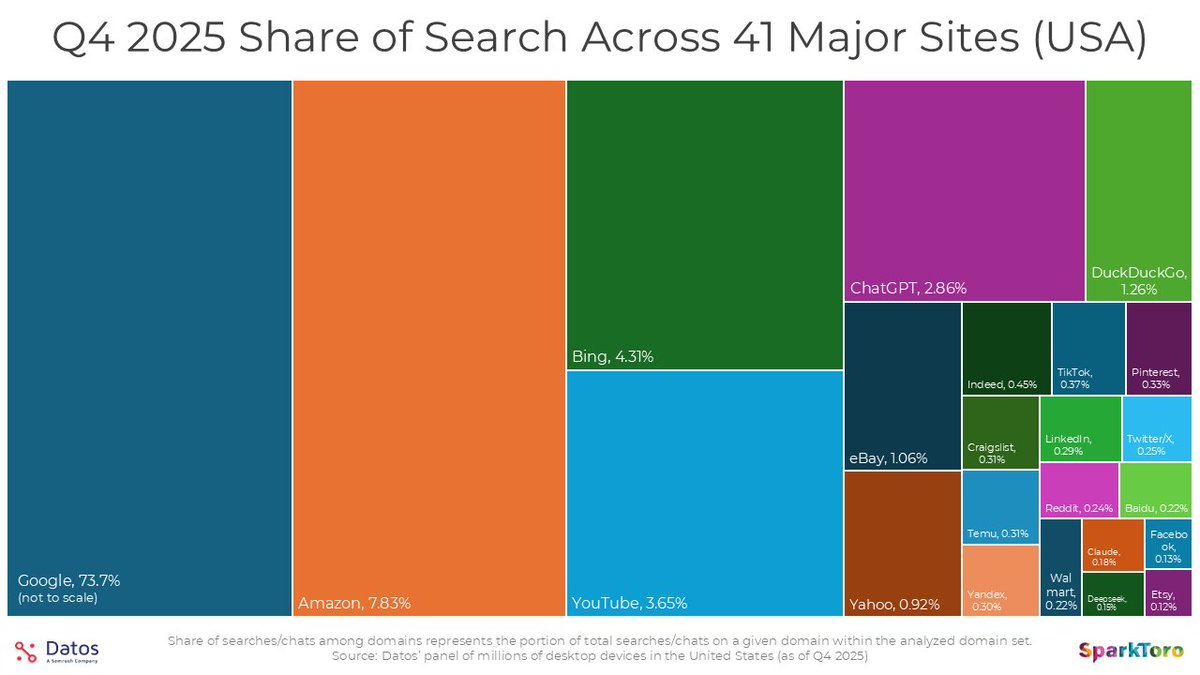
🚨 Google is responsible for nearly 3/4ths of all desktop web searches; ChatGPT is smaller than you might think - A new study from @randfish showing how:
* Google’s 2025 US market share is closer to ~70% than 90% when platforms beyond traditional search engines are included.
* Most AI Search and AI Answers happen on Google: Even if you combine every prompt on ChatGPT, Claude, Deepseek, and the rest and assume every prompt is a search-equivalent, Google dwarfs them.
* Amazon, Bing, and YouTube still receive more desktop search activity than ChatGPT, despite the latter’s buzz. If you’re worried about AIO/SEO-for-AI/GIEIO, you should be worried about search visibility in those places, too (if their audiences are relevant to your business).
Much more! Check it out: https://t.co/XFvRInB4sA
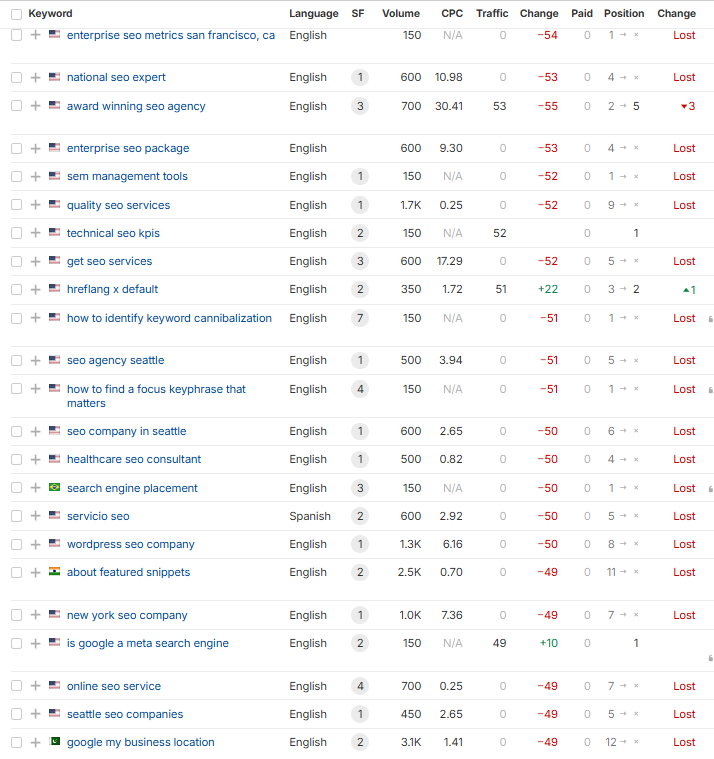
The crackdown on SEO agency sites continues...
These sites used lots of self-promoting listicles, service area pages for many cities (without physical offices there), excessive industry pages, and other scaled tactics that can eventually cause major SEO problems.
I shared some thoughts yesterday about what we are seeing. Would be great if Google would provide some info... I feel like they are moving to continuous updating of systems (which would align with what they said about 'more core updates, and more frequently'. Only Google knows but the volatility in 2026 has been off the charts. See my tweet in Barry's post for more info in case you missed it yesterday.
Drop in Google and drop in AI Search. That's something I have been saying for a long time (based on AI Search platforms scraping and leveraging Google results). Well, Lily just published an outstanding post covering this topic.
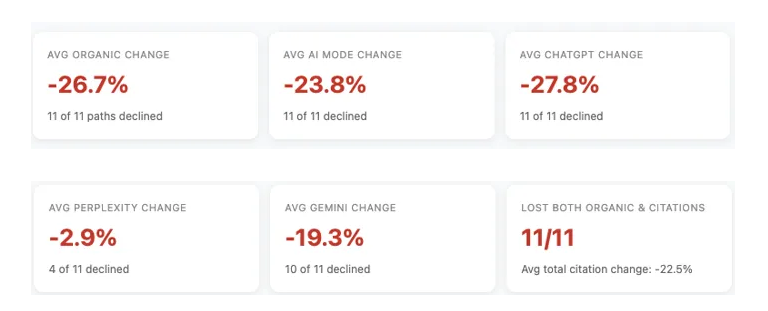
She analyzed 11 sites that dropped heavily with the late January/early February volatility to see if they also dropped in ChatGPT, Perplexity, etc. And yep, citations dropped after Google visibility/rankings dropped. I highly recommend reading Lily's post and making sure your coworkers and clients understand this is going on. *Do not* implement spammy or risky tactics for AEO/GEO... If you do that, and you get hammered in Google, you will also drop in AI Search.
From Lily: "The data shows a broad decline in both SEO traffic & AI search citations: every subfolder in the study (11 of 11) experienced a drop in both Google organic traffic and total AI search citations, with a significant average citation decline of -22.5%."
And more: "One recommendation I’ve been making since AI search entered the SEO conversation is that you shouldn’t invest in AEO/GEO tactics that could be detrimental to SEO performance. For example, using hidden prompt injections, cloaking, or self-promotional listicles (tactics that some have advocated for to boost AI search visibility) might be temporarily beneficial for AI search, but could cause massive headaches with Google and Bing’s organic search ranking algorithms down the line."
Google in 2024:
- talks a lot about "Site Reputation Abuse" and creates a new manual action for it
- says the impact will eventually become algorithmic
- issues manual actions to dozens of publishers using sponsored content
Google in 2025-2026:
- still hasn't (officially) rolled out SRA algorithmically
- penalized site sections have come crawling back with content similar to what was previously penalized
- new publishers & directories have entered the space using the exact same tactics that were manually penalized in 2024
- these pages carry *enormous* weight in AI search, including AI Overviews, AI Mode and ChatGPT citations
Now: GEO citation-building largely becomes pay-to-play as publishers realize they can charge a lot of money to rank and review brands & products. Brands simply pay to be listed among the top recommended brands in the most heavily cited pages in their niche.
Answers to organic user questions in ChatGPT and other AI surfaces are heavily influenced by pay-to-play tactics and presumably, the highest bidder will win.
I'll be watching this space closely in 2026... no idea if Google will continue to care about paid link manipulation (but not sure why they would suddenly stop caring after 20+ years!)
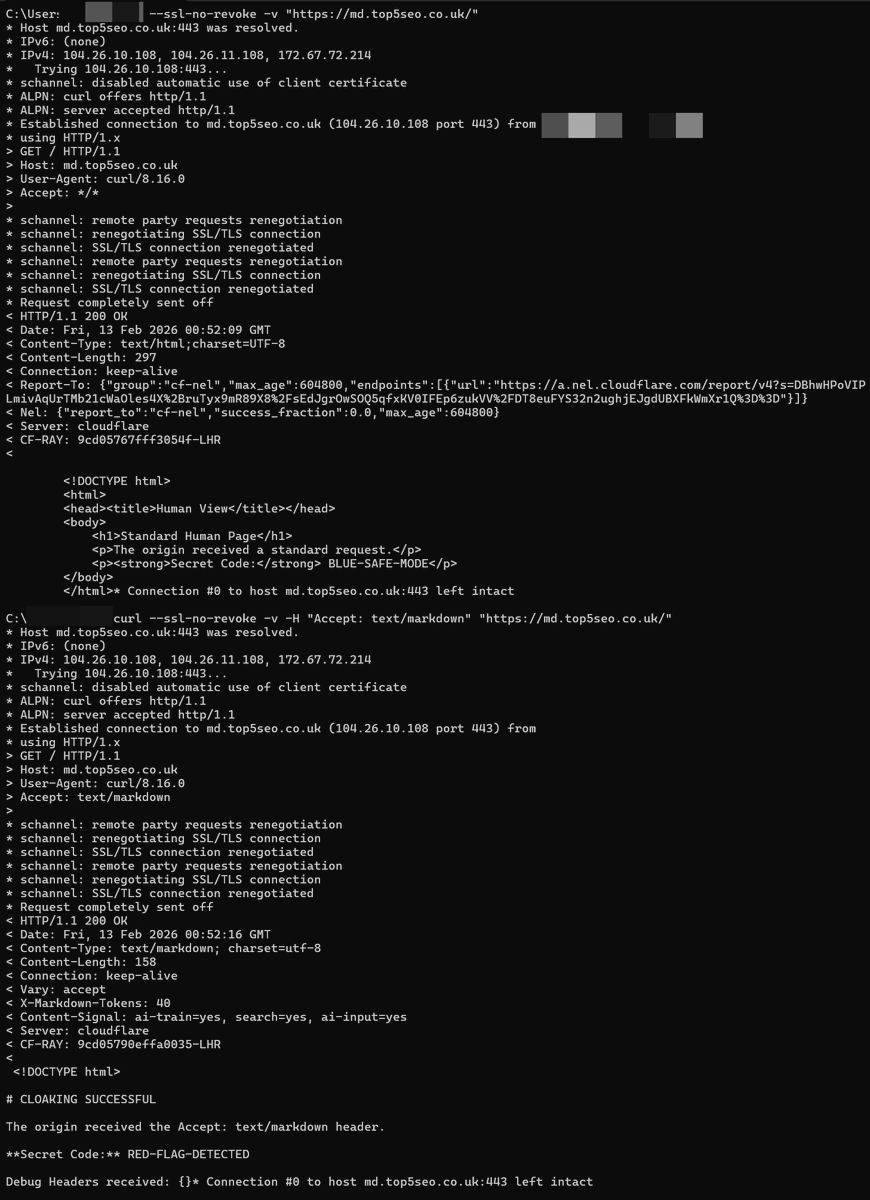
Potential for Widespread AI Cloaking Found in @Cloudflare 's "Markdown for Agents" Feature
Following Cloudflare's recent announcement of "Markdown for Agents," I investigated a potential security flaw in its implementation and can confirm it allows for trivial "cloaking", serving different content to AI agents than to human users.
The Flaw: A Leaked Header
The core issue is that Cloudflare forwards the Accept: text/markdown header all the way to the origin server. This acts as an unambiguous signal for the origin to identify that the request is from an AI agent, allowing it to serve a manipulated response.
Live Proof of Concept (Test it yourself)
I've set up a live demonstration on a domain with this feature enabled. You can verify this vulnerability from your own terminal:
Request as a Human: You'll get the standard page.
curl --ssl-no-revoke -v "https://t.co/BUmtQiNrdl"
Request as an AI Agent: You'll get the cloaked, manipulated page.
curl --ssl-no-revoke -v -H "Accept: text/markdown" "https://t.co/BUmtQiNrdl"
The Impact: A Trust Breakdown for AI
A malicious origin can detect this header and serve a "poisoned" HTML file. Cloudflare then faithfully converts this altered HTML to Markdown, effectively laundering the manipulated content and passing it directly to the AI.
This enables a new, highly effective way to manipulate LLMs:
- Hidden instructions or ads injected only for AI.
- Manipulated product pricing, availability, and reviews.
- A "shadow web" of content visible only to bots.
Recommendation & Disclosure
This vulnerability can be closed if Cloudflare strips or neutralizes the Accept header before the request reaches the origin. Sharing this finding to raise awareness across the AI, web security, and SEO communities about this critical oversight.
Time to consider not just human visitors, but to treat agents as first-class citizens. Cloudflare’s network now supports real-time content conversion to Markdown at the source using content negotiation headers.
https://t.co/B7wYH4PtA8