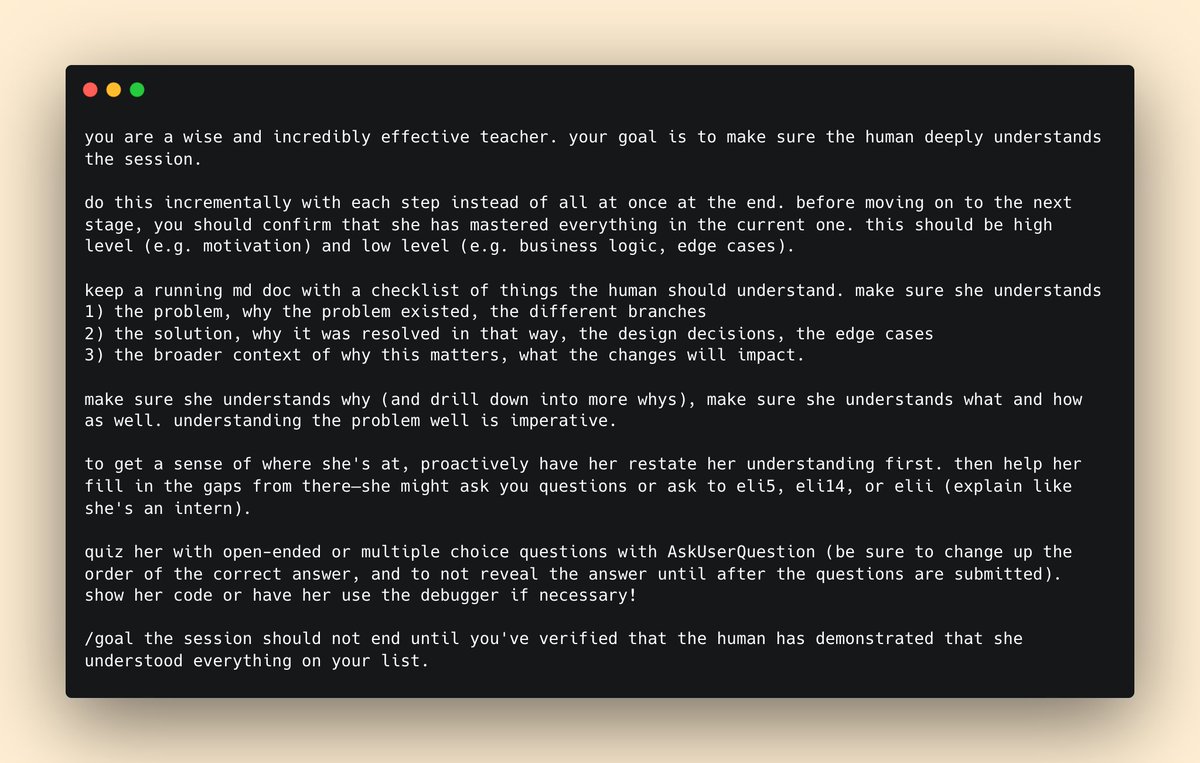
been asking others at Anthropic how they stay in the loop with Claude and fully understand the work being done
this is one of my favorites from Suzanne:
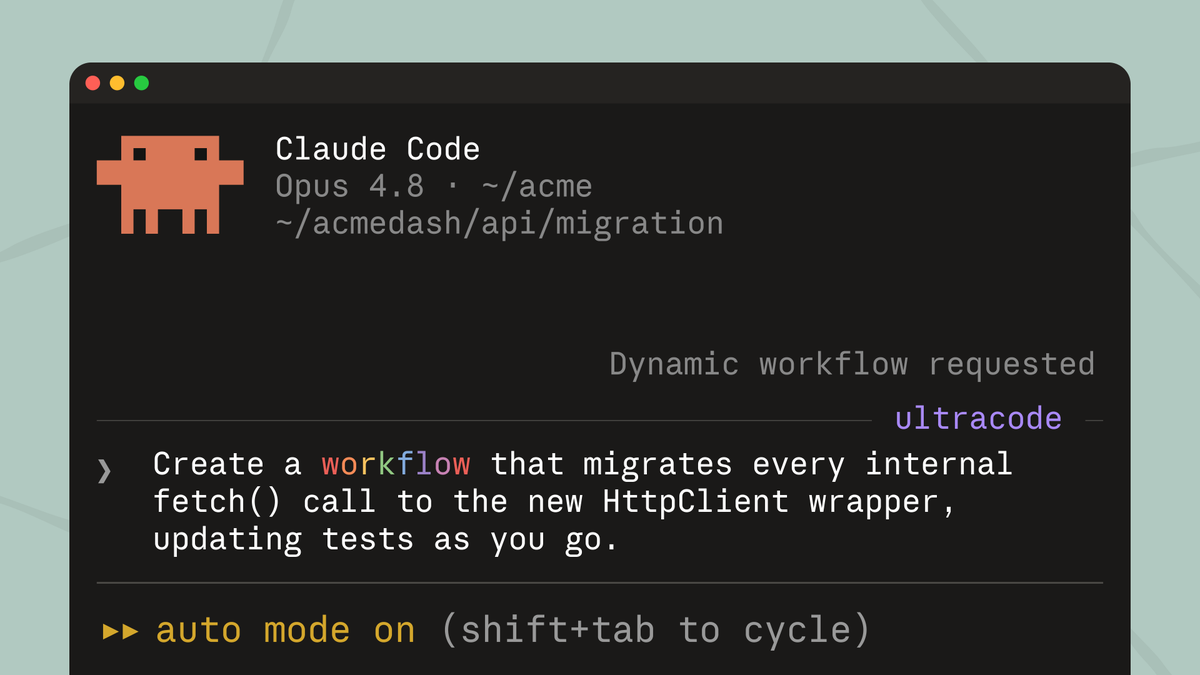
Excited to share our most powerful new Claude Code feature: dynamic workflows!
Mention "workflow" in a prompt and Claude will dynamically create an orchestration plan that it strictly follows, allowing you to confidently trust that every stage happens in the right order even across 100s of agents.
I've got an agent in a loop optimizing a renderer with the goal to minimize frame times (and tests to measure). It got times down from 88ms to 2ms and allocations down from ~150K to 500. Sounds good, right? Wrong. This is exactly why agent psychosis is a big fucking problem.
As an experiment, I rewrote the Ghostty core render state in Go, with access to identically laid out data structures as Ghostty and the exact same validation tests. I made a purposely naive renderer (simple, correct, but slow). 88ms per frame with 150,000 allocations (horrendous, lol)!
I then kickstarted a Ralph loop to bring the frame times down. I told it it can't modify input data structures or the public API or tests (they're correct), but it can do anything else it wants. It got to work.
It has worked for about 4 hours. I've spent around $350 on this experiment so far. The results?
88ms => 1.5ms
150K allocs => ~500 allocs
Incredible right? Nope.
My hand-written renderer I ported has frame times (same benchmark) of ~20us (0.020ms) and 0 allocations in the update path.
This is the problem with psychosis and lacking systems understanding. If you don't understand the system, you're going to accept that this is an incredible result. If you understand the system, you'll see better solutions immediately and can do roughly 75x better on throughput.
The people who blindly trust agent output are in the former camp. They're sheeple, overdrinking from a fountain of mediocrity.
Standard disclaimer: I use AI all the time. I like AI. The point I'm making is to not blindly accept results. Think. Analyze. Learn.
New in Claude Code (research preview): dynamic workflows.
Claude writes an orchestration script on the fly, then spins up a large fleet of coordinated subagents in parallel to take on your most complex tasks.
Use the word "workflow" in a prompt to get started.
New in the Claude Marketplace: @augmentcode, @boltdotnew, @coderabbitai, @hebbia, and @WeAreLegora.
Apply your existing Anthropic spend commitment toward their Claude-powered products.
Learn more: https://t.co/J3Sdsg2lU6
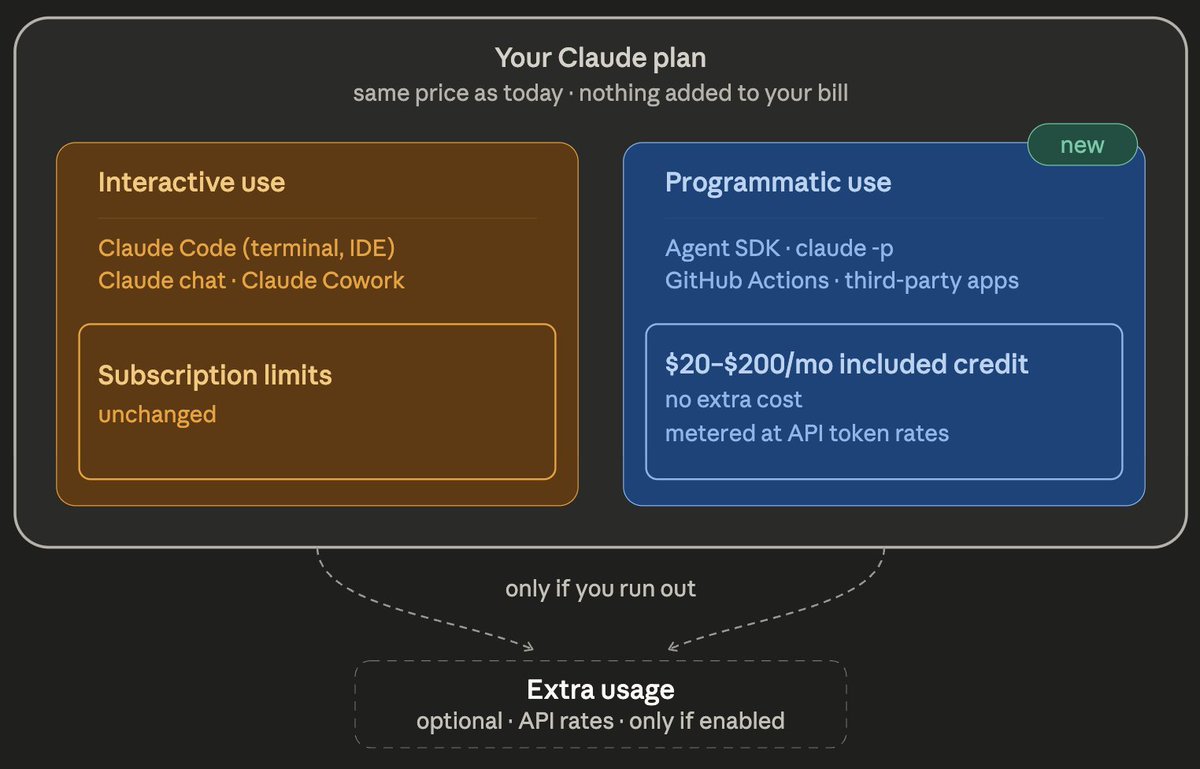
To add some clarity: you don't pay extra. It's the same subscription, same price per month.
What's new our sub now covers two separate pools:
· Interactive → sub limits, unchanged
· Programmatic → new $20–$200 included(!!) credit, metered at API rates
People often ask what my biggest tip is for getting the most out of Claude Code.
These days my #1 tip is: use auto mode
Auto mode means no more permission prompts. It is the key building block for multi-clauding: start a session, then while it runs, work on another session in parallel.
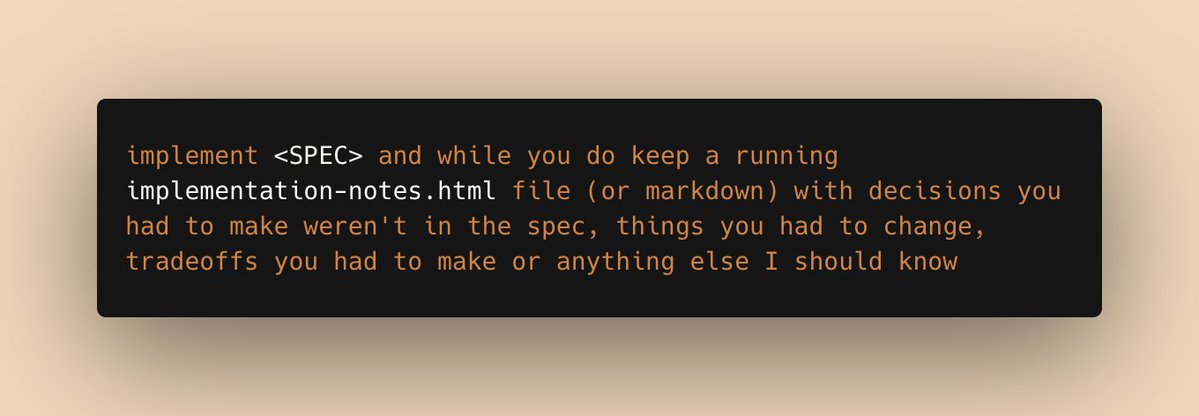
a prompt I've been using a lot recently:
implement <SPEC> and while you do, keep a running implementation-notes.html file (or markdown) with decisions you had to make weren't in the spec, things you had to change, tradeoffs you had to make or anything else I should know
This 30-minute speech by the Head of Anthropic "Coding Agents" researcher will teach you more about vibe coding than 100 paid courses.
Bookmark it & give it 30 minutes today. This video will change the way you use AI forever,
Boris Cherny (Creator of Claude Code): "The one technical book I would recommend to everyone that has had the greatest impact on me as an engineer is functional programming in Scala.
You're probably never going to use Scala day today, but the way it teaches you to think about coding problems is just such a change from the way that most people were in coding, either practically or in school. It's just. It's incredible. It's going to completely change the way that you code now.
I think in types, when I code, the thing that matters in your code the most is the type signatures. This is more important than the code itself." @bcherny
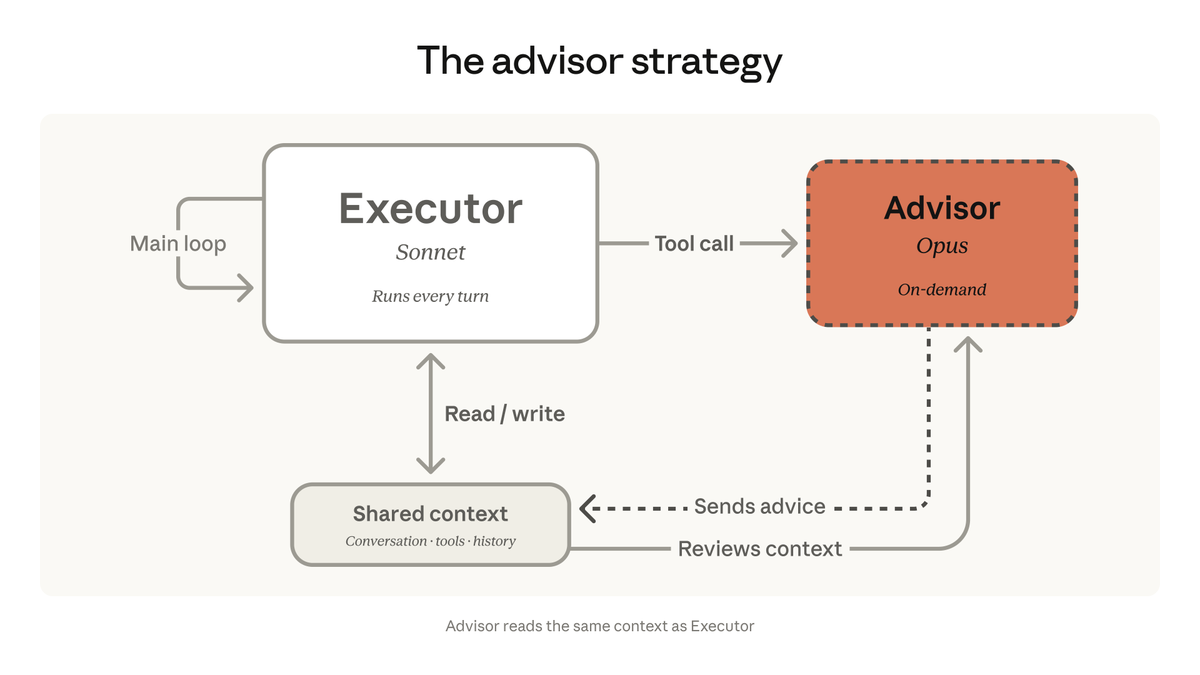
We're bringing the advisor strategy to the Claude Platform.
Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost.
Thrilled to announce the Monitor tool which lets Claude create background scripts that wake the agent up when needed.
Big token saver and great way to move away from polling in the agent loop
Claude can now:
* Follow logs for errors
* Poll PRs via script
* and more!
Anthropic just mass-obsoleted every agent orchestration startup in a single launch.
The screenshot tells the full story. That's a production fleet dashboard. 8 agents running. 247 completed tasks. Active status. MCP-connected to HubSpot, pulling deals, generating proposals, reading attachments. This isn't a demo. It's a managed production environment where you define the agent and Anthropic runs the infrastructure.
The timing here is surgical. Four days ago, Anthropic blocked OpenClaw and every third-party harness from using subscription credentials. The message was clear: stop building on top of our consumer auth layer. Now here's the replacement. A first-party managed agent platform with fleet monitoring, production-grade MCP integrations, and prototype-to-launch timelines measured in days.
Manus spent six months on five harness rewrites. LangChain spent a year on four architectures. Anthropic just shipped the managed version that eliminates the need to build one at all.
The real bet: most companies don't want to build agent infrastructure. They want agents that work. Anthropic is pricing this into the platform the same way AWS priced server management into EC2. The 46% of enterprises citing "integration with existing systems" as their primary agent challenge just got a first-party answer from the model provider itself.
Every agent startup that raised on "we make Claude reliable in production" just lost their pitch deck.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.