🚀 Unlock the Full Potential of Your Applications with OpenShift Consulting! 🚀
At CloudSpinx, our OpenShift Consulting services are designed to empower your business with top-tier container orchestration and management:
🛠️ Seamless Deployment
⚙️ Custom Solutions
🌟 Scalability and Flexibility
🔄 CI/CD Integration
🛡️ Robust Security
Experience the benefits of advanced container orchestration with OpenShift! 🌐 #OpenShift #CloudSpinx #ContainerManagement #ITConsulting #CloudSolutions Learn more at https://t.co/dCcQtQZCve
We are please to announce our final release of 2024, Kali Linux 2024.4!
https://t.co/YGwhA8RhcX
Containing new default python, updates to gnome 47, our launch of the new forums, raspberry pi imager improvements, nethunter updates and more! Check it out!
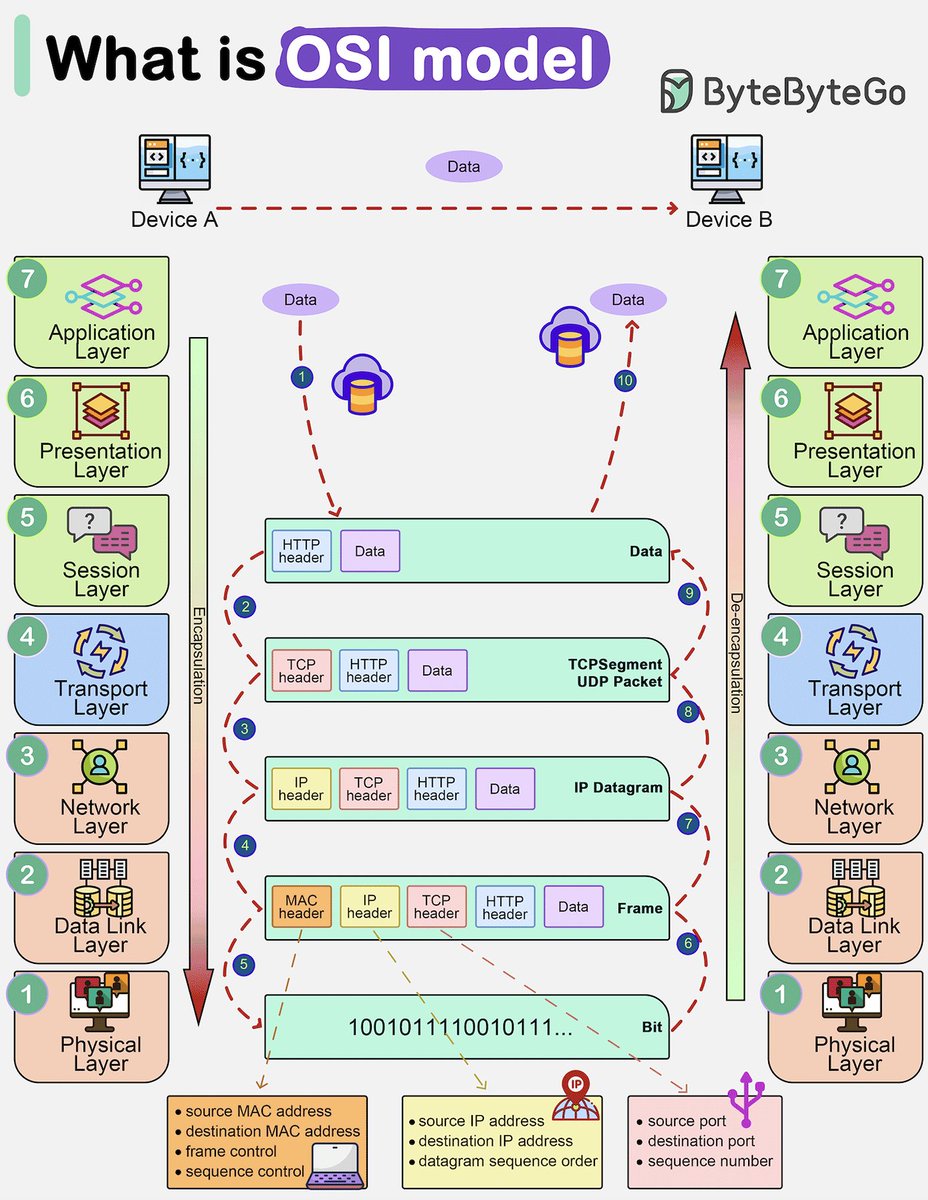
How is data sent over the network? Why do we need so many layers in the OSI model?
The diagram below shows how data is encapsulated and de-encapsulated when transmitting over the network.
🔹 Step 1: When Device A sends data to Device B over the network via the HTTP protocol, it is first added an HTTP header at the application layer.
🔹 Step 2: Then a TCP or a UDP header is added to the data. It is encapsulated into TCP segments at the transport layer. The header contains the source port, destination port, and sequence number.
🔹 Step 3: The segments are then encapsulated with an IP header at the network layer. The IP header contains the source/destination IP addresses.
🔹 Step 4: The IP datagram is added a MAC header at the data link layer, with source/destination MAC addresses.
🔹 Step 5: The encapsulated frames are sent to the physical layer and sent over the network in binary bits.
🔹 Steps 6-10: When Device B receives the bits from the network, it performs the de-encapsulation process, which is a reverse processing of the encapsulation process. The headers are removed layer by layer, and eventually, Device B can read the data.
We need layers in the network model because each layer focuses on its own responsibilities. Each layer can rely on the headers for processing instructions and does not need to know the meaning of the data from the last layer.
Over to you: Do you know which layer is responsible for resending lost data?
--
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): https://t.co/eVEdOFSYPY
🎉 Leap Micro 6.1 is here! 🚀 With features like #TOTP for PAM, soft-reboot support & opensuse-migration-tool, it's time to upgrade! https://t.co/31FZdkAbat
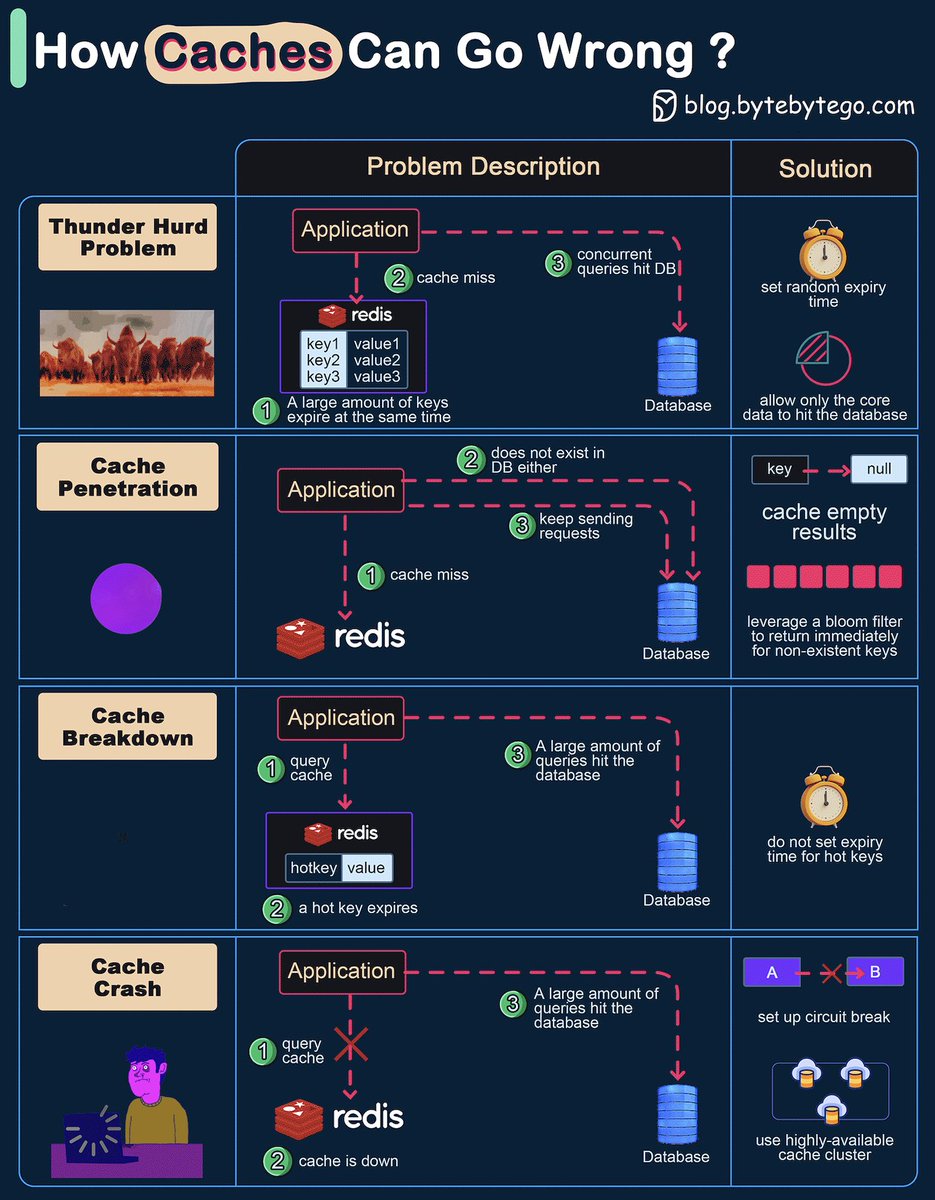
How can Cache Systems go wrong?
The diagram below shows 4 typical cases where caches can go wrong and their solutions.
1. Thunder herd problem
This happens when a large number of keys in the cache expire at the same time. Then the query requests directly hit the database, which overloads the database.
There are two ways to mitigate this issue: one is to avoid setting the same expiry time for the keys, adding a random number in the configuration; the other is to allow only the core business data to hit the database and prevent non-core data to access the database until the cache is back up.
2. Cache penetration
This happens when the key doesn’t exist in the cache or the database. The application cannot retrieve relevant data from the database to update the cache. This problem creates a lot of pressure on both the cache and the database.
To solve this, there are two suggestions. One is to cache a null value for non-existent keys, avoiding hitting the database. The other is to use a bloom filter to check the key existence first, and if the key doesn’t exist, we can avoid hitting the database.
3. Cache breakdown
This is similar to the thunder herd problem. It happens when a hot key expires. A large number of requests hit the database.
Since the hot keys take up 80% of the queries, we do not set an expiration time for them.
4. Cache crash
This happens when the cache is down and all the requests go to the database.
There are two ways to solve this problem. One is to set up a circuit breaker, and when the cache is down, the application services cannot visit the cache or the database. The other is to set up a cluster for the cache to improve cache availability.
Over to you: Have you met any of these issues in production?
--
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): https://t.co/eVEdOFSYPY