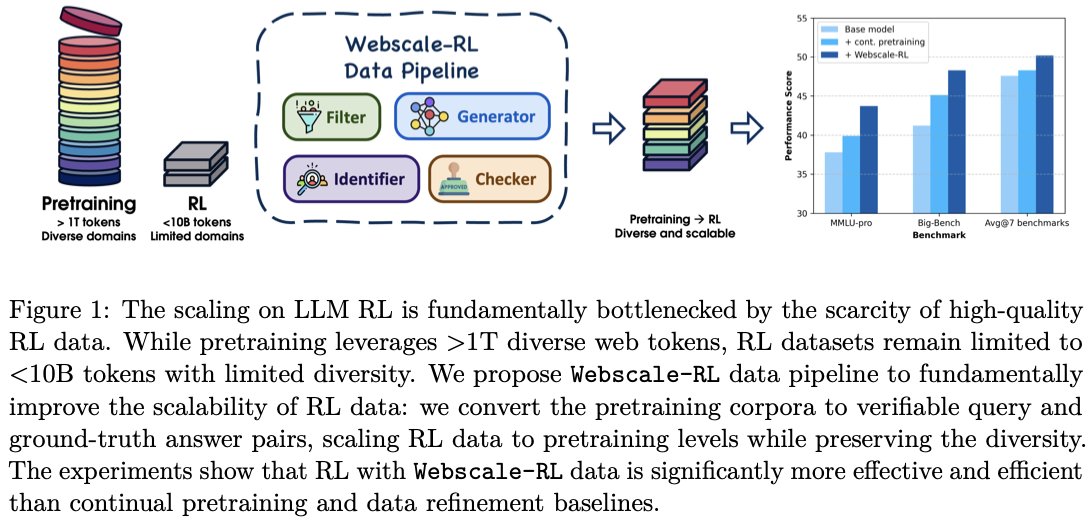
📣 Webscale-RL: Automated Data Pipeline for Scaling RL Data to Pretraining Levels 📣
RL for LLMs faces a critical data bottleneck: existing RL datasets are <10B tokens while pretraining uses >1T tokens. Our Webscale-RL pipeline solves this by automatically converting pretraining documents into 1.2M verifiable QA pairs across 9+ domains.
📄 Paper: https://t.co/GPWXO1GCQU
💻 Code: https://t.co/T2GcHlMrXC
📊 Dataset: https://t.co/ADDMhd6S3e
Results: 100× more token-efficient than continual pretraining with significant performance gains on MMLU-pro, BigBench, and mathematical reasoning benchmarks 📈
Work by Zhepeng Cen (@zhepengcen), Haolin Chen (@HaolinChen11), Shiyu Wang (@shiyu04490786), Zuxin Liu (@LiuZuxin), Zhiwei Liu, Ding Zhao, Silvio Savarese, Caiming Xiong (@CaimingXiong), Huan Wang (@huan__wang), Weiran Yao (@iscreamnearby)
#FutureOfAI #EnterpriseAI #ReinforcementLearning #MachineLearning
Struggling with RL fine-tuning for LLMs? Our most recent paper nails the issue: it’s not just about accuracy distribution, it’s about how coherent and influential your rollouts are! BRIDGE proposes a clever fix 👇
🚀 Introducing BRIDGE — a task-agnostic data augmentation strategy to prepare LLMs for RL!
🤖 Why do LLMs often fail to benefit from RL fine-tuning? We pinpoint two key factors: 1) 🔍 Rollout Accuracy 2) 🔗 Data Co-Influence. 💡 BRIDGE injects both exploration & exploitation into LLMs, boosting rollout informativeness and increasing data co-influence — key ingredients for effective RL fine-tuning.
🔍 We also compare with a popular accuracy-filtering baseline — it still plateaus due to low data co-influence. TL;DR: medium query difficulty / accuracy ≠ RL-ready.
📄 Paper: https://t.co/98Xb9nmAOL
🌐 Website: https://t.co/YTieEjXA0G
🚀 Introducing BRIDGE — a task-agnostic data augmentation strategy to prepare LLMs for RL!
🤖 Why do LLMs often fail to benefit from RL fine-tuning? We pinpoint two key factors: 1) 🔍 Rollout Accuracy 2) 🔗 Data Co-Influence. 💡 BRIDGE injects both exploration & exploitation into LLMs, boosting rollout informativeness and increasing data co-influence — key ingredients for effective RL fine-tuning.
🔍 We also compare with a popular accuracy-filtering baseline — it still plateaus due to low data co-influence. TL;DR: medium query difficulty / accuracy ≠ RL-ready.
📄 Paper: https://t.co/98Xb9nmAOL
🌐 Website: https://t.co/YTieEjXA0G
🤖 What if robots could adapt from simulation to reality on the fly, mastering tasks like scooping objects and playing table air hockey? 🥄🏓
I’m thrilled to share that our work, "Dynamics as Prompts: In-Context Learning for Sim-to-Real System Identification," has been accepted for publication in #IEEE Robotics and Automation Letters! 🎉
👇👇👇
https://t.co/LoUffR2ccB
🔍 Inference-time scaling is a key focus in foundation models, but its origins trace back to model-based RL (MBRL). In MBRL, a critical challenge arises from reconciling the conflict between "world model prediction" and "task reward"—the gap between next-state prediction accuracy and full sequence (user-defined) reward optimization.
🔨 Our NeurIPS paper, BECAUSE, pinpoints the root of this mismatch: spurious correlations in empirical transition dynamics and data policy. To address this, we propose a bilinear causal representation that bridges the gap, enabling generalizable imagination rollouts, robust uncertainty quantification, and pessimistic planning.
📈 BECAUSE achieves state-of-the-art performance, outperforming existing offline RL baselines in generalizable online deployment, with good theoretical guarantees.
🌐 Learn more: https://t.co/HvtGqsYJKW
(1/6)
#NeurIPS2024 #NeurIPS
🔍 Inference-time scaling is a key focus in foundation models, but its origins trace back to model-based RL (MBRL). In MBRL, a critical challenge arises from reconciling the conflict between "world model prediction" and "task reward"—the gap between next-state prediction accuracy and full sequence (user-defined) reward optimization.
🔨 Our NeurIPS paper, BECAUSE, pinpoints the root of this mismatch: spurious correlations in empirical transition dynamics and data policy. To address this, we propose a bilinear causal representation that bridges the gap, enabling generalizable imagination rollouts, robust uncertainty quantification, and pessimistic planning.
📈 BECAUSE achieves state-of-the-art performance, outperforming existing offline RL baselines in generalizable online deployment, with good theoretical guarantees.
🌐 Learn more: https://t.co/HvtGqsYJKW
(1/6)
#NeurIPS2024 #NeurIPS
🏝️ OASIS: Shaping the Future of Offline Safe Reinforcement Learning
🚀 Our recent NeurIPS 2024 paper tackles the challenges in Offline Safe Reinforcement Learning with a data-centric perspective that improves training dataset quality for safer and more effective policies.
#neurips2024 #Oasis #safety #ReinforcementLearning #Datacuration
✨ Key Contributions:
💡Data-Centric Approach: Focuses on knowledge distillation and data augmentation to enhance dataset quality, rather than solely proposing new model-centric algorithms for sequential modeling and policy optimization.
💡Distribution Shaping: Leverages a conditional diffusion model to curate datasets and align training data with user-defined safety preferences.
💡Theoretical Insights: Provides a comprehensive theoretical analysis of how behavior policy and offline dataset quality affect the performance of regularization-based offline (safe) RL.
💡"Less is More" for Offline Safe RL: Demonstrates that a small, preference-aligned, high-quality dataset can outperform a massive dataset with mixed quality and preferences.
💡Broad Compatibility: Integrates seamlessly with model-centric algorithms.
🔗 Project website: https://t.co/Qv1S4nwwGN
📄 Paper: https://t.co/wd0BpbVdBe
🐙 Code: https://t.co/yBabEVPwyI
What a pity to miss a wonderful in-person IROS conference! Don’t forget to check our RAL paper: https://t.co/VgxgqvK4kH and our project page!
Code base: https://t.co/RhDgzKzG0s
Project page: https://t.co/t3VwusoF3M
LocoMan
= Quadrupedal Robot + 2 * Loco-Manipulator
Powered by dual lightweight 3-DoF Loco-Manipulators and the Whole-Body Controller, LocoMan achieves various challenging tasks, such as manipulation in narrow spaces and bimanual-manipulation.
https://t.co/EDPGUxq1sT
👇👇👇
How can we enhance the reasoning capabilities for RL agents? We present FUSION, a causality-guided trustworthy reinforcement learning framework that can achieve satisfactory performance in safety-critical domains like autonomous vehicle agents under distribution shift. #ML4AD
Excited to return to Atlanta for #CoRL2023@corl_conf
after almost 2 years! I'll be presenting "COMPOSER: Scalable and Robust Modular Policies for Snake Robots" at the L4SR workshop's poster sessions. Please check out!
📄🔗: https://t.co/ELGpBgEDJC
🌐🔗: https://t.co/3ns1C8IaWH
#CoRL23 Nearly everyone in robot learning has dealt with simulators with inaccurate system dynamics, which hinders real-world deployments. Can we automate the process of aligning the simulator with the real world? @huang_peide and others gave an answer by proposing COMPASS🧭.
🤖What went wrong with my robot simulator? Why did my robot fail miserably in the real world? ☠️
You need COMPASS, a SysID method that automatically discovers the causality between the simulator parameters and the sim2real gap, and updates the parameters to reduce the gap.#CoRL
🚀 Don’t forget DSRL (Datasets for Safe RL)! 📷 With 38 datasets under safety constraint information and consistent API with D4RL, DSRL is your go-to for offline safe learning exploration and research. Check it out at https://t.co/KB3Zh1JWPM now!#Dataset#SafeRL#AISafety (4/4)
🚀 Excited to announce our latest research on #SafeRL, with three high-quality packages released! We introduce a benchmarking suite tailored for offline safe learning challenges. Explore more details at https://t.co/ZhUsTyd8Hc #AI#RL#AISafety (1/4)
🚀 Dive into OSRL (Offline Safe RL), a research-oriented and elegant repository that offers a wide array of offline safe learning algorithms. 📷 Feel free to modify it for your own research! Explore more at https://t.co/YYl50TwlwQ. 📷 #MLSafety#RL (3/4)