Is it just me, or did US frontier models get aggressively nerfed over the last 6 months? 📉
Feels like we transitioned from genuine raw intelligence to highly distilled, speed-optimized wrapper models. 🏃💨
@karpathy@MoonDevOnYT@RoundtableSpace here's the actual agent working — editing exit thresholds in real time, running backtests, iterating automatically 👇
everyone says autoresearch is for tuning LLMs
i'm using it to tune quant trading parameters
agent edits code → runs backtest → reads stats → decides what to change
LLMs are just one use case 🧵
built on @karpathy's autoresearch
quant AI inspo from @MoonDevOnYT
shoutout @RoundtableSpace for pushing AI x crypto
this is what AI-assisted algo research looks like
https://t.co/IIQ4O9gdAm
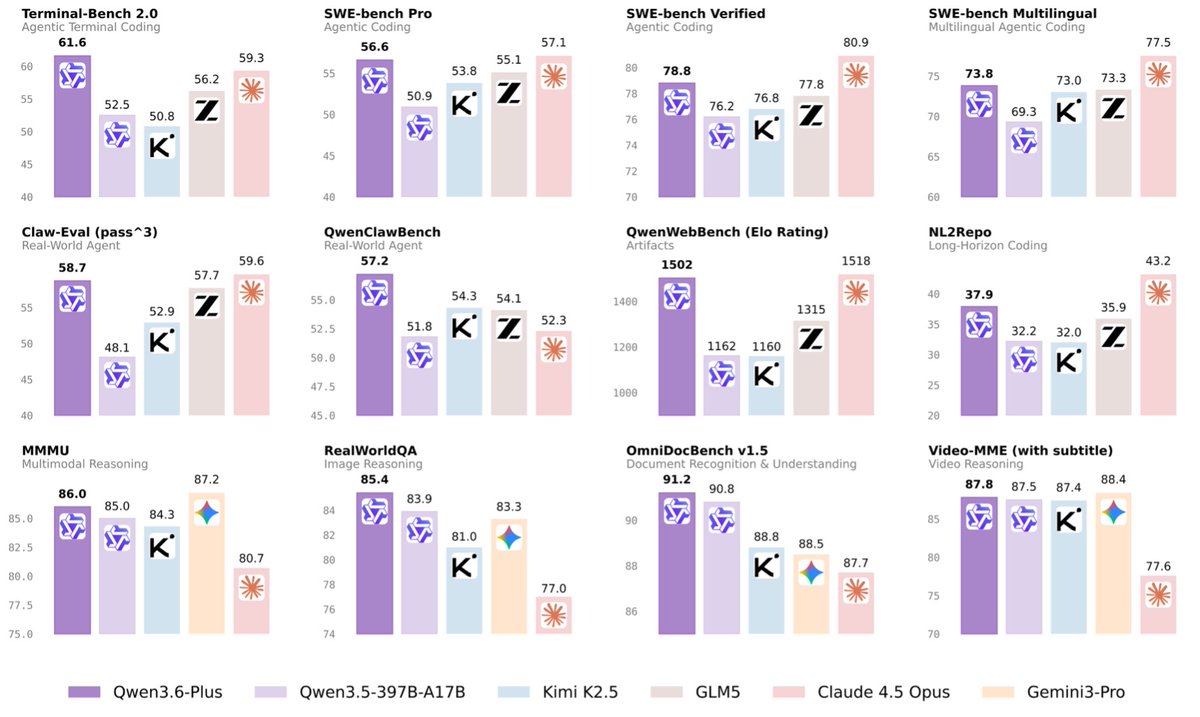
(1/8)🚀 Introducing Qwen3.6-Plus: Towards Real-World Agents! 🤖
Today, we’re thrilled to drop a major milestone in our journey toward native multimodal agents.
Here is what makes Qwen3.6-Plus a game-changer:
💻 Next-level Agentic Coding: Smarter, faster execution.
👁️ Enhanced Multimodal Vision: Sharper perception & reasoning.
🏆 Top-tier Performance: Maintaining leading general capabilities.
📚 1M Context Window: Available by default via our API.
Built on your invaluable feedback from the Qwen3.5 era, we’re laying a rock-solid foundation for real-world devs. Get ready to experience truly transformative ✨ Vibe Coding ✨.
Huge thanks to our community! Go try it out and show us what you can build. 👇
Chat: https://t.co/V7RmqMaVNZ
API: https://t.co/937Qkc9AMy
Blog: https://t.co/P0rJSxERND
🔔Noted:More Qwen3.6 models to come and be open-sourced! Stay tuned~ 👀#Qwen #AI #AgenticCoding #VibeCoding #Agents
just used the new /buddy function in Claude Code and got MYTHOS as my AI pair programmer 🤯🔥
"Regex matches everything except what you're searching for." 💀
this thing is UNREAL #ClaudeCode#AI@Anthropic@RoundtableSpace
This is the future of AI coding. Not using AI as a chatbot — using it as a full research & engineering team.
Claude Code Bridge makes it all possible 👇
🔗 https://t.co/QUbiTMQWCX
#ClaudeCode#AI#AIAgents#ClaudeCodeBridge#FutureOfCoding
Standing at the frontier.
3 AI workers running in parallel — all coordinated through a single tmux session.
This is what maxing out AI actually looks like 🧵
The results speak:
96.85% FOMC no-change — priced in, tracked live
Win rate improving 81.5% → 95.0% with confirmation signals
272KB research PDF compiled in seconds
Not vibes. Real outputs. Real numbers.
7 task categories. 6 adversarial pressure strategies. 5-turn conversations. Zero data contamination.
TrustBench is open-source — run it on any model in under 2 minutes 👇
https://t.co/d82zoX6UCX
@openrouter@deepseek_ai@Alibaba_Qwen@MiniMax_AI@XiaomiMiMo
Most LLM benchmarks ask if a model gets the right answer.
We ask if it keeps the right answer after being told it's wrong. Five times.
TrustBench is our open-source adversarial consistency benchmark — and here are the results across 4 frontier models 🧵